Exo2Ego: Exocentric Knowledge Guided MLLM for Egocentric Video Understanding
作者: Haoyu Zhang, Qiaohui Chu, Meng Liu, Haoxiang Shi, Yaowei Wang, Liqiang Nie
分类: cs.CV
发布日期: 2025-03-12 (更新: 2025-12-16)
备注: This paper is accepted by AAAI 2026
💡 一句话要点
提出Exo2Ego,利用外视知识引导MLLM进行第一人称视角视频理解
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 内视视频理解 多模态大语言模型 知识迁移 外视视角 具身智能
📋 核心要点
- 现有MLLM主要关注外视视觉,忽略了内视视频的独特性和数据稀缺性带来的挑战。
- 论文提出学习外视到内视的知识迁移,利用外视MLLM的知识来提升内视视频理解能力。
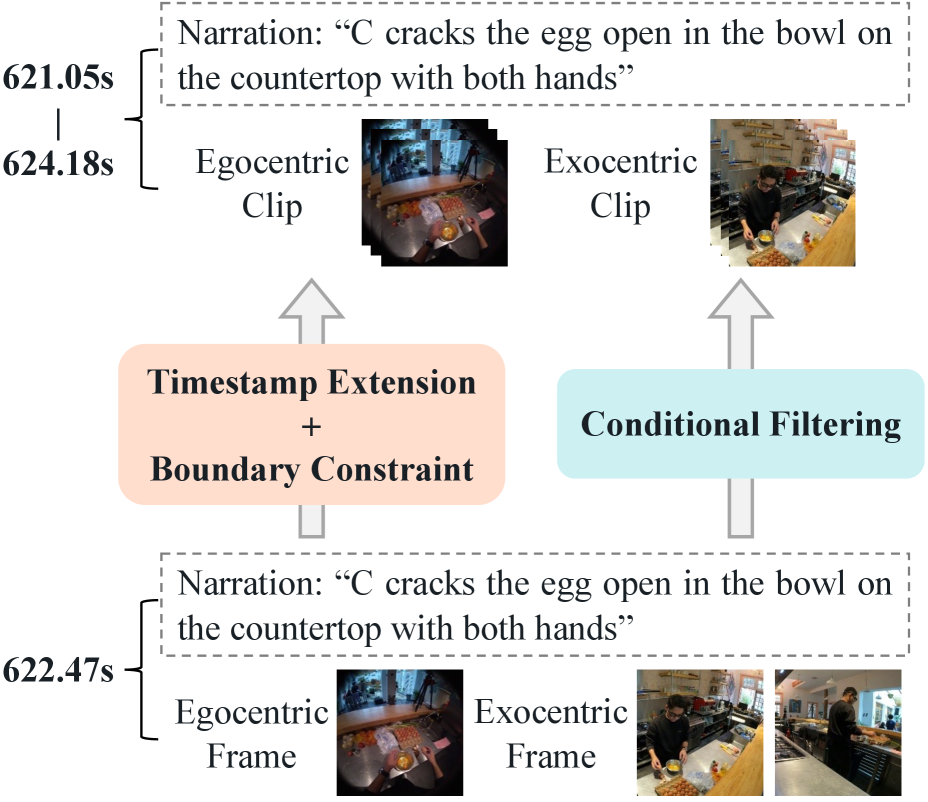
- 通过Ego-ExoClip和EgoIT数据集,以及渐进式映射学习,模型在内视任务上显著优于现有模型。
📝 摘要(中文)
为了使AI助手能够更好地与人类协作,需要具备具身理解能力。然而,目前的多模态大语言模型(MLLM)主要关注第三人称视角(外视),忽略了第一人称视角(内视)视频的独特挑战。此外,高昂的数据获取成本限制了数据规模,影响了MLLM的性能。为了解决这些问题,我们提出学习外视和内视领域之间的映射,利用现有MLLM中丰富的外部知识来增强内视视频理解。为此,我们引入了Ego-ExoClip,一个包含110万个同步内外视clip-text对的预训练数据集,该数据集来源于Ego-Exo4D。同时,我们还收集了来自多个来源的指令调优数据集EgoIT,以增强模型的指令遵循能力。基于这些数据集,我们提出了一种迁移策略,并进一步设计了一个包含三个阶段的渐进式映射学习流程:演示者自我准备、演示者-学习者指导和学习者自我实践。在各种内视任务上的大量实验表明,现有的MLLM在内视视频理解方面表现不足,而我们的模型显著优于这些领先模型。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)在第一人称视角(内视)视频理解方面的不足。现有MLLM主要针对第三人称视角(外视)数据进行训练,缺乏对内视视频特性的理解,并且内视视频数据获取成本高昂,导致数据规模有限,严重影响了MLLM在内视场景下的性能。
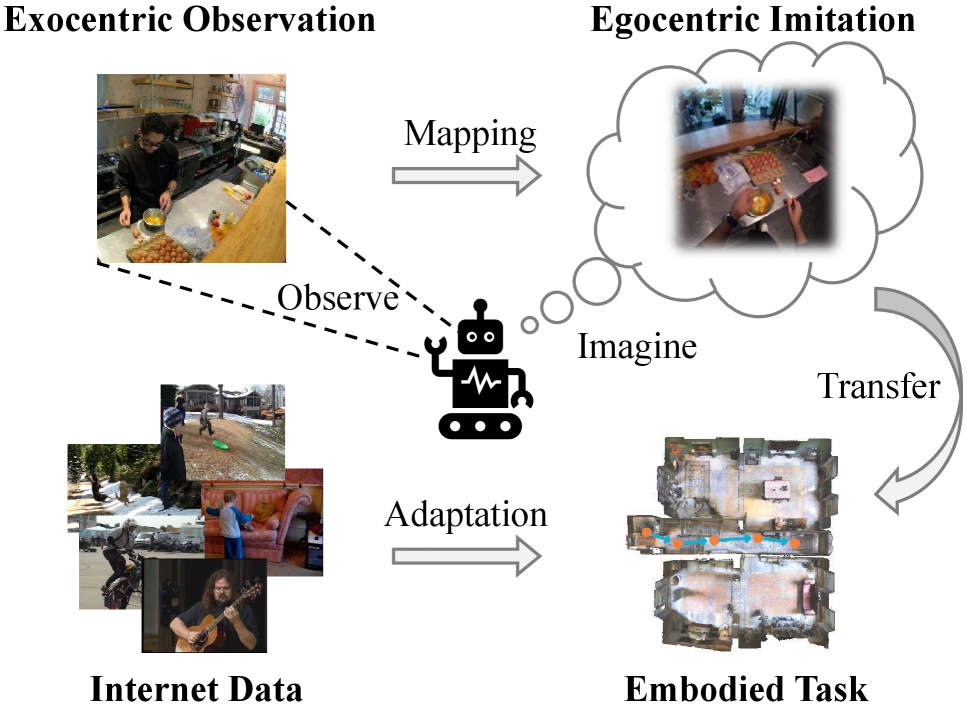
