Multi-Modal Foundation Models for Computational Pathology: A Survey
作者: Dong Li, Guihong Wan, Xintao Wu, Xinyu Wu, Xiaohui Chen, Yi He, Christine G. Lian, Peter K. Sorger, Yevgeniy R. Semenov, Chen Zhao
分类: cs.CV, cs.AI
发布日期: 2025-03-12 (更新: 2025-03-20)
💡 一句话要点
综述计算病理学中多模态基础模型,涵盖视觉-语言、视觉-知识图谱和视觉-基因表达三大范式。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 计算病理学 多模态学习 基础模型 组织病理学 全切片图像 视觉-语言模型 视觉-知识图谱 视觉-基因表达
📋 核心要点
- 现有计算病理学方法依赖单模态数据,忽略了文本报告、领域知识和分子谱等异构信息。
- 本文综述了多模态基础模型在计算病理学中的应用,涵盖视觉-语言、视觉-知识图谱和视觉-基因表达三大范式。
- 分析了现有数据集、下游任务、训练策略和评估方法,并指出了该领域面临的挑战和未来发展方向。
📝 摘要(中文)
基础模型已成为计算病理学(CPath)中一种强大的范式,能够对组织病理学图像进行可扩展和泛化的分析。早期的发展主要集中在仅在视觉数据上训练的单模态模型,而最近的进展突出了多模态基础模型的潜力,这些模型集成了异构数据源,如文本报告、结构化领域知识和分子谱。本综述全面且最新地回顾了CPath中的多模态基础模型,特别关注基于苏木精-伊红(H&E)染色的全切片图像(WSI)和切片级别表示的模型。我们将32个最先进的多模态基础模型分为三大范式:视觉-语言、视觉-知识图谱和视觉-基因表达。我们将视觉-语言模型进一步分为非LLM和基于LLM的方法。此外,我们分析了28个可用于病理学的多模态数据集,分为图像-文本对、指令数据集和图像-其他模态对。我们的综述还介绍了下游任务的分类、训练和评估策略,并确定了关键挑战和未来方向。我们希望本综述能为从事病理学和人工智能交叉领域的研究人员和从业人员提供有价值的资源。
🔬 方法详解
问题定义:计算病理学领域面临的挑战是如何有效地整合来自不同模态的数据,例如组织病理学图像、文本报告、基因表达谱和领域知识,以提高疾病诊断、预后预测和治疗方案选择的准确性和效率。现有的单模态方法无法充分利用这些异构信息,而早期多模态方法往往缺乏泛化能力和可扩展性。
核心思路:本文的核心思路是综述当前计算病理学领域中多模态基础模型的研究进展,并将其按照不同的模态组合方式进行分类,包括视觉-语言、视觉-知识图谱和视觉-基因表达。通过分析这些模型的架构、训练方法和应用场景,总结出多模态融合的优势和挑战,并为未来的研究方向提供指导。
技术框架:本文的综述框架主要包括以下几个部分:首先,介绍计算病理学和多模态基础模型的背景知识;其次,将现有的多模态基础模型分为三大范式,并详细描述每种范式下的代表性模型;然后,分析可用于训练和评估这些模型的多模态数据集;接着,总结下游任务的分类和评估策略;最后,讨论该领域面临的挑战和未来的研究方向。
关键创新:本文的创新之处在于对计算病理学领域的多模态基础模型进行了系统性的梳理和分类,并从数据、模型、任务和评估等多个角度进行了深入的分析。此外,本文还指出了该领域目前面临的一些关键挑战,例如如何有效地处理不同模态数据之间的异构性、如何提高模型的泛化能力和可解释性等。
关键设计:本文主要关注多模态基础模型的架构设计和训练策略。例如,在视觉-语言模型中,研究了基于Transformer的架构和对比学习的训练方法;在视觉-知识图谱模型中,研究了如何将领域知识嵌入到模型中;在视觉-基因表达模型中,研究了如何利用基因表达谱来指导图像特征的学习。此外,本文还关注了不同模态数据之间的对齐方式和融合策略。
