CMMCoT: Enhancing Complex Multi-Image Comprehension via Multi-Modal Chain-of-Thought and Memory Augmentation
作者: Guanghao Zhang, Tao Zhong, Yan Xia, Mushui Liu, Zhelun Yu, Haoyuan Li, Wanggui He, Fangxun Shu, Dong She, Yi Wang, Hao Jiang
分类: cs.CV
发布日期: 2025-03-07 (更新: 2025-12-04)
备注: Accepted by AAAI 2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出CMMCoT框架,通过多模态思维链和记忆增强提升复杂多图理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多图理解 多模态学习 思维链 记忆增强 视觉推理
📋 核心要点
- 现有方法在多图理解中过度依赖文本推理,忽略了跨图视觉比较和动态记忆关键视觉概念。
- CMMCoT框架通过构建交错的多模态推理链和引入测试时记忆增强模块,模拟人类的慢思考过程。
- 实验结果表明,CMMCoT框架在多图理解任务上表现出显著的性能提升,验证了其有效性。
📝 摘要(中文)
现有的多模态慢思考方法在单图理解任务中表现出色,但扩展到复杂的多图理解任务时受到限制。这是因为它们主要依赖于基于文本的中间推理过程。人类在进行复杂的多图分析时,通常会执行两种互补的认知操作:(1) 通过感兴趣区域匹配进行连续的跨图视觉比较,以及 (2) 在整个推理链中动态记忆关键视觉概念。受此启发,我们提出了复杂多模态思维链(CMMCoT)框架,这是一个多步骤推理框架,模仿人类的“慢思考”来进行多图理解。我们的方法包含两个关键创新:(1) 构建交错的多模态多步骤推理链,利用从中间推理步骤中提取的关键视觉区域tokens作为监督信号,这不仅促进了全面的跨模态理解,还增强了模型的可解释性。(2) 引入了一种测试时记忆增强模块,该模块在推理过程中扩展了模型的推理能力,同时保持了参数效率。此外,为了促进这方面的研究,我们策划了一个新的多图慢思考数据集。大量的实验证明了我们模型的有效性。
🔬 方法详解
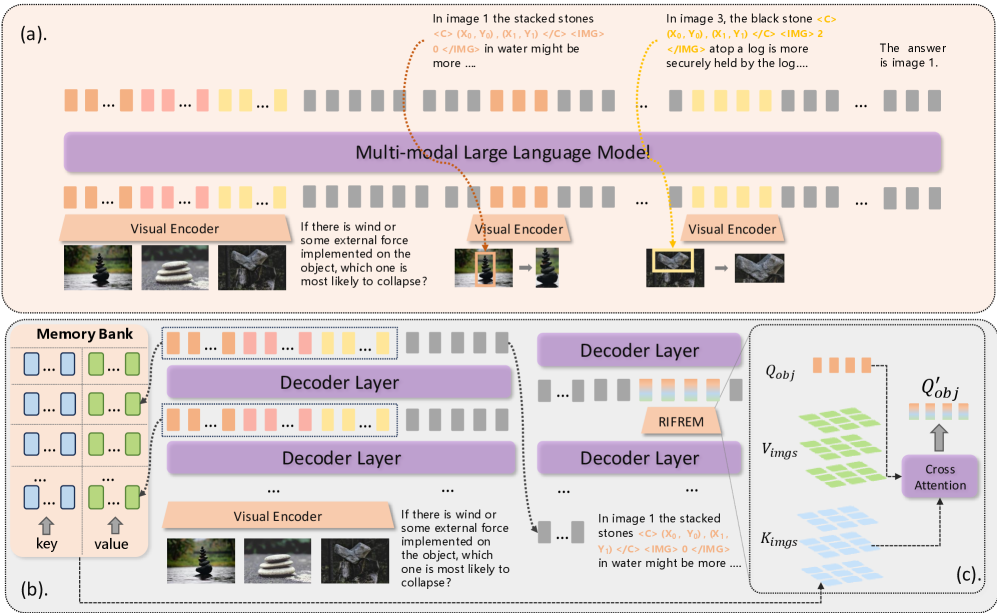
问题定义:现有方法在处理复杂多图理解任务时,过度依赖文本信息进行推理,忽略了人类在处理此类任务时重要的视觉认知过程,例如跨图像的视觉区域比较和对关键视觉概念的动态记忆。这导致模型在复杂场景下的理解能力受限,无法充分利用多图之间的关联信息。
核心思路:CMMCoT框架的核心思路是模仿人类在进行复杂多图理解时的“慢思考”过程,通过逐步推理和记忆关键视觉信息来提升模型的理解能力。具体来说,模型会逐步分析图像,提取关键视觉区域,并将其存储在记忆模块中,以便在后续的推理步骤中使用。
技术框架:CMMCoT框架包含两个主要模块:多模态多步骤推理链构建模块和测试时记忆增强模块。多模态多步骤推理链构建模块负责生成交错的多模态推理链,利用从中间推理步骤中提取的关键视觉区域tokens作为监督信号。测试时记忆增强模块则在推理过程中动态地扩展模型的推理能力,存储和检索关键视觉信息。
关键创新:CMMCoT框架的关键创新在于:(1) 提出了交错的多模态多步骤推理链,将视觉区域信息融入推理过程,增强了跨模态理解能力和模型可解释性;(2) 引入了测试时记忆增强模块,在不增加模型参数的情况下,提升了模型的推理能力。与现有方法相比,CMMCoT框架更注重模拟人类的视觉认知过程,从而更好地处理复杂多图理解任务。
关键设计:在多模态多步骤推理链构建中,论文使用关键视觉区域tokens作为监督信号,引导模型关注图像中的重要区域。测试时记忆增强模块的具体实现细节未知,但其目标是在推理过程中动态地存储和检索关键视觉信息,以提升模型的推理能力。损失函数的设计也未知,但推测会包含对中间推理步骤的监督,以及对记忆模块的约束。
🖼️ 关键图片


📊 实验亮点
