ForAug: Recombining Foregrounds and Backgrounds to Improve Vision Transformer Training with Bias Mitigation
作者: Tobias Christian Nauen, Brian Moser, Federico Raue, Stanislav Frolov, Andreas Dengel
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-03-12 (更新: 2025-11-27)
备注: v2: added DeiT, added ablation vs simple copy-paste
🔗 代码/项目: GITHUB
💡 一句话要点
ForAug:通过重组前景和背景,缓解偏差并提升Vision Transformer训练效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据增强 Vision Transformer 模型偏差 前景背景分离 鲁棒性 泛化能力 预训练模型
📋 核心要点
- ViT等模型依赖大量数据,且存在中心、大小等偏差,影响鲁棒性和泛化性。
- 提出ForAug数据增强方法,利用预训练模型分离并重组前景和背景,显式引入不变性。
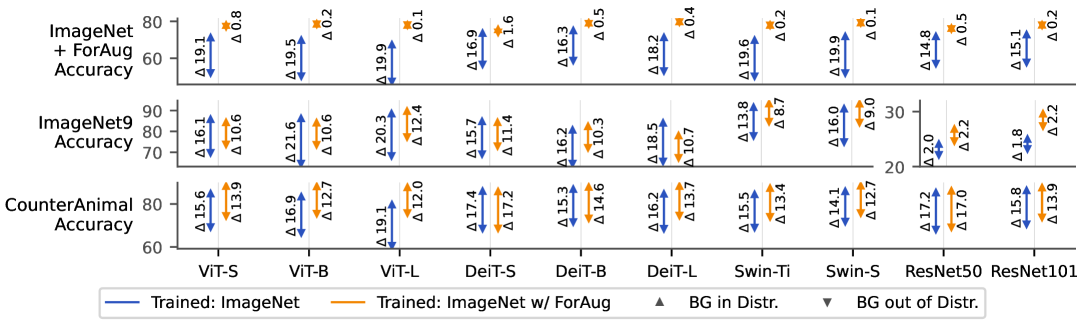
- 实验表明,ForAug显著提升ViT精度,在ImageNet上提升4.5%,下游任务提升7.3%,并有效降低模型偏差。
📝 摘要(中文)
Transformer,特别是Vision Transformer (ViT),在大规模图像分类中取得了最先进的性能。然而,它们通常需要大量数据,并且可能表现出偏差,例如中心或大小偏差,这限制了它们的鲁棒性和泛化能力。本文介绍了一种新的数据增强操作ForAug,通过显式地将不变性引入训练数据来解决这些挑战,而这些不变性原本是神经网络架构的一部分。ForAug通过使用预训练的基础模型来分离和重组前景对象与不同的背景来构建。这种重组步骤使我们能够对对象位置和大小以及背景选择进行细粒度控制。我们证明,使用ForAug可以显著提高ViT和其他架构的准确性,在ImageNet上高达4.5个百分点(p.p.),这转化为下游任务上的7.3个百分点。重要的是,ForAug不仅提高了准确性,而且开辟了分析模型行为和量化偏差的新方法。我们引入了背景鲁棒性、前景关注、中心偏差和大小偏差的指标,并表明在训练期间使用ForAug可以显著减少这些偏差。总而言之,ForAug为分析和缓解偏差提供了一个有价值的工具,从而能够开发更鲁棒和可靠的计算机视觉模型。我们的代码和数据集可在https://github.com/tobna/ForAug公开获取。
🔬 方法详解
问题定义:现有Vision Transformer模型在训练时容易受到数据集中存在的偏差的影响,例如物体在图像中倾向于位于中心位置或具有特定大小。这种偏差会导致模型在面对具有不同分布的数据时泛化能力下降。现有数据增强方法难以有效控制这些偏差,无法充分提升模型的鲁棒性。
核心思路:ForAug的核心思路是通过解耦图像中的前景对象和背景,然后将前景对象重新组合到不同的背景中,从而显式地控制训练数据的分布。通过这种方式,可以人为地引入或消除特定的偏差,例如中心偏差和大小偏差,从而迫使模型学习更加通用的特征表示。
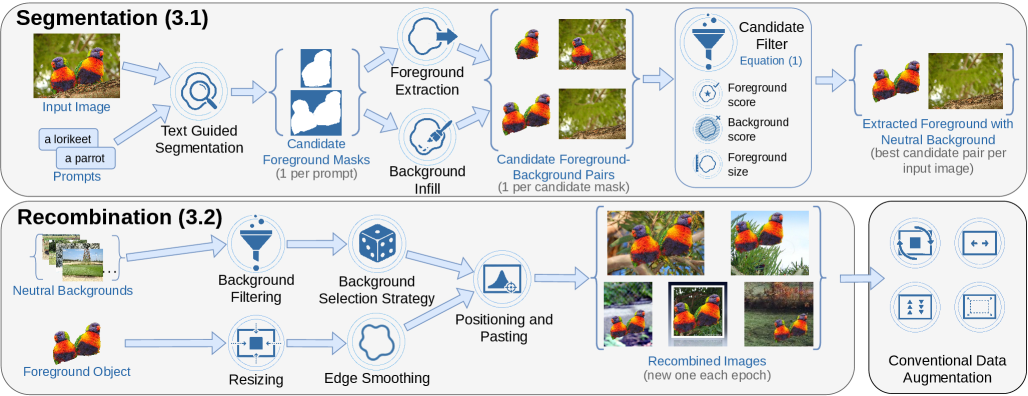
技术框架:ForAug主要包含以下几个步骤:1) 使用预训练的基础模型(例如,分割模型)将图像分解为前景对象和背景。2) 对前景对象进行变换,例如调整大小和位置。3) 从不同的图像中选择新的背景。4) 将变换后的前景对象与新的背景重新组合,生成新的训练图像。
关键创新:ForAug的关键创新在于它能够以细粒度的方式控制训练数据的分布,从而显式地缓解模型偏差。与传统的数据增强方法相比,ForAug不是简单地对图像进行随机变换,而是有目的地改变前景对象和背景之间的关系,从而迫使模型学习更加鲁棒的特征。
