AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
作者: Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, Xinggang Wang
分类: cs.CV, cs.RO
发布日期: 2025-03-10
备注: Project Page: https://github.com/hustvl/AlphaDrive
💡 一句话要点
AlphaDrive:通过强化学习和推理释放VLM在自动驾驶中的潜力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 视觉语言模型 强化学习 规划推理 GRPO 多模态学习 端到端模型
📋 核心要点
- 现有端到端自动驾驶模型缺乏足够的常识和推理能力,难以处理长尾场景,限制了其泛化能力。
- AlphaDrive提出了一种基于GRPO的强化学习和推理框架,专门为自动驾驶中的VLM规划任务设计。
- 实验表明,AlphaDrive显著提升了规划性能和训练效率,并展现出涌现的多模态规划能力。
📝 摘要(中文)
OpenAI o1和DeepSeek R1等大型语言模型在数学和科学等复杂领域达到了甚至超越了人类专家的水平,强化学习(RL)和推理在其中发挥了关键作用。在自动驾驶领域,最近的端到端模型在规划性能方面有了很大的提高,但由于常识和推理能力的限制,仍然难以解决长尾问题。一些研究将视觉语言模型(VLM)集成到自动驾驶中,但它们通常依赖于预训练模型,并在驾驶数据上进行简单的监督微调(SFT),而没有进一步探索专门为规划量身定制的训练策略或优化方法。本文提出了AlphaDrive,一个用于自动驾驶中VLM的RL和推理框架。AlphaDrive引入了四个基于GRPO的、为规划量身定制的RL奖励,并采用了一种结合SFT和RL的两阶段规划推理训练策略。结果表明,与仅使用SFT或不使用推理相比,AlphaDrive显著提高了规划性能和训练效率。此外,我们还惊喜地发现,经过RL训练后,AlphaDrive表现出一些涌现的多模态规划能力,这对于提高驾驶安全性和效率至关重要。据我们所知,AlphaDrive是第一个将基于GRPO的RL与规划推理集成到自动驾驶中的方法。代码将被发布以促进未来的研究。
🔬 方法详解
问题定义:论文旨在解决自动驾驶中,现有端到端模型由于缺乏常识和推理能力,难以处理复杂和长尾场景的问题。现有方法通常依赖于预训练的VLM,并使用简单的监督微调,缺乏针对规划任务的优化。
核心思路:论文的核心思路是将强化学习(RL)与视觉语言模型(VLM)相结合,并引入规划推理机制,从而提升自动驾驶系统在复杂环境下的决策能力。通过强化学习,模型可以学习到更优的驾驶策略,而规划推理则有助于模型理解场景并做出更合理的规划。
技术框架:AlphaDrive框架包含两个主要阶段:监督微调(SFT)和强化学习(RL)。在SFT阶段,使用驾驶数据对VLM进行微调,使其初步具备驾驶能力。在RL阶段,使用基于GRPO的奖励函数对模型进行训练,进一步提升其规划性能。框架还包含一个规划推理模块,用于在规划过程中进行推理,从而提高规划的合理性。
关键创新:AlphaDrive的关键创新在于将GRPO-based RL与规划推理相结合,并将其应用于自动驾驶领域。这是首次将这种方法应用于自动驾驶,并取得了显著的效果。此外,AlphaDrive还发现了经过RL训练后,模型表现出涌现的多模态规划能力。
关键设计:AlphaDrive使用了四个基于GRPO的RL奖励,这些奖励是专门为自动驾驶规划任务设计的。两阶段训练策略包括SFT和RL,SFT用于初始化模型,RL用于优化策略。规划推理模块的具体实现细节未知,但其目的是提高规划的合理性。具体网络结构和参数设置在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片
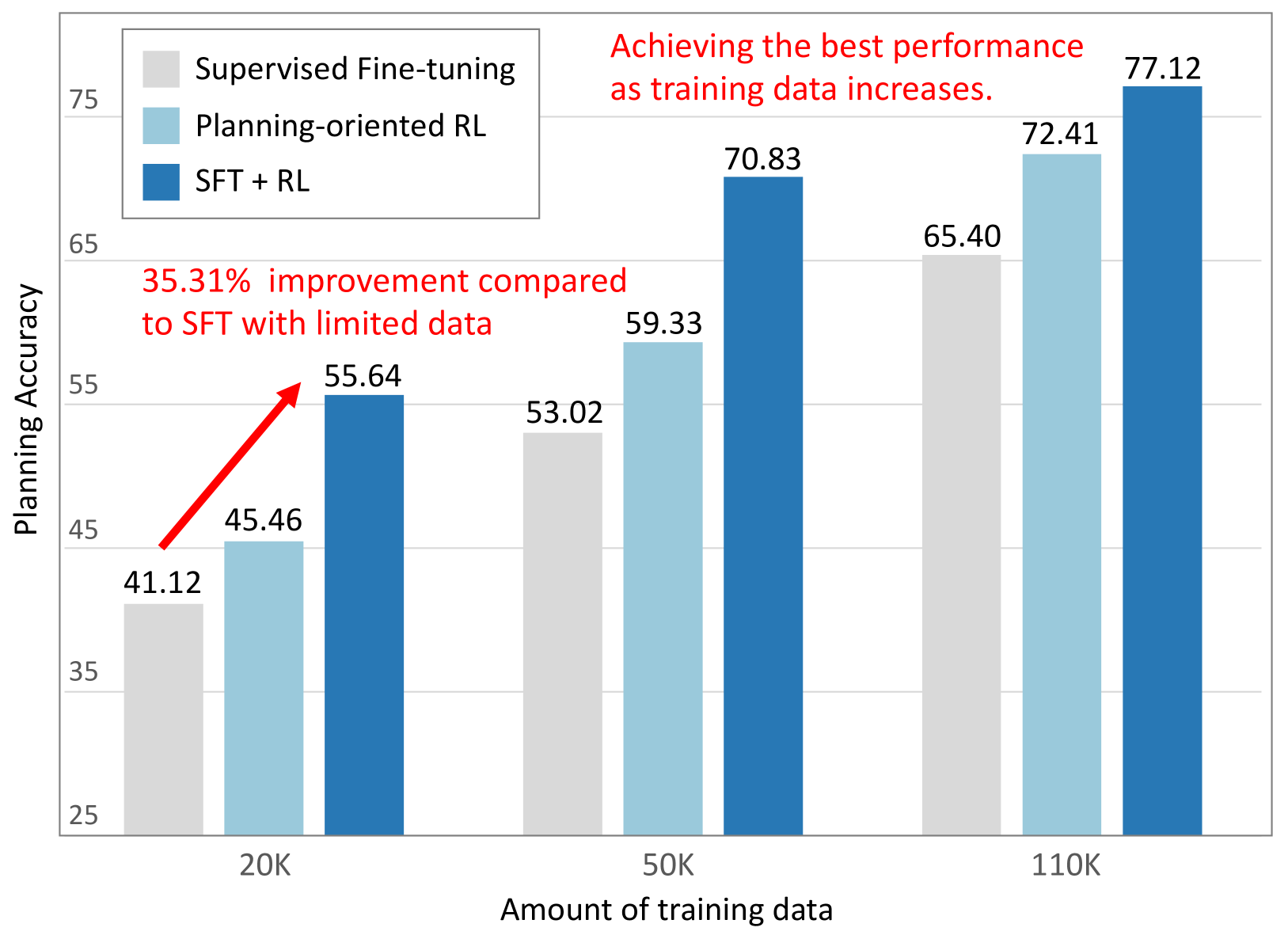


📊 实验亮点
