Robust Multimodal Learning for Ophthalmic Disease Grading via Disentangled Representation
作者: Xinkun Wang, Yifang Wang, Senwei Liang, Feilong Tang, Chengzhi Liu, Ming Hu, Chao Hu, Junjun He, Zongyuan Ge, Imran Razzak
分类: cs.CV, cs.AI
发布日期: 2025-03-07 (更新: 2025-06-25)
备注: 10pages
💡 一句话要点
提出EDRL框架,通过解耦表征实现鲁棒的多模态眼科疾病分级
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 眼科疾病分级 解耦表征 自蒸馏 特征选择 鲁棒性 深度学习
📋 核心要点
- 现有方法在处理多模态眼科数据时,易受冗余信息干扰,且模态间表征存在纠缠,影响疾病分级准确性。
- EDRL框架通过本质点学习选择判别性特征,并利用解耦表征学习分离模态通用和模态独特的特征。
- 实验结果表明,EDRL在多模态眼科数据集上显著优于现有方法,提升了疾病分级性能。
📝 摘要(中文)
本文探讨了眼科医生如何利用多模态数据来提高诊断准确性。然而,由于医疗设备缺乏和数据隐私问题,完整的多模态数据在实际应用中很少见。传统的深度学习方法通常通过在潜在空间中学习表征来解决这些问题。但是,本文强调了这些方法的两个主要局限性:(i)复杂模态中与任务无关的冗余信息(例如,大量切片)导致潜在空间表征中存在显著的冗余。(ii)重叠的多模态表征使得难以提取每个模态的独特特征。为了克服这些挑战,作者提出了一种本质点和解耦表征学习(EDRL)策略,该策略将自蒸馏机制集成到端到端框架中,以增强特征选择和解耦,从而实现更鲁棒的多模态学习。具体来说,本质点表征学习模块选择判别性特征,从而提高疾病分级性能。解耦表征学习模块将多模态数据分离为模态通用和模态独特的表征,减少特征纠缠,并增强眼科疾病诊断的鲁棒性和可解释性。在多模态眼科数据集上的实验表明,所提出的EDRL策略显著优于当前最先进的方法。
🔬 方法详解
问题定义:论文旨在解决多模态眼科图像疾病分级中,由于模态数据冗余和模态间特征纠缠导致的性能瓶颈问题。现有方法难以有效提取各模态的独特信息,且易受无关信息干扰,导致分级精度不高。
核心思路:论文的核心思路是通过解耦多模态表征,将模态通用和模态独特的特征分离,并利用自蒸馏机制选择最具判别性的特征,从而提高疾病分级的鲁棒性和准确性。这种设计旨在减少模态间的干扰,并专注于对疾病诊断至关重要的特征。
技术框架:EDRL框架包含两个主要模块:本质点表征学习(Essence-Point Representation Learning)和解耦表征学习(Disentangled Representation Learning)。本质点表征学习模块通过自蒸馏机制选择判别性特征,减少冗余信息的影响。解耦表征学习模块将多模态数据分解为模态通用和模态独特的表征,降低特征纠缠。整个框架以端到端的方式进行训练。
关键创新:该论文的关键创新在于同时实现了特征选择和表征解耦。传统的自蒸馏方法通常只关注特征选择,而EDRL框架通过解耦表征学习,进一步提高了模型对不同模态信息的利用效率。这种结合使得模型能够更好地处理复杂的多模态数据,并提取更具判别性的特征。
关键设计:本质点表征学习模块使用自蒸馏损失函数,鼓励模型学习更紧凑和具有判别性的特征表示。解耦表征学习模块可能使用了对抗训练或信息瓶颈等技术,以确保模态通用和模态独特的表征尽可能地相互独立。具体的网络结构和参数设置在论文中应该有详细描述,但摘要中未提及。
🖼️ 关键图片


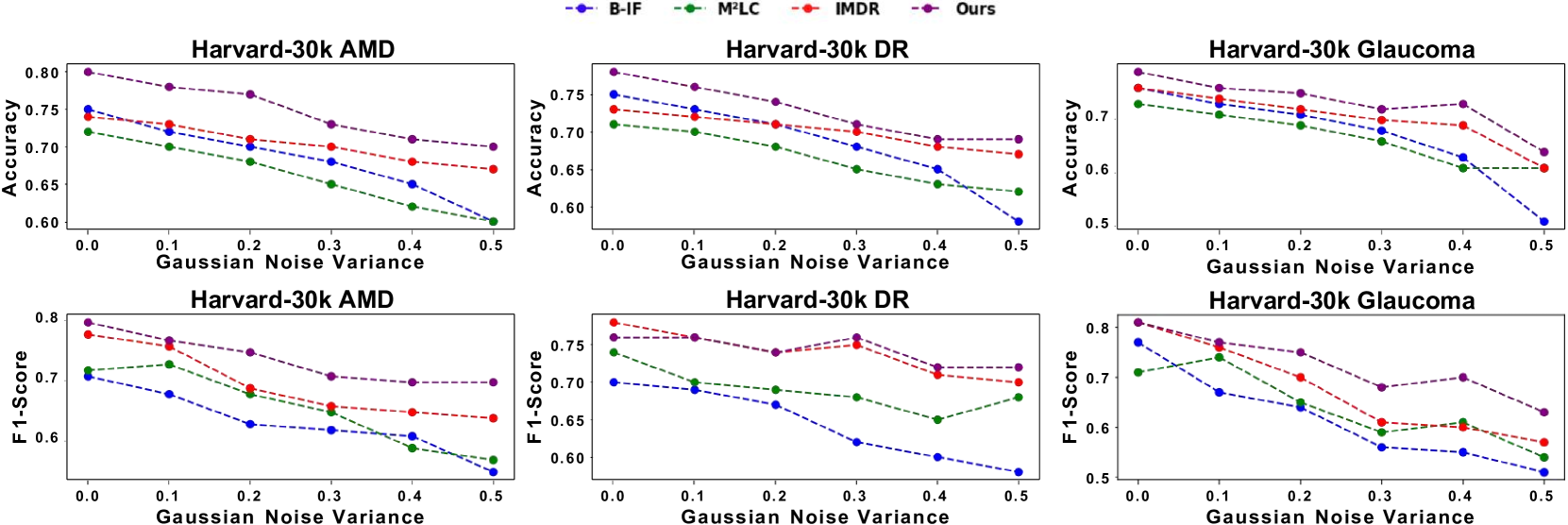
📊 实验亮点
