Escaping Plato's Cave: Towards the Alignment of 3D and Text Latent Spaces
作者: Souhail Hadgi, Luca Moschella, Andrea Santilli, Diego Gomez, Qixing Huang, Emanuele Rodolà, Simone Melzi, Maks Ovsjanikov
分类: cs.CV
发布日期: 2025-03-07 (更新: 2025-06-04)
备注: CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种3D和文本隐空间对齐方法,通过子空间投影提升跨模态检索性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 三维模型 文本对齐 跨模态检索 子空间学习 特征表示
📋 核心要点
- 现有3D基础模型通常采用显式对齐目标,依赖于其他模态的预训练编码器,缺乏对单模态3D编码器自身特征空间的探索。
- 该论文的核心思想是提取3D和文本特征空间的子空间,并在这些子空间中进行对齐,从而提高跨模态匹配和检索的性能。
- 实验结果表明,通过子空间投影,3D和文本特征的对齐质量显著提高,在匹配和检索任务中取得了更好的准确性。
📝 摘要(中文)
本文探索了单模态3D编码器与文本特征空间进行后验对齐的可能性。研究表明,直接对单模态文本和3D编码器进行特征对齐效果有限。因此,本文着重于提取对应特征空间的子空间,并发现通过将学习到的表示投影到精心选择的低维子空间上,对齐质量显著提高,从而改善了匹配和检索任务的准确性。进一步的分析揭示了这些共享子空间的本质,它们大致区分了语义和几何数据表示。总而言之,本文首次为3D单模态和文本特征空间的后训练对齐建立了一个基线,并有助于突出3D数据与其他表示相比的共享和独特属性。
🔬 方法详解
