Stereo Any Video: Temporally Consistent Stereo Matching
作者: Junpeng Jing, Weixun Luo, Ye Mao, Krystian Mikolajczyk
分类: cs.CV
发布日期: 2025-03-07 (更新: 2025-07-21)
备注: ICCV2025
💡 一句话要点
提出Stereo Any Video框架,无需辅助信息实现时序一致的视频立体匹配
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视频立体匹配 深度估计 时间一致性 单目深度先验 全对全相关性
📋 核心要点
- 现有视频立体匹配方法依赖相机位姿或光流等辅助信息,限制了其应用范围和鲁棒性。
- Stereo Any Video框架融合单目深度先验和卷积特征,并引入全对全相关性和时间凸上采样,提升匹配质量。
- 实验表明,该方法在多个数据集上取得了SOTA性能,并在真实场景中展现出强大的泛化能力。
📝 摘要(中文)
本文介绍了一种强大的视频立体匹配框架Stereo Any Video。该框架无需相机位姿或光流等辅助信息,即可估计空间精确且时间一致的视差。其强大的能力源于单目视频深度模型的丰富先验知识,这些先验与卷积特征相结合,产生稳定的表示。为了进一步提高性能,本文引入了关键的架构创新:全对全相关性,构建平滑且鲁棒的匹配代价体;以及时间凸上采样,提高时间一致性。这些组件共同确保了鲁棒性、准确性和时间一致性,为视频立体匹配设定了新的标准。大量实验表明,我们的方法在多个数据集上实现了最先进的性能,在零样本设置中表现出色,并且对真实世界的室内和室外场景具有很强的泛化能力。
🔬 方法详解
问题定义:视频立体匹配旨在从视频序列中估计每个像素的视差,从而恢复场景的3D结构。现有的视频立体匹配方法通常依赖于相机位姿信息或光流等辅助信息来提高时间一致性,这限制了它们在缺乏这些信息的场景中的应用,同时也增加了系统的复杂性。此外,现有方法在处理遮挡、纹理缺失等问题时,鲁棒性较差。
核心思路:本文的核心思路是利用单目视频深度模型的先验知识来指导立体匹配过程。单目深度模型能够提供场景的粗略深度信息,这可以帮助缩小搜索范围,提高匹配的准确性和鲁棒性。此外,通过引入全对全相关性和时间凸上采样等技术,可以进一步提高匹配的时间一致性。
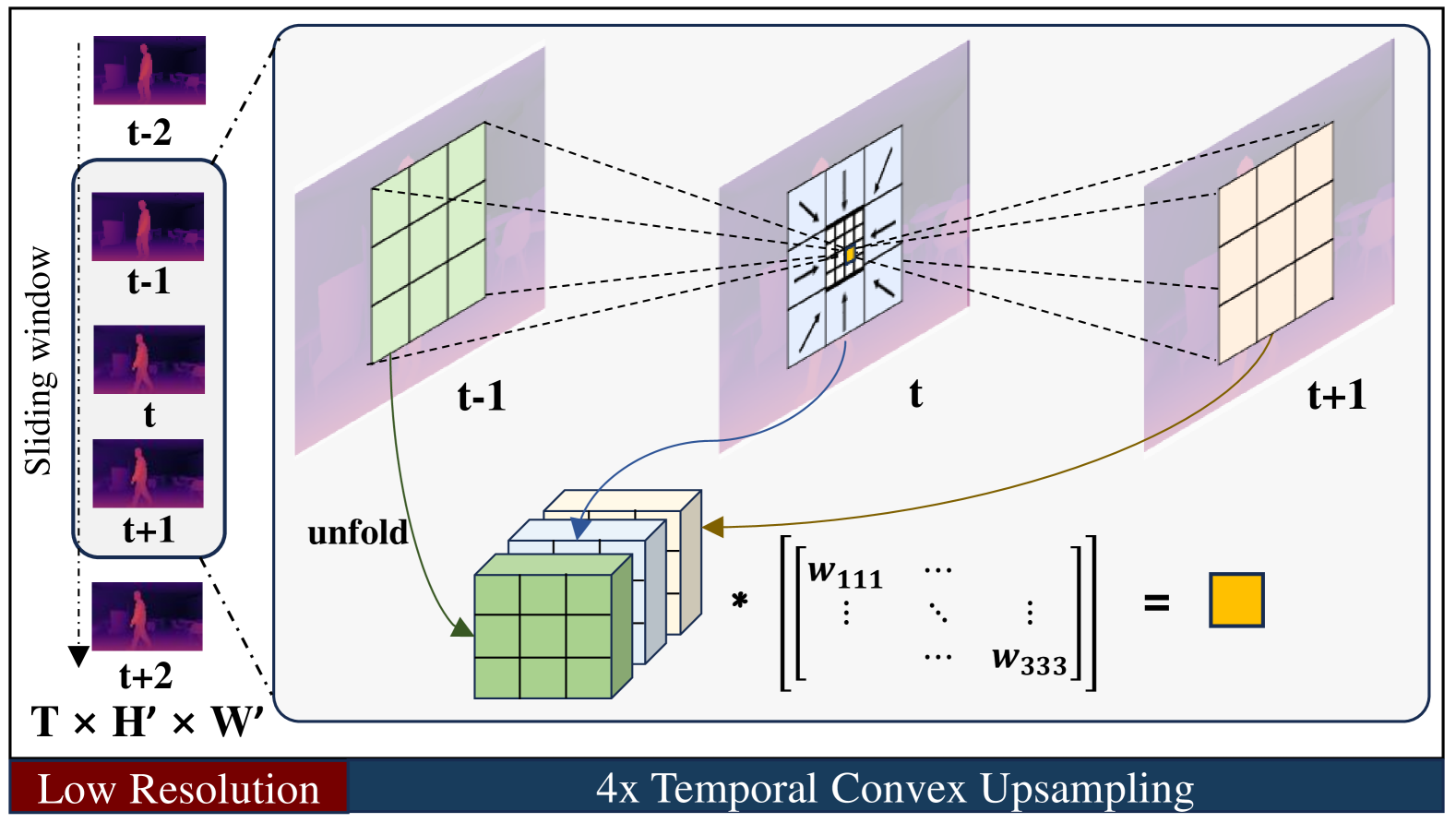
技术框架:Stereo Any Video框架主要包含以下几个模块:1) 特征提取模块:使用卷积神经网络提取左右图像的特征。2) 单目深度先验模块:利用预训练的单目深度模型估计左右图像的深度图,作为先验信息。3) 代价体构建模块:通过计算左右图像特征之间的相关性来构建代价体,并融合单目深度先验信息。4) 视差估计模块:使用3D卷积神经网络对代价体进行处理,估计视差图。5) 时间一致性优化模块:采用时间凸上采样方法,对视差图进行时间上的平滑和优化。
关键创新:本文最重要的技术创新点在于:1) 将单目深度先验知识引入到视频立体匹配中,提高了匹配的准确性和鲁棒性。2) 提出了全对全相关性,能够构建更平滑和鲁棒的匹配代价体。3) 提出了时间凸上采样,能够有效地提高视差图的时间一致性。与现有方法相比,该方法无需相机位姿或光流等辅助信息,即可实现高质量的视频立体匹配。
