Bayesian Fields: Task-driven Open-Set Semantic Gaussian Splatting
作者: Dominic Maggio, Luca Carlone
分类: cs.CV
发布日期: 2025-03-07
💡 一句话要点
提出 Bayesian Fields,用于任务驱动的开放集语义高斯 Splatting。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放集语义地图 高斯Splatting 贝叶斯更新 任务驱动 视觉语言模型 3D重建 机器人导航
📋 核心要点
- 现有开放集语义地图构建方法难以确定合适的场景表示粒度,通常依赖手动调整的阈值,缺乏任务驱动性。
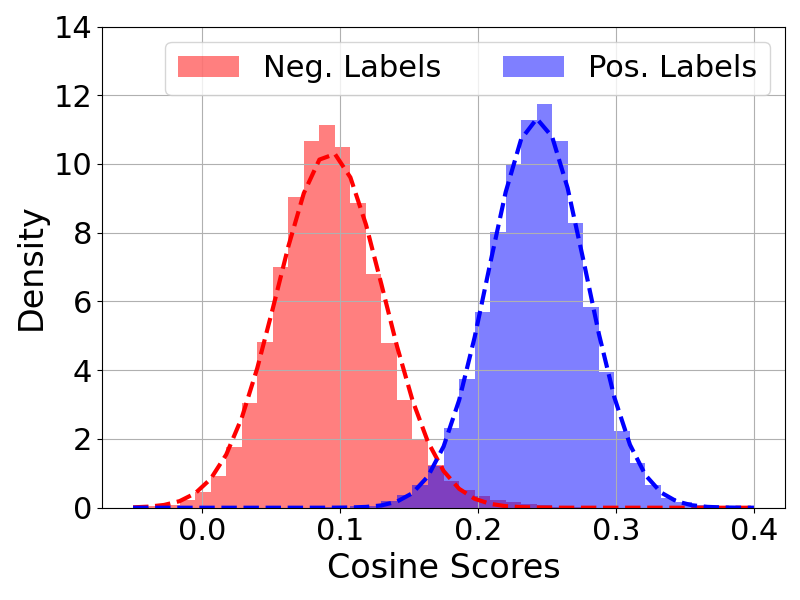
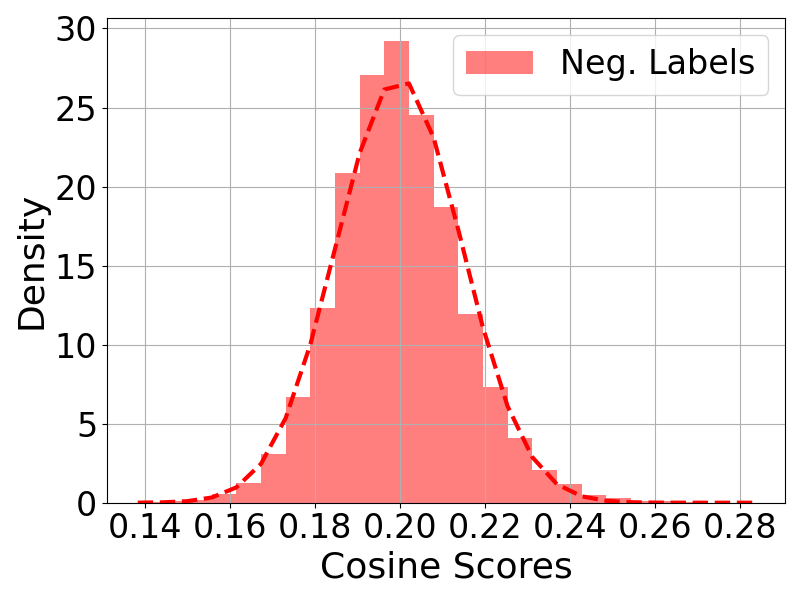
- Bayesian Fields 提出了一种任务驱动的语义映射方法,利用视觉-语言基础模型的概率特性和贝叶斯更新来融合多视角语义信息。
- 该方法使用 3D 高斯分布表示场景,并将其聚类成任务相关的对象,实现了高保真对象提取和低内存占用。
📝 摘要(中文)
开放集语义地图构建需要(i)确定表示场景的正确粒度(例如,如何定义对象),以及(ii)将来自多个2D观测的语义知识融合到整体3D重建中——理想情况下,以高保真度但低内存占用实现。大多数相关工作通过将具有相似语义的图元分组在一起(根据一些手动调整的阈值)来绕过第一个问题,但我们认识到对象粒度是任务相关的,并开发了一种任务驱动的语义映射方法。为了解决第二个问题,目前的做法是对多个视图上的视觉嵌入向量进行平均。相反,我们展示了使用基于底层视觉-语言基础模型属性的概率方法,并利用贝叶斯更新来聚合场景的多个观测的优势。结果是 Bayesian Fields,一种用于开放集语义映射的任务驱动和概率方法。为了实现高保真对象和密集的场景表示,Bayesian Fields 使用 3D 高斯分布,我们将其聚类成任务相关的对象,从而可以轻松进行 3D 对象提取并减少内存使用。我们在 https://github.com/MIT-SPARK/Bayesian-Fields 开源发布了 Bayesian Fields。
🔬 方法详解
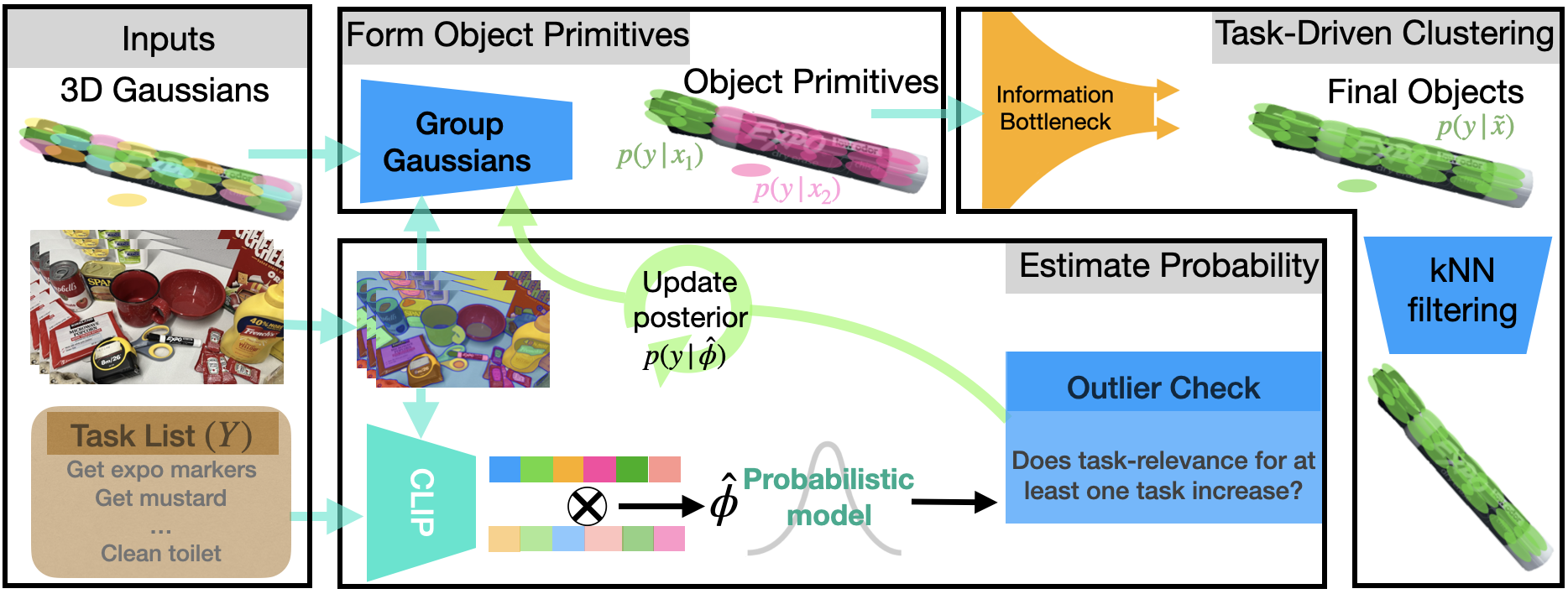
问题定义:开放集语义地图构建旨在从多个2D图像中重建3D场景,并赋予场景中的对象语义标签。现有方法主要面临两个挑战:一是如何确定合适的场景表示粒度,即如何定义和分割对象;二是怎样有效地融合来自不同视角的语义信息。现有方法通常采用人工设定的阈值来聚类具有相似语义的图元,缺乏任务驱动性,且简单的平均多视角视觉嵌入向量的方法忽略了底层视觉-语言模型的概率特性。
