Novel Object 6D Pose Estimation with a Single Reference View
作者: Jian Liu, Wei Sun, Kai Zeng, Jin Zheng, Hui Yang, Hossein Rahmani, Ajmal Mian, Lin Wang
分类: cs.CV, cs.RO
发布日期: 2025-03-07 (更新: 2025-10-06)
备注: 17 pages, 12 figures (including supplementary material)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于单参考视图和状态空间模型的SinRef-6D新物体6D位姿估计方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6D位姿估计 单参考视图 状态空间模型 新物体识别 点云配准
📋 核心要点
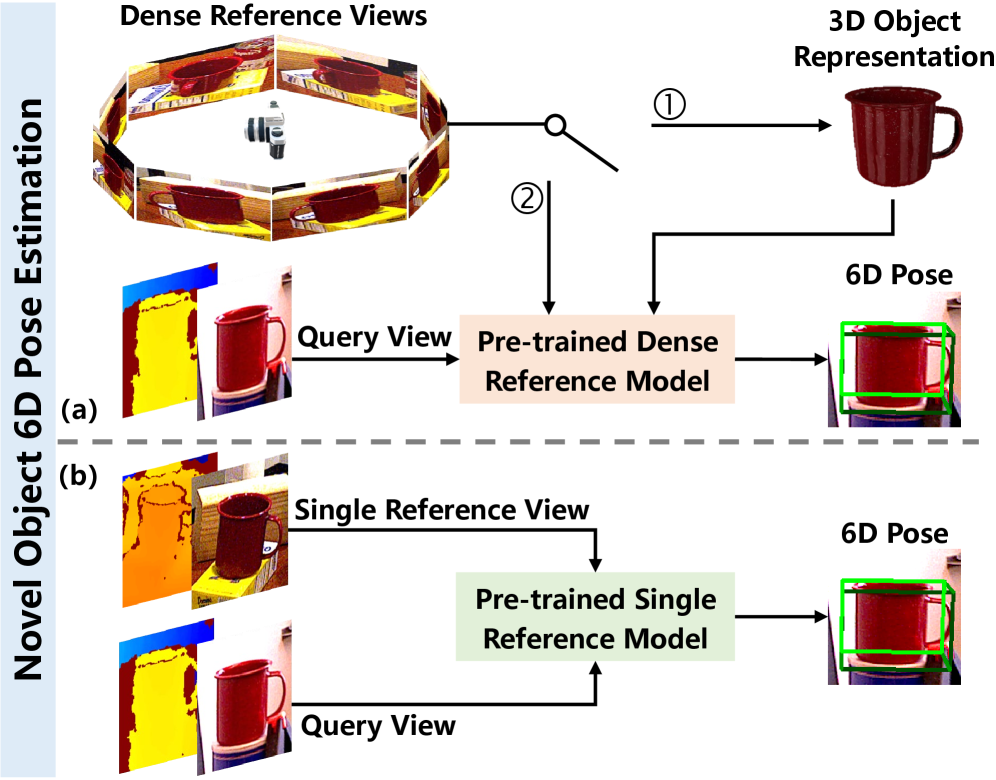
- 现有方法依赖CAD模型或密集参考视图,获取成本高昂,限制了新物体6D位姿估计的实际应用。
- SinRef-6D通过迭代对象空间点对齐和RGB/Points SSM,有效处理大位姿差异和有限信息问题。
- 实验表明,SinRef-6D在单参考视图下,性能与CAD模型或密集参考视图方法相当,具有实用价值。
📝 摘要(中文)
现有的新物体6D位姿估计方法通常依赖于CAD模型或密集的参考视图,而这两者都难以获取。仅使用单个参考视图更具可扩展性,但由于大的位姿差异以及有限的几何和空间信息而具有挑战性。为了解决这些问题,我们提出了一种基于单参考的SinRef-6D位姿估计方法。我们的核心思想是基于状态空间模型(SSM)在公共坐标系中迭代地建立点对齐。具体而言,迭代的对象空间点对齐可以有效地处理大的位姿差异,而我们提出的RGB和Points SSM可以从单个视图中捕获长程依赖关系和空间信息,从而提供线性复杂度和卓越的空间建模能力。一旦在合成数据上进行预训练,SinRef-6D就可以仅使用单个参考视图来估计新物体的6D位姿,而无需重新训练或CAD模型。在六个流行数据集和真实机器人场景中的大量实验表明,尽管在更具挑战性的单参考设置中运行,但我们实现了与基于CAD和基于密集参考视图的方法相当的性能。代码将在https://github.com/CNJianLiu/SinRef-6D上发布。
🔬 方法详解
问题定义:现有新物体6D位姿估计方法主要依赖CAD模型或大量参考视图,这两种方式都存在局限性。CAD模型难以获取,且模型质量直接影响估计精度;大量参考视图则增加了数据采集和存储的成本。因此,如何在仅有单个参考视图的情况下,准确估计新物体的6D位姿,是一个具有挑战性的问题。
核心思路:SinRef-6D的核心思路是利用单张参考视图,通过迭代的点对齐和状态空间模型,逐步缩小目标物体与参考物体之间的位姿差异。通过在公共坐标系下建立点对应关系,并利用状态空间模型捕获长程依赖和空间信息,从而实现准确的位姿估计。这种方法避免了对CAD模型或大量参考视图的依赖,提高了算法的实用性和可扩展性。
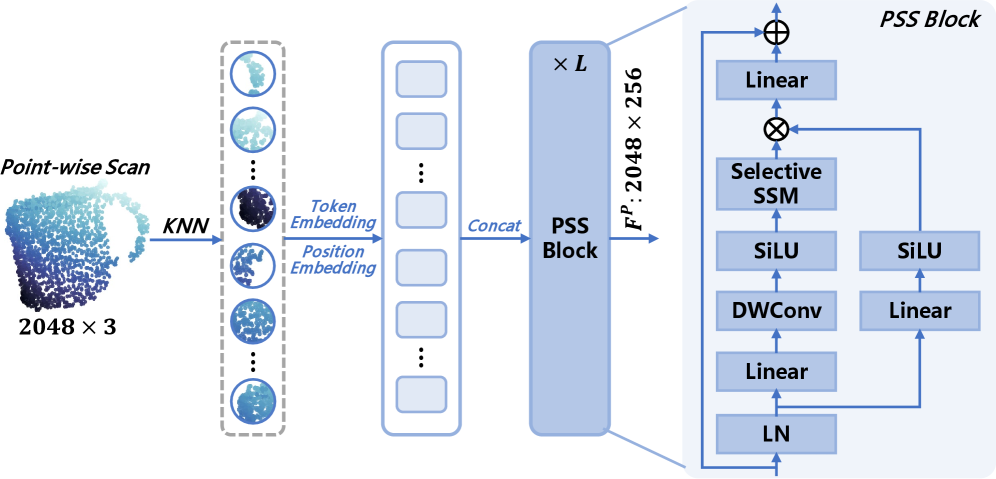
技术框架:SinRef-6D的整体框架包含以下几个主要阶段:1) 特征提取:从参考视图和目标视图中提取RGB和点云特征。2) 状态空间建模:利用RGB和Points SSM对提取的特征进行建模,捕获长程依赖和空间信息。3) 迭代点对齐:在公共坐标系下,通过迭代的方式建立参考视图和目标视图之间的点对应关系,逐步优化位姿估计。4) 位姿优化:利用建立的点对应关系,优化目标物体的6D位姿。
关键创新:SinRef-6D的关键创新在于:1) 提出了基于单参考视图的6D位姿估计方法,降低了对数据依赖性。2) 引入了RGB和Points SSM,有效捕获了单视图中的长程依赖和空间信息,提升了位姿估计的准确性。3) 采用了迭代的点对齐策略,能够有效处理大的位姿差异。