关键设计:在代价体构建模块中,采用了全对全相关性,即计算所有像素对之间的相关性,而不是像传统方法那样只计算局部窗口内的相关性。在时间凸上采样模块中,采用了凸优化的方法来保证视差图的时间一致性,并使用可学习的权重来平衡不同时间步的视差信息。
🖼️ 关键图片


📊 实验亮点
该方法在多个数据集上取得了state-of-the-art的性能,例如在KITTI数据集上,其视差估计的平均误差显著低于现有方法。此外,该方法在真实世界的室内和室外场景中也表现出强大的泛化能力,证明了其在实际应用中的潜力。零样本实验结果也表明了该方法对未见过的场景具有良好的适应性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、虚拟现实、增强现实等领域。在自动驾驶中,可以利用该方法从车载摄像头拍摄的视频中恢复场景的3D结构,从而提高车辆的感知能力。在机器人导航中,可以帮助机器人更好地理解周围环境,实现自主导航。在虚拟现实和增强现实中,可以提供更逼真的3D体验。
📄 摘要(原文)
This paper introduces Stereo Any Video, a powerful framework for video stereo matching. It can estimate spatially accurate and temporally consistent disparities without relying on auxiliary information such as camera poses or optical flow. The strong capability is driven by rich priors from monocular video depth models, which are integrated with convolutional features to produce stable representations. To further enhance performance, key architectural innovations are introduced: all-to-all-pairs correlation, which constructs smooth and robust matching cost volumes, and temporal convex upsampling, which improves temporal coherence. These components collectively ensure robustness, accuracy, and temporal consistency, setting a new standard in video stereo matching. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple datasets both qualitatively and quantitatively in zero-shot settings, as well as strong generalization to real-world indoor and outdoor scenarios.