D2GV: Deformable 2D Gaussian Splatting for Video Representation in 400FPS
作者: Mufan Liu, Qi Yang, Miaoran Zhao, He Huang, Le Yang, Zhu Li, Yiling Xu
分类: cs.CV
发布日期: 2025-03-07
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于可变形2D高斯溅射的D2GV视频表示方法,实现400FPS高效高质量渲染。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频表示 可变形高斯溅射 实时渲染 视频压缩 视频修复 CUDA加速 隐式神经表示
📋 核心要点
- 现有隐式神经表示(INR)方法在视频表示中存在效率和可解释性不足的挑战,限制了其作为通用解决方案的实用性。
- D2GV通过可变形的2D高斯溅射来表示视频帧,利用高效的CUDA栅格化实现快速渲染和高质量的视频重建。
- 实验表明,D2GV在视频插值、修复和去噪等任务中表现出色,并能以超过400FPS的速度解码,同时保持或超越现有INR方法的质量。
📝 摘要(中文)
本文提出了一种新颖的基于可变形2D高斯溅射的视频表示方法,称为D2GV。该方法旨在实现三个关键目标:1) 在提供卓越质量的同时提高效率;2) 增强可扩展性和可解释性;3) 提高对下游任务的友好性。具体来说,D2GV首先将视频序列分成固定长度的图片组(GoP),以允许并行训练和视频长度的线性可扩展性。对于每个GoP,D2GV通过将可微栅格化应用于2D高斯来表示视频帧,这些高斯从规范空间变形到其对应的时间戳。值得注意的是,利用高效的基于CUDA的栅格化,D2GV能够快速收敛并以超过400 FPS的速度解码,同时提供与最先进的INRs相匹配或超过的质量。此外,我们还结合了一种可学习的剪枝和量化策略,以将D2GV简化为更紧凑的表示。我们在视频插值、修复和去噪等任务中展示了D2GV的多功能性,突显了其作为一种有前途的视频表示解决方案的潜力。
🔬 方法详解
问题定义:现有基于隐式神经表示(INR)的视频表示方法,虽然在视频压缩和修复等任务中展现出潜力,但其隐式特性导致计算效率较低,难以解释,并且不利于下游任务的应用。因此,如何设计一种高效、可解释且易于使用的视频表示方法是一个关键问题。
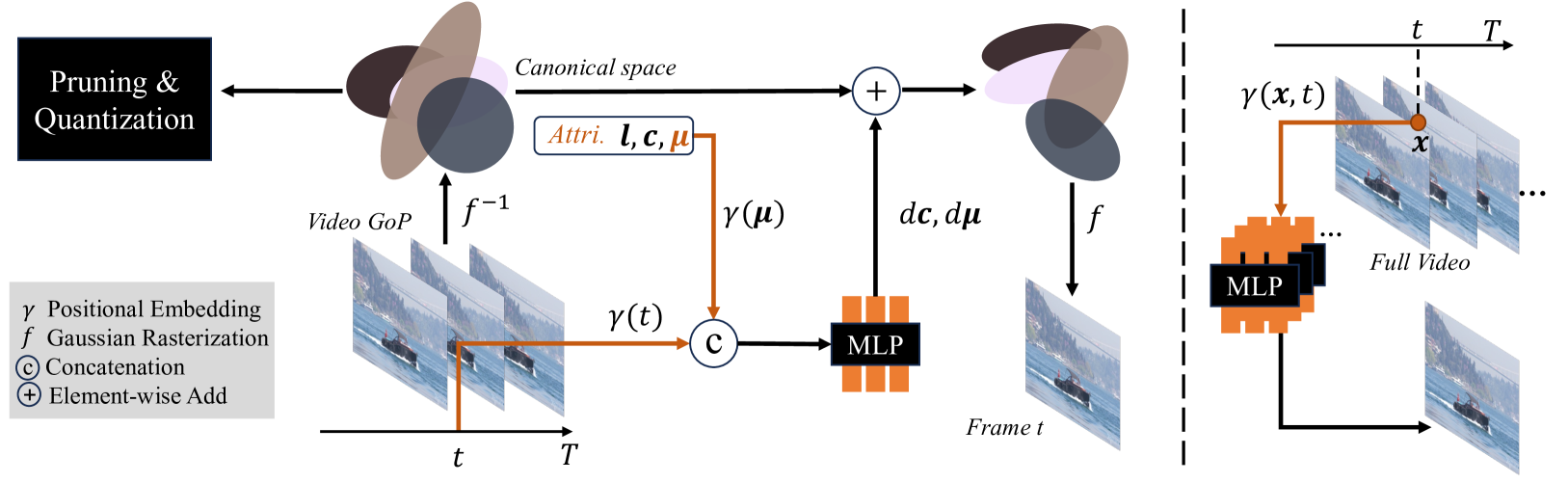
核心思路:D2GV的核心思路是利用可变形的2D高斯溅射来显式地表示视频帧。通过将视频分割成图片组(GoP),并为每个GoP学习一组可变形的2D高斯,可以实现并行训练和线性扩展性。这种显式表示方式不仅提高了渲染效率,还增强了模型的可解释性,并为下游任务提供了更友好的接口。
技术框架:D2GV的整体框架包括以下几个主要阶段:1) 视频分割成固定长度的GoP;2) 为每个GoP初始化一组2D高斯;3) 通过可微栅格化将2D高斯变形到对应的时间戳,生成视频帧;4) 使用损失函数优化高斯参数和变形参数,以最小化重建误差;5) 可选的剪枝和量化步骤,用于压缩模型大小。
关键创新:D2GV最重要的创新点在于使用可变形的2D高斯溅射来表示视频。与传统的INR方法相比,D2GV采用显式表示,避免了复杂的网络结构和迭代优化过程,从而显著提高了渲染效率。此外,D2GV还引入了可学习的剪枝和量化策略,进一步压缩模型大小,使其更易于部署。
关键设计:D2GV的关键设计包括:1) 使用CUDA加速的栅格化算法,实现高效的渲染;2) 设计合适的损失函数,例如L1或L2损失,以最小化重建误差;3) 采用可学习的剪枝和量化策略,平衡模型大小和性能;4) 针对不同的下游任务,设计相应的网络结构和损失函数。
🖼️ 关键图片


📊 实验亮点