关键设计:ForAug的关键设计包括:1) 使用高质量的预训练分割模型来确保前景对象和背景的准确分离。2) 设计合理的变换策略,例如随机调整大小和位置,以增加训练数据的多样性。3) 引入背景选择策略,例如从不同的类别中选择背景,以增加模型的泛化能力。此外,论文还提出了用于量化模型偏差的指标,例如背景鲁棒性、前景关注、中心偏差和大小偏差。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ForAug在ImageNet数据集上将ViT模型的准确率提高了高达4.5个百分点,在下游任务上提高了7.3个百分点。此外,使用ForAug训练的模型在背景鲁棒性、前景关注、中心偏差和大小偏差等指标上均有显著改善。这些结果表明,ForAug不仅可以提高模型的准确率,还可以有效缓解模型偏差,提高模型的鲁棒性和泛化能力。
🎯 应用场景
ForAug可应用于各种计算机视觉任务,尤其是在数据分布存在偏差或数据量不足的情况下。例如,在自动驾驶领域,可以利用ForAug来增强对不同场景和光照条件下的物体识别能力。在医疗图像分析领域,可以利用ForAug来提高对罕见疾病的诊断准确率。此外,ForAug还可以用于分析和评估现有模型的偏差,从而指导模型改进。
📄 摘要(原文)
Transformers, particularly Vision Transformers (ViTs), have achieved state-of-the-art performance in large-scale image classification. However, they often require large amounts of data and can exhibit biases, such as center or size bias, that limit their robustness and generalizability. This paper introduces ForAug, a novel data augmentation operation that addresses these challenges by explicitly imposing invariances into the training data, which are otherwise part of the neural network architecture. ForAug is constructed by using pretrained foundation models to separate and recombine foreground objects with different backgrounds. This recombination step enables us to take fine-grained control over object position and size, as well as background selection. We demonstrate that using ForAug significantly improves the accuracy of ViTs and other architectures by up to 4.5 percentage points (p.p.) on ImageNet, which translates to 7.3 p.p. on downstream tasks. Importantly, ForAug not only improves accuracy but also opens new ways to analyze model behavior and quantify biases. Namely, we introduce metrics for background robustness, foreground focus, center bias, and size bias and show that using ForAug during training substantially reduces these biases. In summary, ForAug provides a valuable tool for analyzing and mitigating biases, enabling the development of more robust and reliable computer vision models. Our code and dataset are publicly available at https://github.com/tobna/ForAug.