AlphaDrive通过结合强化学习和推理,显著提高了自动驾驶规划性能和训练效率。论文中提到,与仅使用SFT或不使用推理相比,AlphaDrive取得了显著的性能提升,但具体的性能数据和提升幅度未知。此外,AlphaDrive还展现出涌现的多模态规划能力,这对于提高驾驶安全性和效率至关重要。
🎯 应用场景
AlphaDrive的研究成果可应用于各种自动驾驶场景,尤其是在城市复杂交通环境和长尾场景下。该方法有望提高自动驾驶系统的安全性、可靠性和效率,加速自动驾驶技术的商业化落地。此外,该研究思路也可推广到其他需要复杂推理和决策的机器人应用领域。
📄 摘要(原文)
OpenAI o1 and DeepSeek R1 achieve or even surpass human expert-level performance in complex domains like mathematics and science, with reinforcement learning (RL) and reasoning playing a crucial role. In autonomous driving, recent end-to-end models have greatly improved planning performance but still struggle with long-tailed problems due to limited common sense and reasoning abilities. Some studies integrate vision-language models (VLMs) into autonomous driving, but they typically rely on pre-trained models with simple supervised fine-tuning (SFT) on driving data, without further exploration of training strategies or optimizations specifically tailored for planning. In this paper, we propose AlphaDrive, a RL and reasoning framework for VLMs in autonomous driving. AlphaDrive introduces four GRPO-based RL rewards tailored for planning and employs a two-stage planning reasoning training strategy that combines SFT with RL. As a result, AlphaDrive significantly improves both planning performance and training efficiency compared to using only SFT or without reasoning. Moreover, we are also excited to discover that, following RL training, AlphaDrive exhibits some emergent multimodal planning capabilities, which is critical for improving driving safety and efficiency. To the best of our knowledge, AlphaDrive is the first to integrate GRPO-based RL with planning reasoning into autonomous driving. Code will be released to facilitate future research.