论文提出了CMMCoT框架,并在一个新的多图慢思考数据集上进行了实验验证。实验结果表明,CMMCoT框架在多图理解任务上取得了显著的性能提升,证明了其有效性。具体的性能数据和对比基线未知,但论文强调了CMMCoT框架在提升模型理解能力和可解释性方面的优势。
🎯 应用场景
CMMCoT框架在需要理解多张图像之间复杂关系的任务中具有广泛的应用前景,例如医学影像诊断、遥感图像分析、视频监控等。通过提升模型的多图理解能力,可以帮助人们更准确地分析复杂场景,做出更明智的决策。该研究的未来影响在于推动多模态理解和推理技术的发展,使其能够更好地服务于实际应用。
📄 摘要(原文)
While previous multimodal slow-thinking methods have demonstrated remarkable success in single-image understanding scenarios, their effectiveness becomes fundamentally constrained when extended to more complex multi-image comprehension tasks. This limitation stems from their predominant reliance on text-based intermediate reasoning processes. While for human, when engaging in sophisticated multi-image analysis, they typically perform two complementary cognitive operations: (1) continuous cross-image visual comparison through region-of-interest matching, and (2) dynamic memorization of critical visual concepts throughout the reasoning chain. Motivated by these observations, we propose the Complex Multi-Modal Chain-of-Thought (CMMCoT) framework, a multi-step reasoning framework that mimics human-like "slow thinking" for multi-image understanding. Our approach incorporates two key innovations: (1) The construction of interleaved multimodal multi-step reasoning chains, which utilize critical visual region tokens, extracted from intermediate reasoning steps, as supervisory signals. This mechanism not only facilitates comprehensive cross-modal understanding but also enhances model interpretability. (2) The introduction of a test-time memory augmentation module that expands the model's reasoning capacity during inference while preserving parameter efficiency. Furthermore, to facilitate research in this direction, we have curated a novel multi-image slow-thinking dataset. Extensive experiments demonstrate the effectiveness of our model. Code is available at https://github.com/zhangguanghao523/CMMCoT.