Open-World Skill Discovery from Unsegmented Demonstrations
作者: Jingwen Deng, Zihao Wang, Shaofei Cai, Anji Liu, Yitao Liang
分类: cs.CV, cs.AI
发布日期: 2025-03-11 (更新: 2025-08-31)
备注: Accepted by ICCV 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于自监督学习的技能边界检测方法,从无分割演示视频中发现技能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 技能发现 视频分割 自监督学习 动作预测 开放世界 机器人学习
📋 核心要点
- 现有方法依赖序列采样或人工标注来分割无分割演示视频,成本高且效率低,难以应用于开放世界环境。
- 该论文提出一种基于自监督学习的技能边界检测(SBD)算法,利用动作预测模型的预测误差来自动分割视频。
- 在Minecraft中的实验表明,SBD生成的片段显著提升了智能体在短期和长期任务中的性能,验证了方法的有效性。
📝 摘要(中文)
本文提出了一种在开放世界环境中学习技能的方法,旨在通过组合基本技能来开发能够处理各种任务的智能体。针对在线演示视频通常冗长且未分割,难以进行技能识别和标注的问题,本文提出了一种基于自监督学习的方法,将这些长视频分割成一系列语义感知且技能一致的片段。该方法受到人类认知事件分割理论的启发,引入了技能边界检测(SBD)算法,这是一种无需标注的时序视频分割算法。SBD通过利用预训练的无条件动作预测模型的预测误差来检测视频中的技能边界,其基本假设是预测误差的显著增加表明正在执行的技能发生了转变。在Minecraft中进行的评估表明,SBD生成的片段将条件策略在短期原子技能任务上的平均性能提高了63.7%和52.1%,并且其对应的分层智能体在长时程任务上的性能提高了11.3%和20.8%。该方法能够利用多样化的YouTube视频来训练指令跟随智能体。
🔬 方法详解
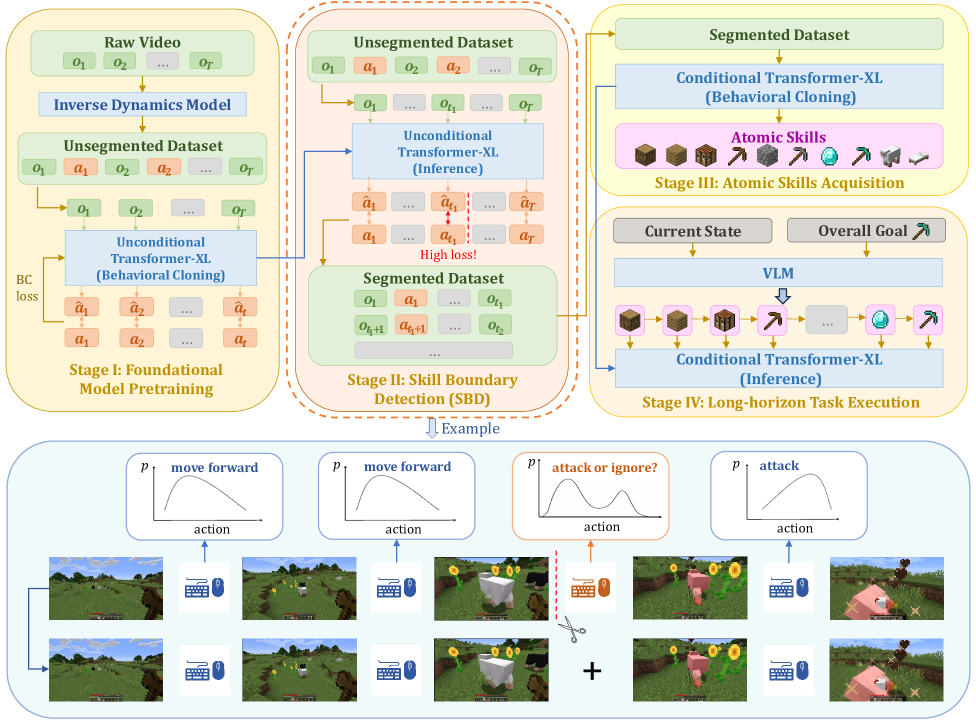
问题定义:论文旨在解决从无分割的演示视频中自动发现技能的问题。现有的方法通常依赖于人工标注或者序列采样,这两种方法都存在明显的局限性。人工标注成本高昂且耗时,而序列采样则难以保证分割后的片段具有语义一致性和技能完整性。因此,如何高效且自动地从长视频中提取出有意义的技能片段是一个重要的挑战。
