SpurLens: Automatic Detection of Spurious Cues in Multimodal LLMs
作者: Parsa Hosseini, Sumit Nawathe, Mazda Moayeri, Sriram Balasubramanian, Soheil Feizi
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-03-11 (更新: 2025-12-15)
💡 一句话要点
SpurLens:自动检测多模态LLM中的虚假线索,提升模型可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 虚假相关性 目标检测 模型评估 提示工程 对象幻觉
📋 核心要点
- 现有的多模态模型容易受到虚假相关性的影响,导致模型在不相关的视觉线索上产生偏差,影响其泛化能力。
- SpurLens利用GPT-4和开放集目标检测器自动识别图像中的虚假线索,无需人工干预,从而诊断MLLM中的偏差。
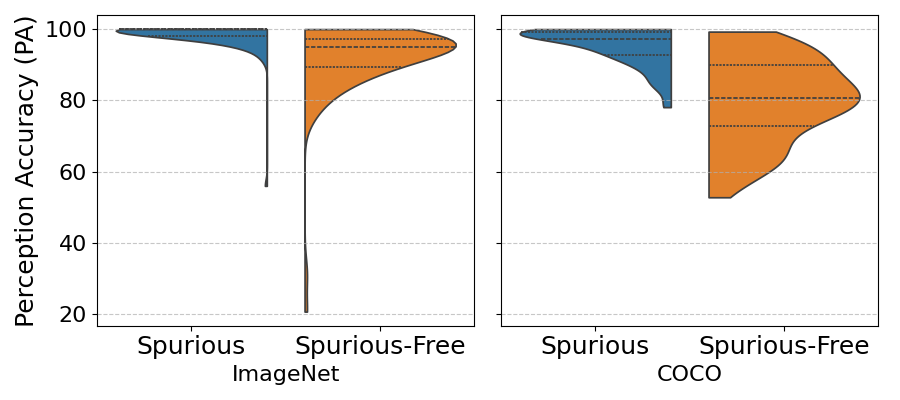
- 实验表明,虚假线索会导致MLLM在对象识别上过度依赖,并显著放大对象幻觉,提示集成和推理提示可以缓解这些问题。
📝 摘要(中文)
本文研究了多模态大型语言模型(MLLM)中存在的虚假相关性偏差问题。作者提出了SpurLens,一个利用GPT-4和开放集目标检测器自动识别虚假视觉线索的流程,无需人工监督。研究发现,虚假相关性导致MLLM出现两种主要失效模式:(1)过度依赖虚假线索进行对象识别,移除这些线索会降低准确性;(2)对象幻觉,虚假线索会放大幻觉现象,放大倍数超过10倍。作者在各种MLLM和数据集上验证了这些发现。除了诊断这些失效问题,还探索了潜在的缓解策略,如提示集成和基于推理的提示,并进行了消融研究以检查MLLM中虚假偏差的根本原因。这项研究揭示了虚假相关性的持续存在,呼吁采用更严格的评估方法和缓解策略,以提高MLLM的可靠性。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)中存在的虚假线索依赖问题。现有的MLLM虽然受益于语言监督,但仍然可能像单模态视觉模型一样,受到图像中虚假相关性的影响,导致模型在不相关的视觉特征上产生偏差,从而影响其在真实场景中的性能。现有的方法缺乏自动、高效地识别和评估这些虚假线索的手段。
核心思路:论文的核心思路是利用大型语言模型(GPT-4)的强大推理能力和开放集目标检测器的物体识别能力,构建一个自动化的流程(SpurLens)来识别图像中可能存在的虚假线索。通过分析MLLM在存在和移除这些虚假线索时的表现,来评估模型对这些线索的依赖程度。
技术框架:SpurLens的整体框架包含以下几个主要步骤:1) 使用开放集目标检测器识别图像中的潜在物体;2) 利用GPT-4生成关于这些物体的描述和它们与图像中其他物体的关系的假设,这些假设可能指示虚假相关性;3) 通过修改图像(例如,移除或改变识别出的物体)来测试MLLM对这些虚假线索的依赖程度;4) 分析MLLM在修改前后图像上的表现差异,从而评估虚假线索的影响。
关键创新:该论文的关键创新在于提出了一个完全自动化的流程(SpurLens)来识别和评估MLLM中的虚假线索,无需人工标注或干预。这使得大规模分析MLLM的偏差成为可能,并为开发更鲁棒的多模态模型提供了新的思路。
关键设计:SpurLens的关键设计包括:1) 使用GPT-4生成关于图像内容的假设,这需要精心设计的提示语来引导GPT-4产生有意义的假设;2) 使用图像编辑技术来移除或改变图像中的物体,这需要保证修改后的图像仍然具有一定的真实性,以便MLLM能够理解;3) 设计合适的评估指标来量化MLLM对虚假线索的依赖程度,例如,比较模型在原始图像和修改后图像上的准确率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MLLM在对象识别中过度依赖虚假线索,移除这些线索会导致准确率下降。更重要的是,虚假线索会显著放大对象幻觉,放大倍数超过10倍。通过提示集成和基于推理的提示等方法,可以有效缓解这些问题,提升模型的可靠性。
🎯 应用场景
该研究成果可应用于评估和改进多模态大型语言模型的可靠性和鲁棒性。通过识别和缓解模型对虚假线索的依赖,可以提高模型在实际应用中的性能,例如在自动驾驶、医疗诊断和智能客服等领域,减少因虚假相关性导致的错误决策,提升用户体验。
📄 摘要(原文)
Unimodal vision models are known to rely on spurious correlations, but it remains unclear to what extent Multimodal Large Language Models (MLLMs) exhibit similar biases despite language supervision. In this paper, we investigate spurious bias in MLLMs and introduce SpurLens, a pipeline that leverages GPT-4 and open-set object detectors to automatically identify spurious visual cues without human supervision. Our findings reveal that spurious correlations cause two major failure modes in MLLMs: (1) over-reliance on spurious cues for object recognition, where removing these cues reduces accuracy, and (2) object hallucination, where spurious cues amplify the hallucination by over 10x. We validate our findings in various MLLMs and datasets. Beyond diagnosing these failures, we explore potential mitigation strategies, such as prompt ensembling and reasoning-based prompting, and conduct ablation studies to examine the root causes of spurious bias in MLLMs. By exposing the persistence of spurious correlations, our study calls for more rigorous evaluation methods and mitigation strategies to enhance the reliability of MLLMs.