论文提出的EDRL策略在多模态眼科数据集上取得了显著的性能提升,超越了当前最先进的方法。具体的性能数据和对比基线需要在论文中查找,但摘要强调了EDRL在疾病分级任务上的优越性,表明其在处理多模态眼科数据方面的有效性。
🎯 应用场景
该研究成果可应用于眼科疾病的辅助诊断,帮助医生更准确地进行疾病分级和诊断,尤其是在多模态数据可用的情况下。该方法可以减少对完整多模态数据的依赖,提高在数据缺失情况下的诊断准确性,具有重要的临床应用价值和潜力。
📄 摘要(原文)
This paper discusses how ophthalmologists often rely on multimodal data to improve diagnostic accuracy. However, complete multimodal data is rare in real-world applications due to a lack of medical equipment and concerns about data privacy. Traditional deep learning methods typically address these issues by learning representations in latent space. However, the paper highlights two key limitations of these approaches: (i) Task-irrelevant redundant information (e.g., numerous slices) in complex modalities leads to significant redundancy in latent space representations. (ii) Overlapping multimodal representations make it difficult to extract unique features for each modality. To overcome these challenges, the authors propose the Essence-Point and Disentangle Representation Learning (EDRL) strategy, which integrates a self-distillation mechanism into an end-to-end framework to enhance feature selection and disentanglement for more robust multimodal learning. Specifically, the Essence-Point Representation Learning module selects discriminative features that improve disease grading performance. The Disentangled Representation Learning module separates multimodal data into modality-common and modality-unique representations, reducing feature entanglement and enhancing both robustness and interpretability in ophthalmic disease diagnosis. Experiments on multimodal ophthalmology datasets show that the proposed EDRL strategy significantly outperforms current state-of-the-art methods.