FunGraph: Functionality Aware 3D Scene Graphs for Language-Prompted Scene Interaction
作者: Dennis Rotondi, Fabio Scaparro, Hermann Blum, Kai O. Arras
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-03-10 (更新: 2025-08-10)
备注: Paper accepted for IROS 2025
💡 一句话要点
FunGraph:面向语言提示场景交互的功能感知3D场景图
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景图 功能感知 可供性 机器人交互 语义分割
📋 核心要点
- 现有3D场景图主要关注对象级别的粗略表示,缺乏对功能性交互元素的精细建模,限制了机器人与环境的直接交互能力。
- FunGraph通过检测和存储对象中与可供性相关的部分,构建功能感知的3D场景图,从而实现机器人对环境的细粒度理解和交互。
- 该方法利用现有3D资源生成2D数据训练检测器,并将其集成到3D场景图生成流程中,实验表明其功能元素分割性能与SOTA模型相当。
📝 摘要(中文)
3D场景图的概念日益被认为是环境的一种强大语义和分层表示。目前的方法通常在粗略的对象级别分辨率上解决这个问题。相比之下,我们的目标是开发一种表示,使机器人能够通过识别功能性交互元素的位置以及如何使用它们来直接与环境交互。为了实现这一目标,我们专注于以更精细的分辨率检测和存储对象,重点关注与可供性相关的部分。主要的挑战在于缺乏超出实例级别检测的数据,以及使用机器人传感器捕获详细对象特征的固有难度。我们利用当前可用的3D资源来生成2D数据并训练检测器,然后将其用于增强标准的3D场景图生成流程。通过我们的实验,我们证明了我们的方法实现了与最先进的3D模型相当的功能元素分割,并且我们的增强能够以比当前解决方案更高的精度进行任务驱动的可供性 grounding。
🔬 方法详解
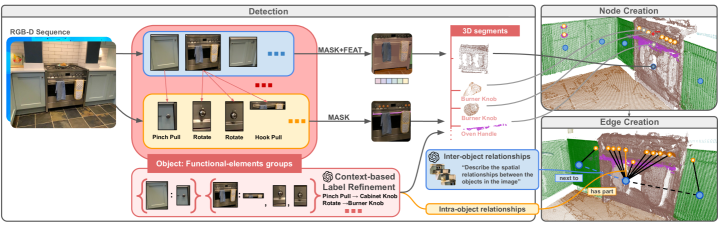
问题定义:现有3D场景图主要关注物体级别的语义信息,缺乏对物体功能性部件的精细建模,导致机器人难以理解物体的可交互性,无法直接根据语言指令与环境进行交互。例如,机器人无法识别“打开抽屉”中的“抽屉把手”这一关键交互部件。
核心思路:论文的核心思路是构建一种功能感知的3D场景图,即FunGraph。该场景图不仅包含物体级别的语义信息,还包含物体上可交互部件的精细信息,从而使机器人能够理解物体的可供性,并根据语言指令找到合适的交互方式。
技术框架:FunGraph的构建流程主要包含以下几个阶段:1) 利用现有的3D资源生成2D数据,并训练一个检测器,用于检测物体上的功能性部件;2) 使用训练好的检测器对3D场景进行分析,提取物体上的功能性部件;3) 将提取到的功能性部件信息集成到标准的3D场景图生成流程中,构建FunGraph。
关键创新:论文的关键创新在于提出了功能感知的3D场景图FunGraph,该场景图能够表示物体上的可交互部件,从而使机器人能够理解物体的可供性。此外,论文还提出了一种利用现有3D资源生成2D数据的方法,用于训练功能性部件检测器,解决了数据稀缺的问题。
关键设计:论文使用Mask R-CNN作为2D检测器,用于检测物体上的功能性部件。为了解决数据稀缺的问题,论文利用现有的3D模型,通过渲染生成大量的2D图像,并对图像进行标注,用于训练检测器。在3D场景图的构建过程中,论文使用PointNet++对3D点云进行分割,提取物体上的功能性部件,并将这些部件的信息添加到场景图中。
🖼️ 关键图片


📊 实验亮点
实验结果表明,FunGraph能够有效地分割物体上的功能性部件,其性能与最先进的3D模型相当。此外,FunGraph能够提高任务驱动的可供性 grounding 的准确率,优于现有的解决方案。具体而言,在语言提示的场景交互任务中,FunGraph能够更准确地找到物体上的可交互部件,从而提高交互的成功率。
🎯 应用场景
FunGraph可应用于机器人导航、物体操作、人机交互等领域。例如,在家庭服务机器人中,FunGraph可以帮助机器人理解用户的语言指令,并找到合适的物体进行交互,例如“把遥控器放在电视柜上”。该研究有助于提升机器人的智能化水平,使其能够更好地服务于人类。
📄 摘要(原文)
The concept of 3D scene graphs is increasingly recognized as a powerful semantic and hierarchical representation of the environment. Current approaches often address this at a coarse, object-level resolution. In contrast, our goal is to develop a representation that enables robots to directly interact with their environment by identifying both the location of functional interactive elements and how these can be used. To achieve this, we focus on detecting and storing objects at a finer resolution, focusing on affordance-relevant parts. The primary challenge lies in the scarcity of data that extends beyond instance-level detection and the inherent difficulty of capturing detailed object features using robotic sensors. We leverage currently available 3D resources to generate 2D data and train a detector, which is then used to augment the standard 3D scene graph generation pipeline. Through our experiments, we demonstrate that our approach achieves functional element segmentation comparable to state-of-the-art 3D models and that our augmentation enables task-driven affordance grounding with higher accuracy than the current solutions. See our project page at https://fungraph.github.io.