核心思路:论文的核心思路是受到人类认知事件分割理论的启发,认为技能的切换通常伴随着显著的动作变化。因此,可以通过检测视频中动作预测误差的突变来识别技能边界。具体来说,如果一个预训练的动作预测模型在某个时间点的预测误差突然增大,则表明该时间点可能发生了技能切换。
技术框架:整体框架包含两个主要步骤:首先,使用大量的未标注视频数据训练一个无条件动作预测模型。然后,利用该模型对目标视频进行动作预测,并计算每个时间点的预测误差。通过分析预测误差的变化,可以检测出视频中的技能边界,从而将长视频分割成一系列技能片段。这些片段可以用于训练条件策略或分层智能体。
关键创新:该方法最重要的创新点在于提出了一种基于预测误差的自监督技能边界检测方法。与传统的依赖人工标注或序列采样的方法相比,该方法能够自动地从无分割的视频中学习技能,无需任何人工干预。此外,该方法还能够有效地捕捉到视频中的语义信息,从而保证分割后的片段具有技能一致性。
关键设计:论文使用Transformer网络作为动作预测模型,并采用交叉熵损失函数进行训练。在技能边界检测方面,论文采用了一种基于滑动窗口的策略,计算每个时间点的预测误差的平均值和方差。如果某个时间点的预测误差显著高于其周围时间点的预测误差,则认为该时间点是一个技能边界。具体的阈值参数需要根据实际情况进行调整。
🖼️ 关键图片
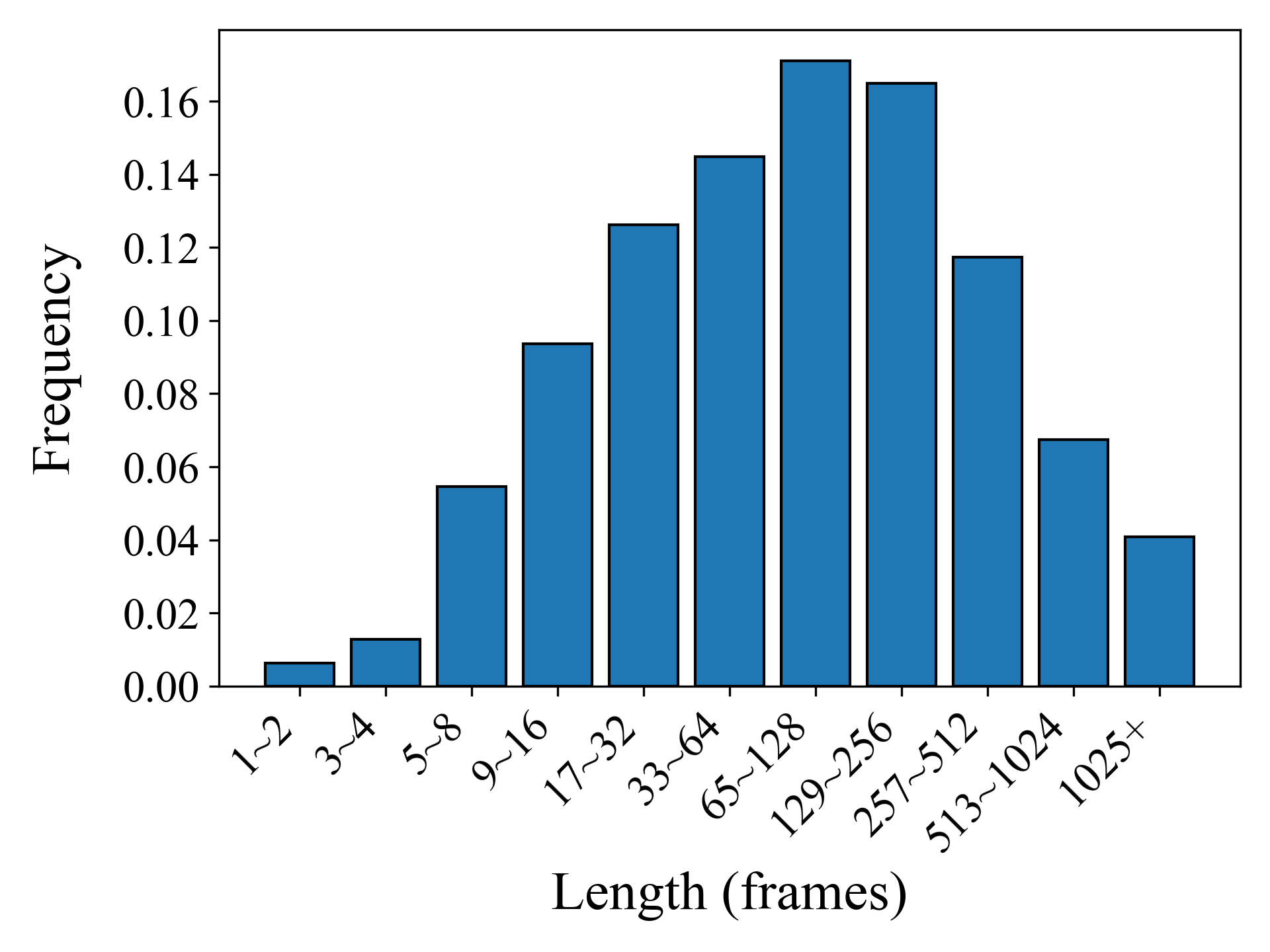
📊 实验亮点
实验结果表明,使用SBD生成的片段训练的条件策略在Minecraft的短期原子技能任务上,相比于使用原始视频片段训练的策略,平均性能提升了63.7%和52.1%。此外,使用SBD生成的片段训练的分层智能体在长时程任务上的性能也提升了11.3%和20.8%。这些结果充分证明了SBD算法的有效性,以及其在技能发现方面的潜力。
🎯 应用场景
该研究成果可广泛应用于机器人学习、游戏AI、自动驾驶等领域。通过从大量的在线视频中自动学习技能,可以显著降低智能体的训练成本,并提高其在复杂环境中的适应能力。例如,可以利用YouTube上的游戏视频来训练游戏AI,或者利用驾驶视频来训练自动驾驶系统。此外,该方法还可以用于视频内容分析和理解,例如自动生成视频摘要或识别视频中的关键事件。
📄 摘要(原文)
Learning skills in open-world environments is essential for developing agents capable of handling a variety of tasks by combining basic skills. Online demonstration videos are typically long but unsegmented, making them difficult to segment and label with skill identifiers. Unlike existing methods that rely on sequence sampling or human labeling, we have developed a self-supervised learning-based approach to segment these long videos into a series of semantic-aware and skill-consistent segments. Drawing inspiration from human cognitive event segmentation theory, we introduce Skill Boundary Detection (SBD), an annotation-free temporal video segmentation algorithm. SBD detects skill boundaries in a video by leveraging prediction errors from a pretrained unconditional action-prediction model. This approach is based on the assumption that a significant increase in prediction error indicates a shift in the skill being executed. We evaluated our method in Minecraft, a rich open-world simulator with extensive gameplay videos available online. Our SBD-generated segments improved the average performance of conditioned policies by 63.7% and 52.1% on short-term atomic skill tasks, and their corresponding hierarchical agents by 11.3% and 20.8% on long-horizon tasks. Our method can leverage the diverse YouTube videos to train instruction-following agents. The project page can be found in https://craftjarvis.github.io/SkillDiscovery.