问题定义:现有方法在对齐3D和文本特征空间时,通常依赖于预训练的其他模态编码器,或者采用显式的对齐目标进行训练。这限制了对单模态3D编码器自身学习到的特征空间的探索,并且直接对齐可能受到噪声和冗余信息的影响。因此,需要一种有效的方法来对齐单模态3D和文本特征空间,并提高跨模态检索的性能。
核心思路:该论文的核心思路是,并非所有特征维度都对跨模态对齐有益,因此通过提取和对齐特征空间的子空间,可以过滤掉噪声和冗余信息,从而提高对齐质量。具体来说,论文假设存在一个低维子空间,在这个子空间中,3D和文本特征具有更好的相关性。
技术框架:整体框架包括以下几个步骤:1) 使用单模态3D编码器和文本编码器分别提取3D形状和文本描述的特征;2) 使用主成分分析(PCA)等方法,从3D和文本特征空间中提取低维子空间;3) 将3D和文本特征投影到对应的子空间中;4) 在子空间中进行特征对齐,例如使用对比学习损失函数;5) 使用对齐后的特征进行跨模态匹配和检索。
关键创新:该论文的关键创新在于,提出了基于子空间投影的3D和文本特征对齐方法。与直接对齐原始特征空间相比,该方法能够更有效地过滤掉噪声和冗余信息,从而提高对齐质量。此外,论文还分析了共享子空间的性质,发现它们大致区分了语义和几何数据表示。
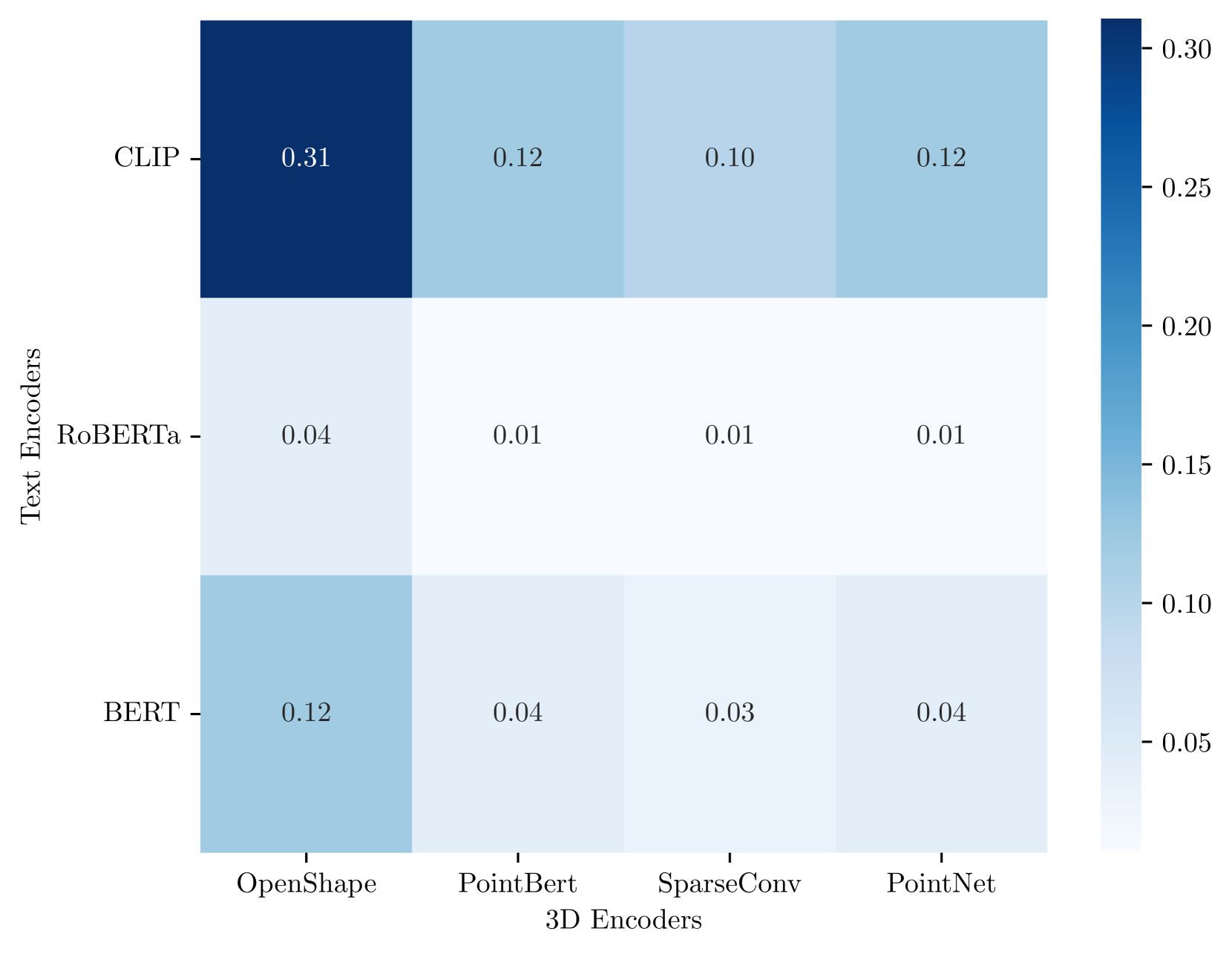
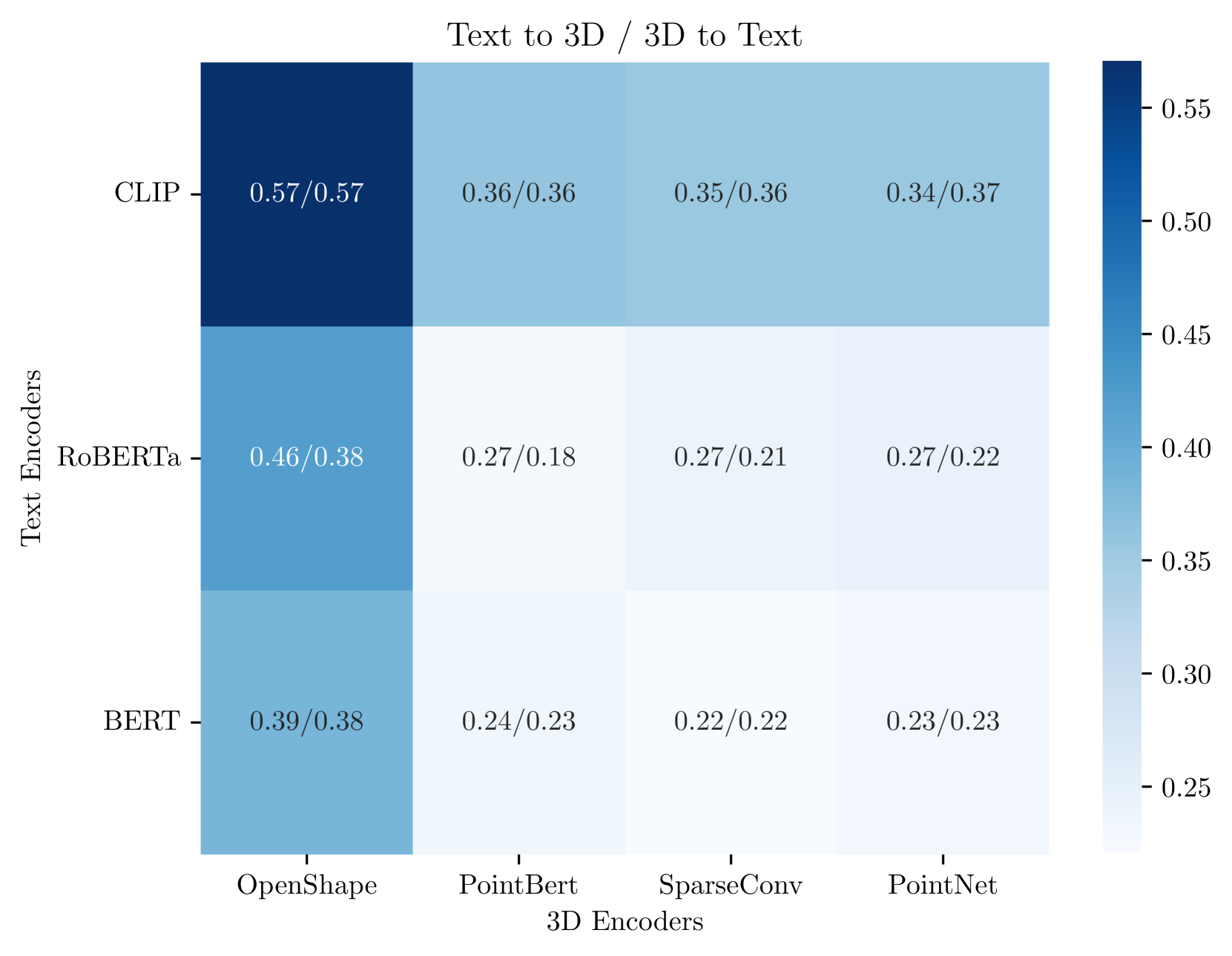
关键设计:论文中使用了预训练的3D和文本编码器,例如PointNet++和BERT。子空间的提取使用了PCA,但也可以尝试其他降维方法。对齐损失函数使用了对比学习损失,目标是拉近相同语义的3D形状和文本描述在子空间中的距离,同时推远不同语义的样本。实验中,作者探索了不同子空间的维度,并发现合适的维度可以显著提高对齐效果。
🖼️ 关键图片
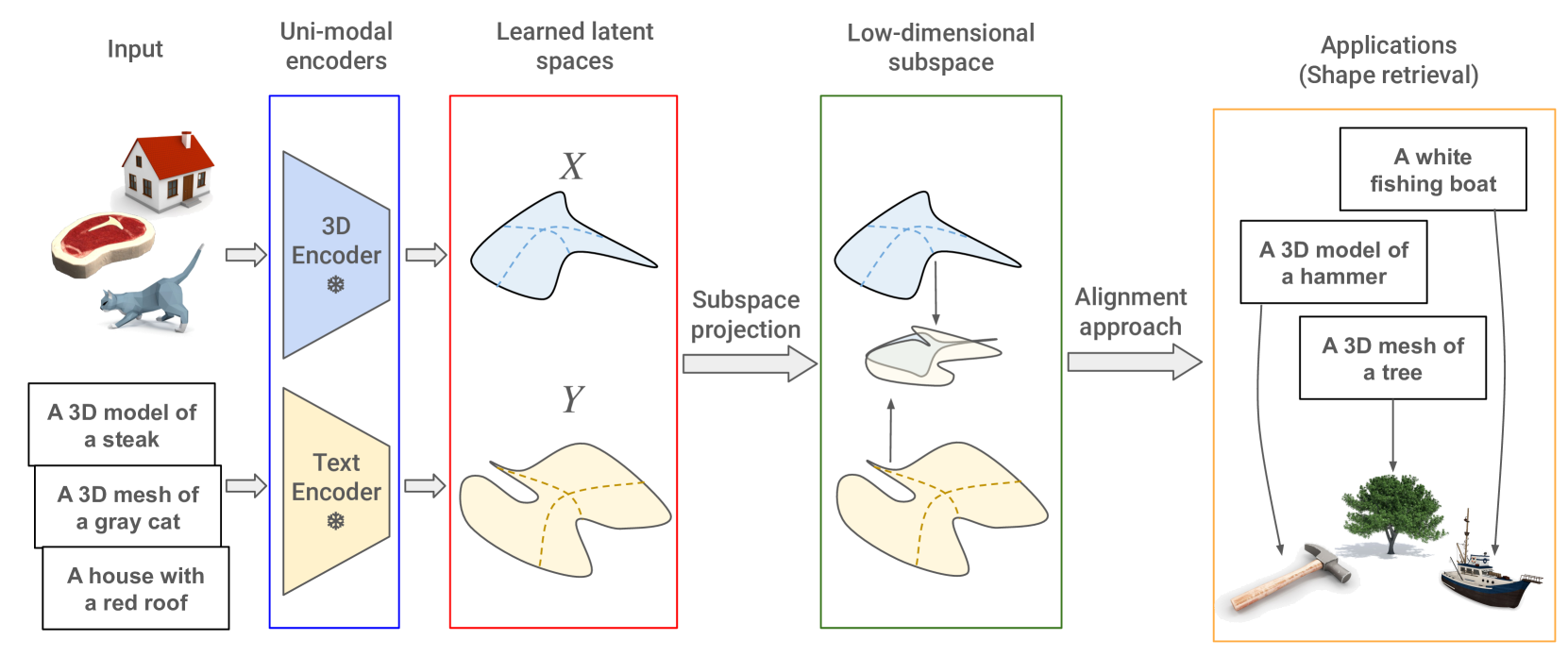
📊 实验亮点