关键设计:RGB和Points SSM的具体实现细节未知,论文中可能包含网络结构、损失函数和训练策略等关键设计。迭代点对齐的具体算法,例如ICP的变种,以及位姿优化的损失函数,也是影响算法性能的关键因素。这些细节需要在论文原文中进一步查找。
🖼️ 关键图片

📊 实验亮点
SinRef-6D在六个流行数据集和真实机器人场景中进行了广泛的实验,结果表明,在单参考视图的条件下,SinRef-6D的性能与基于CAD模型和基于密集参考视图的方法相当。这表明SinRef-6D在降低数据依赖性的同时,仍然能够保持较高的位姿估计精度。
🎯 应用场景
SinRef-6D在机器人操作、增强现实、自动驾驶等领域具有广泛的应用前景。例如,在机器人操作中,机器人可以利用单张图像识别并抓取未知的物体;在增强现实中,可以将虚拟物体准确地叠加到真实场景中的物体上;在自动驾驶中,可以识别并跟踪道路上的新物体。
📄 摘要(原文)
Existing novel object 6D pose estimation methods typically rely on CAD models or dense reference views, which are both difficult to acquire. Using only a single reference view is more scalable, but challenging due to large pose discrepancies and limited geometric and spatial information. To address these issues, we propose a Single-Reference-based novel object 6D (SinRef-6D) pose estimation method. Our key idea is to iteratively establish point-wise alignment in a common coordinate system based on state space models (SSMs). Specifically, iterative object-space point-wise alignment can effectively handle large pose discrepancies, while our proposed RGB and Points SSMs can capture long-range dependencies and spatial information from a single view, offering linear complexity and superior spatial modeling capability. Once pre-trained on synthetic data, SinRef-6D can estimate the 6D pose of a novel object using only a single reference view, without requiring retraining or a CAD model. Extensive experiments on six popular datasets and real-world robotic scenes demonstrate that we achieve on-par performance with CAD-based and dense reference view-based methods, despite operating in the more challenging single reference setting. Code will be released at https://github.com/CNJianLiu/SinRef-6D.