核心思路:Bayesian Fields 的核心思路是利用任务驱动的方式确定对象粒度,并采用概率方法融合多视角语义信息。具体来说,该方法将场景表示为3D高斯分布的集合,并根据任务需求将这些高斯分布聚类成不同的对象。同时,利用视觉-语言基础模型的概率特性,通过贝叶斯更新的方式融合来自不同视角的语义信息,从而提高语义地图构建的准确性和鲁棒性。
技术框架:Bayesian Fields 的整体框架包含以下几个主要模块:1) 3D高斯分布初始化:使用多视角图像初始化场景中的3D高斯分布;2) 视觉-语言特征提取:利用视觉-语言基础模型提取每个高斯分布的视觉和语义特征;3) 贝叶斯更新:利用贝叶斯更新的方式融合来自不同视角的语义信息,更新每个高斯分布的语义标签;4) 任务驱动的对象聚类:根据任务需求,将具有相似语义的高斯分布聚类成不同的对象;5) 3D场景重建:利用聚类后的高斯分布重建3D场景。
关键创新:Bayesian Fields 的关键创新在于:1) 提出了任务驱动的对象粒度确定方法,避免了人工设定阈值的主观性;2) 利用视觉-语言基础模型的概率特性,采用贝叶斯更新的方式融合多视角语义信息,提高了语义地图构建的准确性和鲁棒性;3) 使用3D高斯分布表示场景,并将其聚类成任务相关的对象,实现了高保真对象提取和低内存占用。
关键设计:Bayesian Fields 的关键设计包括:1) 视觉-语言基础模型的选择:选择合适的视觉-语言基础模型,以提取高质量的视觉和语义特征;2) 贝叶斯更新的参数设置:合理设置贝叶斯更新的参数,以平衡新观测和先验知识的重要性;3) 对象聚类的损失函数设计:设计合适的损失函数,以实现任务驱动的对象聚类。
🖼️ 关键图片
📊 实验亮点
论文开源了 Bayesian Fields,并在多个数据集上进行了实验验证。实验结果表明,Bayesian Fields 在开放集语义地图构建任务上取得了显著的性能提升,尤其是在对象分割和语义标注方面。相较于传统方法,Bayesian Fields 能够更准确地识别和分割场景中的对象,并赋予其正确的语义标签。
🎯 应用场景
Bayesian Fields 可应用于机器人导航、自动驾驶、增强现实等领域。例如,在机器人导航中,可以利用该方法构建高精度的语义地图,帮助机器人理解周围环境,从而实现更智能的导航和交互。在自动驾驶中,可以利用该方法识别道路上的车辆、行人等目标,提高自动驾驶系统的安全性。在增强现实中,可以利用该方法将虚拟对象与真实场景进行融合,提供更逼真的增强现实体验。
📄 摘要(原文)
Open-set semantic mapping requires (i) determining the correct granularity to represent the scene (e.g., how should objects be defined), and (ii) fusing semantic knowledge across multiple 2D observations into an overall 3D reconstruction -ideally with a high-fidelity yet low-memory footprint. While most related works bypass the first issue by grouping together primitives with similar semantics (according to some manually tuned threshold), we recognize that the object granularity is task-dependent, and develop a task-driven semantic mapping approach. To address the second issue, current practice is to average visual embedding vectors over multiple views. Instead, we show the benefits of using a probabilistic approach based on the properties of the underlying visual-language foundation model, and leveraging Bayesian updating to aggregate multiple observations of the scene. The result is Bayesian Fields, a task-driven and probabilistic approach for open-set semantic mapping. To enable high-fidelity objects and a dense scene representation, Bayesian Fields uses 3D Gaussians which we cluster into task-relevant objects, allowing for both easy 3D object extraction and reduced memory usage. We release Bayesian Fields open-source at https: //github.com/MIT-SPARK/Bayesian-Fields.