实验结果表明,通过子空间投影,3D和文本特征的对齐质量显著提高。在ShapeNet数据集上的检索任务中,该方法取得了比直接对齐原始特征空间更好的性能。例如,在Text-to-Shape检索任务中,Recall@1指标提升了显著幅度(具体数值未知)。
🎯 应用场景
该研究成果可应用于三维模型检索、三维场景理解、机器人导航等领域。例如,可以通过文本描述检索相关的三维模型,或者利用三维场景信息辅助机器人理解环境。此外,该方法还可以扩展到其他模态,例如图像和音频,实现更广泛的跨模态理解和应用。
📄 摘要(原文)
Recent works have shown that, when trained at scale, uni-modal 2D vision and text encoders converge to learned features that share remarkable structural properties, despite arising from different representations. However, the role of 3D encoders with respect to other modalities remains unexplored. Furthermore, existing 3D foundation models that leverage large datasets are typically trained with explicit alignment objectives with respect to frozen encoders from other representations. In this work, we investigate the possibility of a posteriori alignment of representations obtained from uni-modal 3D encoders compared to text-based feature spaces. We show that naive post-training feature alignment of uni-modal text and 3D encoders results in limited performance. We then focus on extracting subspaces of the corresponding feature spaces and discover that by projecting learned representations onto well-chosen lower-dimensional subspaces the quality of alignment becomes significantly higher, leading to improved accuracy on matching and retrieval tasks. Our analysis further sheds light on the nature of these shared subspaces, which roughly separate between semantic and geometric data representations. Overall, ours is the first work that helps to establish a baseline for post-training alignment of 3D uni-modal and text feature spaces, and helps to highlight both the shared and unique properties of 3D data compared to other representations. Our code and weights are available at https://github.com/Souhail-01/3d-text-alignment