核心思路:论文的核心思路是利用外视视角MLLM中已经学习到的丰富知识,通过学习外视和内视领域之间的映射关系,将外视知识迁移到内视领域,从而提升MLLM在内视视频理解方面的能力。这种方法可以有效缓解内视数据稀缺的问题,并充分利用现有MLLM的知识储备。
技术框架:整体框架包含数据准备和模型训练两个主要部分。数据准备阶段构建了Ego-ExoClip和EgoIT两个数据集。Ego-ExoClip包含同步的内外视视频片段和文本描述,用于预训练。EgoIT是指令调优数据集,用于提升模型的指令遵循能力。模型训练阶段采用渐进式映射学习流程,包含三个阶段:1) Demonstrator Self-Preparation:利用外视数据预训练模型,使其具备初步的理解能力。2) Demonstrator-Learner Guidance:利用Ego-ExoClip数据集,指导模型学习外视和内视之间的映射关系。3) Learner Self-Practice:利用EgoIT数据集,对模型进行指令调优,提升其在内视场景下的指令遵循能力。
关键创新:论文的关键创新在于提出了一个渐进式的外视知识迁移框架,通过三个阶段的学习,逐步将外视MLLM的知识迁移到内视领域。此外,Ego-ExoClip数据集的构建也为内外视知识迁移提供了数据基础。
关键设计:在渐进式映射学习流程中,每个阶段都采用了特定的损失函数和训练策略。例如,在Demonstrator-Learner Guidance阶段,使用了对比学习损失来学习外视和内视视频片段之间的相似性。在Learner Self-Practice阶段,使用了指令调优损失来提升模型的指令遵循能力。具体的网络结构细节和参数设置在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
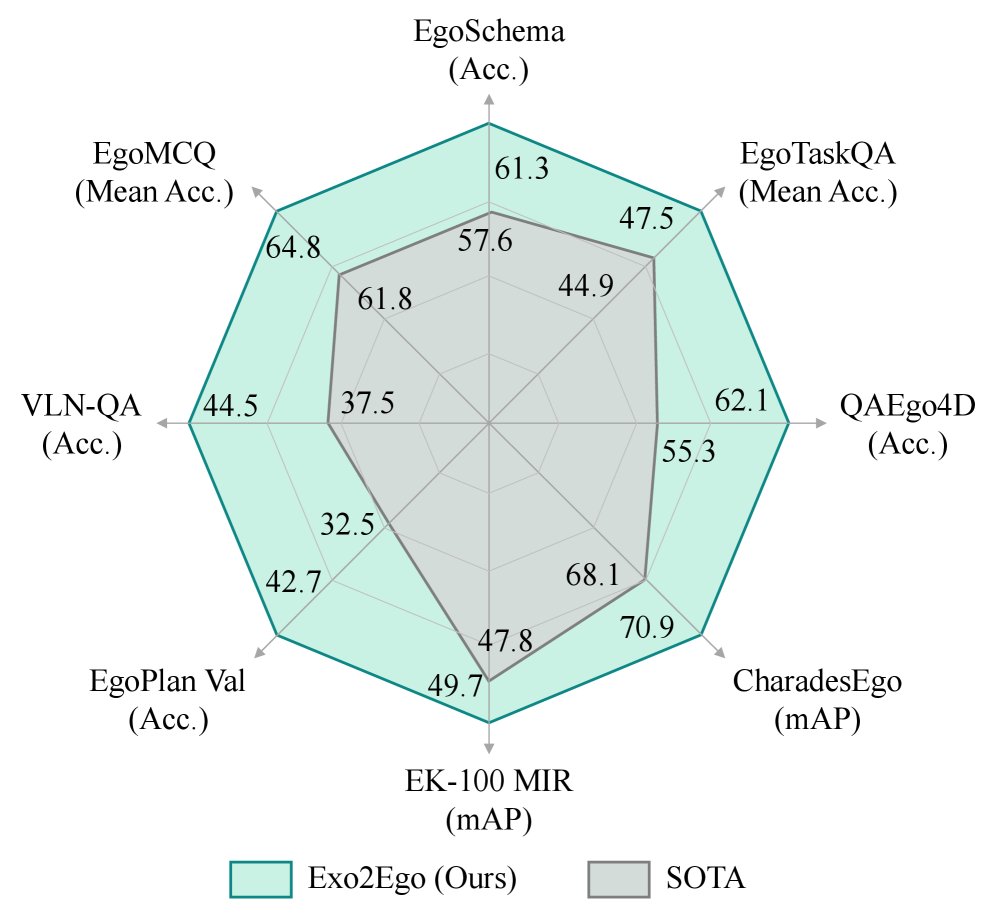
实验结果表明,现有的MLLM在内视视频理解方面表现不佳,而论文提出的Exo2Ego模型显著优于这些领先模型。具体的性能提升数据和对比基线在论文中有详细描述(未知)。该研究验证了外视知识迁移在提升内视视频理解方面的有效性。
🎯 应用场景
该研究成果可应用于开发更智能的AI个人助手,例如部署在机器人或可穿戴设备上的助手,能够更好地理解人类的意图和行为,从而实现更有效的协作。此外,该技术还可以应用于智能家居、智能安防、医疗辅助等领域,提升人机交互的智能化水平。
📄 摘要(原文)
AI personal assistants, deployed through robots or wearables, require embodied understanding to collaborate effectively with humans. However, current Multimodal Large Language Models (MLLMs) primarily focus on third-person (exocentric) vision, overlooking the unique challenges of first-person (egocentric) videos. Additionally, high acquisition costs limit data size, impairing MLLM performance. To address these challenges, we propose learning the mapping between exocentric and egocentric domains, leveraging the extensive exocentric knowledge within existing MLLMs to enhance egocentric video understanding. To this end, we introduce Ego-ExoClip, a pre-training dataset comprising 1.1M synchronized ego-exo clip-text pairs derived from Ego-Exo4D, together with the instruction-tuning dataset EgoIT, which is collected from multiple sources to enhance the model's instruction-following capabilities. Building upon the datasets, we propose a migration strategy and further design a progressive mapping learning pipeline with three stages: Demonstrator Self-Preparation, Demonstrator-Learner Guidance, and Learner Self-Practice. Extensive experiments across diverse egocentric tasks reveal that existing MLLMs perform inadequately in egocentric video understanding, while our model significantly outperforms these leading models.