HexPlane Representation for 3D Semantic Scene Understanding
作者: Zeren Chen, Yuenan Hou, Yulin Chen, Li Liu, Xiao Sun, Lu Sheng
分类: cs.CV, cs.AI
发布日期: 2025-03-07
备注: 7 pages, 2 figures
💡 一句话要点
提出HexPlane表示用于3D语义场景理解,提升分割精度。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D场景理解 语义分割 点云处理 HexPlane表示 视图投影
📋 核心要点
- 现有3D场景理解方法在处理稀疏和无序点云时效率较低,难以充分利用2D领域的成熟技术。
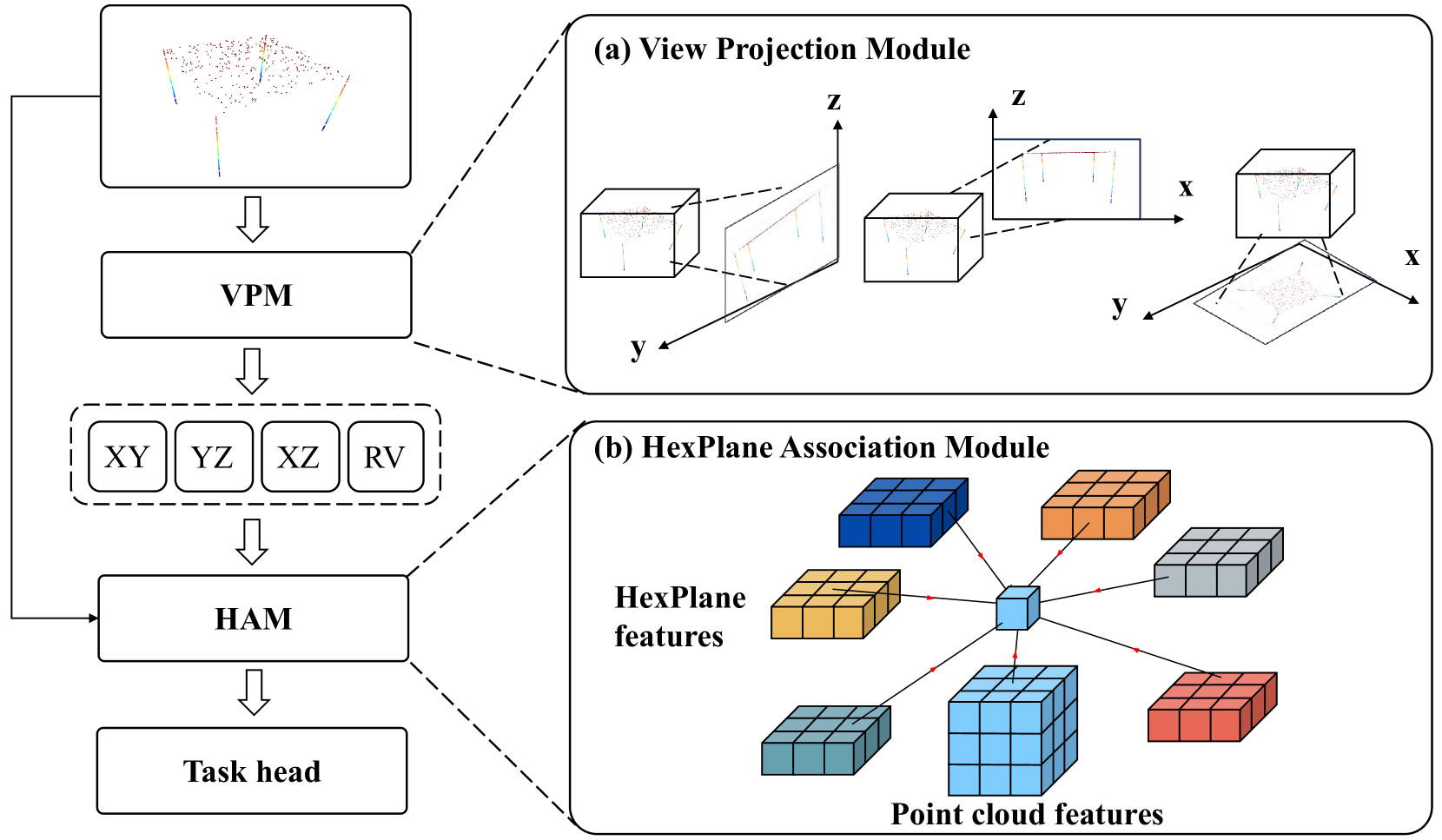
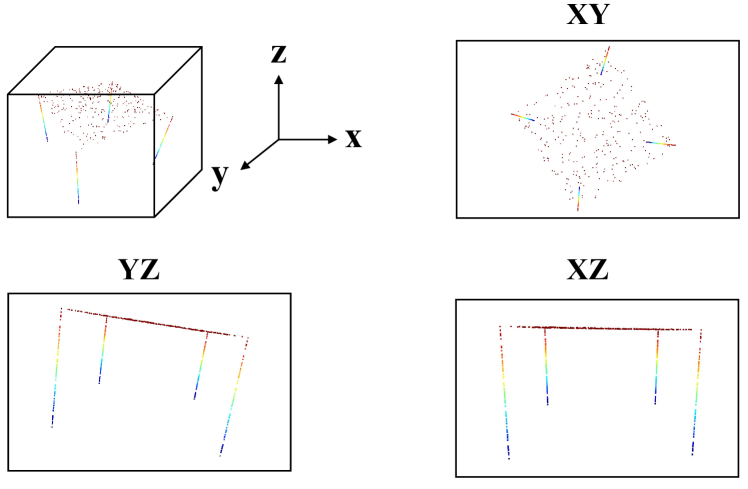
- HexPlane表示将3D点云投影到六个平面,利用2D卷积提取特征,并通过关联模块自适应融合信息。
- HexNet3D在ScanNet分割任务上达到77.0 mIoU,超越Point Transformer V2 1.6 mIoU,且易于集成到现有框架。
📝 摘要(中文)
本文提出了一种用于3D语义场景理解的HexPlane表示方法。具体而言,我们首先设计了视图投影模块(VPM),将3D点云投影到六个平面上,以最大程度地保留原始空间信息。然后,通过2D编码器提取这六个平面的特征,并将其发送到HexPlane关联模块(HAM),以自适应地融合每个点最有用的信息。融合后的点特征被进一步输入到任务头,以产生最终的预测结果。与流行的点和体素表示相比,HexPlane表示是高效的,并且可以利用高度优化的2D操作来处理稀疏和无序的3D点云。它还可以利用现成的2D模型、网络权重和训练方法,在3D空间中实现精确的场景理解。在ScanNet和SemanticKITTI基准测试中,我们的算法HexNet3D取得了与先前算法相比具有竞争力的性能。特别是在ScanNet 3D分割任务中,我们的方法在验证集上获得了77.0 mIoU,超过了Point Transformer V2 1.6 mIoU。我们还在室内3D检测任务中观察到了令人鼓舞的结果。值得注意的是,我们的方法可以无缝地集成到现有的基于体素、基于点和基于范围的方法中,并在没有额外技巧的情况下带来可观的收益。代码将在发布后提供。
🔬 方法详解
问题定义:现有的3D场景理解方法,如基于点的方法和基于体素的方法,在处理大规模、稀疏和无序的3D点云时存在效率瓶颈。基于点的方法计算复杂度高,而基于体素的方法则受到分辨率的限制。此外,这些方法难以充分利用在2D图像处理领域中已经非常成熟的技术和模型。
核心思路:本文的核心思路是将3D点云投影到六个正交的平面上,从而将3D场景理解问题转化为一系列2D图像处理问题。通过这种方式,可以充分利用高效的2D卷积操作和预训练的2D模型,从而提高处理效率和精度。将3D信息编码到多个2D平面上,可以更好地保留原始空间信息,并通过后续的关联模块进行信息融合。
技术框架:HexNet3D的整体框架包括三个主要模块:视图投影模块(VPM)、HexPlane关联模块(HAM)和任务头。首先,VPM将3D点云投影到六个平面上。然后,使用2D编码器提取每个平面的特征。接下来,HAM自适应地融合六个平面的特征,为每个点生成融合后的特征表示。最后,将融合后的特征输入到任务头,以进行语义分割或目标检测等任务。
关键创新:该方法最重要的创新点在于提出了HexPlane表示,将3D点云转换为六个2D平面,从而能够利用高效的2D卷积操作和预训练模型。与直接处理3D点云或体素的方法相比,HexPlane表示在计算效率和精度上都具有优势。此外,HexPlane关联模块(HAM)能够自适应地融合来自不同平面的信息,从而更好地捕捉3D场景的几何和语义信息。
关键设计:视图投影模块(VPM)采用正交投影方式,确保最大程度地保留原始空间信息。2D编码器可以采用各种现成的2D卷积神经网络,如ResNet或EfficientNet。HexPlane关联模块(HAM)使用注意力机制来学习不同平面特征的重要性,并进行加权融合。损失函数根据具体的任务选择,例如,语义分割任务可以使用交叉熵损失函数。