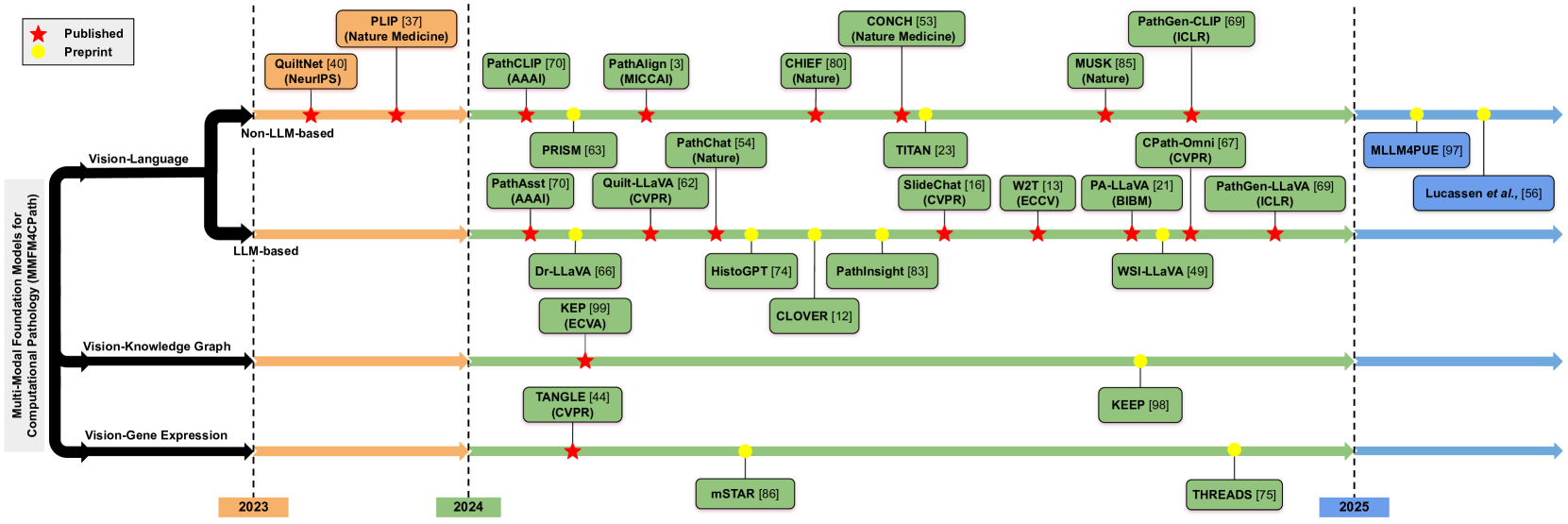
🖼️ 关键图片


📊 实验亮点
本文对32个最先进的多模态基础模型进行了分类和分析,并总结了28个可用于病理学的多模态数据集。通过对这些模型和数据的研究,可以更好地了解多模态融合在计算病理学中的潜力,并为未来的研究提供参考。
🎯 应用场景
该研究成果可应用于多种临床场景,例如辅助病理医生进行更准确的癌症诊断和分型,预测患者的预后情况,以及为患者制定个性化的治疗方案。多模态融合有望提高诊断效率,减少误诊率,并最终改善患者的生存率和生活质量。
📄 摘要(原文)
Foundation models have emerged as a powerful paradigm in computational pathology (CPath), enabling scalable and generalizable analysis of histopathological images. While early developments centered on uni-modal models trained solely on visual data, recent advances have highlighted the promise of multi-modal foundation models that integrate heterogeneous data sources such as textual reports, structured domain knowledge, and molecular profiles. In this survey, we provide a comprehensive and up-to-date review of multi-modal foundation models in CPath, with a particular focus on models built upon hematoxylin and eosin (H&E) stained whole slide images (WSIs) and tile-level representations. We categorize 32 state-of-the-art multi-modal foundation models into three major paradigms: vision-language, vision-knowledge graph, and vision-gene expression. We further divide vision-language models into non-LLM-based and LLM-based approaches. Additionally, we analyze 28 available multi-modal datasets tailored for pathology, grouped into image-text pairs, instruction datasets, and image-other modality pairs. Our survey also presents a taxonomy of downstream tasks, highlights training and evaluation strategies, and identifies key challenges and future directions. We aim for this survey to serve as a valuable resource for researchers and practitioners working at the intersection of pathology and AI.