D2GV在多个视频处理任务中表现出色。实验结果表明,D2GV能够以超过400 FPS的速度解码视频,同时在视频插值、修复和去噪等任务中,其性能与最先进的INR方法相匹配或超过。此外,D2GV还通过可学习的剪枝和量化策略,实现了模型大小的有效压缩。
🎯 应用场景
D2GV具有广泛的应用前景,包括视频压缩、视频编辑(如插值、修复、去噪)、虚拟现实/增强现实(VR/AR)中的实时渲染、以及视频监控等领域。其高效的渲染速度和高质量的重建效果使其成为一种有竞争力的视频表示方法,有望在未来的视频处理应用中发挥重要作用。
📄 摘要(原文)
Implicit Neural Representations (INRs) have emerged as a powerful approach for video representation, offering versatility across tasks such as compression and inpainting. However, their implicit formulation limits both interpretability and efficacy, undermining their practicality as a comprehensive solution. We propose a novel video representation based on deformable 2D Gaussian splatting, dubbed D2GV, which aims to achieve three key objectives: 1) improved efficiency while delivering superior quality; 2) enhanced scalability and interpretability; and 3) increased friendliness for downstream tasks. Specifically, we initially divide the video sequence into fixed-length Groups of Pictures (GoP) to allow parallel training and linear scalability with video length. For each GoP, D2GV represents video frames by applying differentiable rasterization to 2D Gaussians, which are deformed from a canonical space into their corresponding timestamps. Notably, leveraging efficient CUDA-based rasterization, D2GV converges fast and decodes at speeds exceeding 400 FPS, while delivering quality that matches or surpasses state-of-the-art INRs. Moreover, we incorporate a learnable pruning and quantization strategy to streamline D2GV into a more compact representation. We demonstrate D2GV's versatility in tasks including video interpolation, inpainting and denoising, underscoring its potential as a promising solution for video representation. Code is available at: https://github.com/Evan-sudo/D2GV.