🖼️ 关键图片
📊 实验亮点
HexNet3D在ScanNet 3D语义分割任务中取得了显著的成果,在验证集上达到了77.0 mIoU,超越了Point Transformer V2 1.6 mIoU。此外,该方法在SemanticKITTI数据集上也取得了具有竞争力的性能。实验结果表明,HexPlane表示方法能够有效地处理大规模、稀疏和无序的3D点云,并在精度和效率上都具有优势。
🎯 应用场景
HexPlane表示方法在机器人导航、自动驾驶、虚拟现实、增强现实、三维重建等领域具有广泛的应用前景。它可以用于提高机器人对周围环境的感知能力,实现更精确的场景理解和目标识别。在自动驾驶领域,该方法可以用于构建高精度的三维地图,提高车辆的安全性和可靠性。在VR/AR领域,该方法可以用于创建更逼真的虚拟场景,提升用户体验。
📄 摘要(原文)
In this paper, we introduce the HexPlane representation for 3D semantic scene understanding. Specifically, we first design the View Projection Module (VPM) to project the 3D point cloud into six planes to maximally retain the original spatial information. Features of six planes are extracted by the 2D encoder and sent to the HexPlane Association Module (HAM) to adaptively fuse the most informative information for each point. The fused point features are further fed to the task head to yield the ultimate predictions. Compared to the popular point and voxel representation, the HexPlane representation is efficient and can utilize highly optimized 2D operations to process sparse and unordered 3D point clouds. It can also leverage off-the-shelf 2D models, network weights, and training recipes to achieve accurate scene understanding in 3D space. On ScanNet and SemanticKITTI benchmarks, our algorithm, dubbed HexNet3D, achieves competitive performance with previous algorithms. In particular, on the ScanNet 3D segmentation task, our method obtains 77.0 mIoU on the validation set, surpassing Point Transformer V2 by 1.6 mIoU. We also observe encouraging results in indoor 3D detection tasks. Note that our method can be seamlessly integrated into existing voxel-based, point-based, and range-based approaches and brings considerable gains without bells and whistles. The codes will be available upon publication.