An Egocentric Vision-Language Model based Portable Real-time Smart Assistant
作者: Yifei Huang, Jilan Xu, Baoqi Pei, Yuping He, Guo Chen, Mingfang Zhang, Lijin Yang, Zheng Nie, Jinyao Liu, Guoshun Fan, Dechen Lin, Fang Fang, Kunpeng Li, Chang Yuan, Xinyuan Chen, Yaohui Wang, Yali Wang, Yu Qiao, Limin Wang
分类: cs.CV, cs.HC
发布日期: 2025-03-06
🔗 代码/项目: GITHUB
💡 一句话要点
Vinci:基于第一人称视觉-语言模型的便携式实时智能助手
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 第一人称视觉 视觉-语言模型 实时智能助手 长视频理解 情境感知
📋 核心要点
- 现有AI助手依赖专用硬件或缺乏对第一人称视角视频的有效理解,限制了其在便携设备上的应用。
- Vinci通过EgoVideo-VL模型,结合第一人称视觉基础模型和大型语言模型,实现场景理解和未来规划。
- 实验证明EgoVideo-VL在多个基准测试中表现优异,用户研究也验证了Vinci在实际场景中的适应性和可用性。
📝 摘要(中文)
本文提出Vinci,一个旨在便携设备上提供实时、全面AI辅助的视觉-语言系统。Vinci的核心是EgoVideo-VL,一种新型模型,它集成了第一人称视觉基础模型与大型语言模型(LLM),从而实现场景理解、时间定位、视频摘要和未来规划等高级功能。为了增强实用性,Vinci包含一个用于实时处理长视频流并保留上下文历史的记忆模块,一个用于生成视觉动作演示的生成模块,以及一个桥接第一人称和第三人称视角的检索模块,以提供相关的技能学习操作视频。与通常依赖专用硬件的现有系统不同,Vinci与硬件无关,支持在包括智能手机和可穿戴相机在内的各种设备上部署。实验表明,EgoVideo-VL在多个公共基准测试中表现出色,展示了其视觉-语言推理和上下文理解能力。一系列用户研究评估了Vinci在现实世界中的有效性,突出了其在各种场景中的适应性和可用性。我们希望Vinci能够为便携式、实时第一人称AI系统建立一个新的框架,使用户能够获得情境化和可操作的见解。
🔬 方法详解
问题定义:现有便携式AI助手通常依赖于服务器端处理或特定硬件,无法在资源受限的设备上提供实时、全面的辅助。此外,它们在理解第一人称视角视频,特别是长视频中的上下文信息方面存在不足,难以进行有效的场景理解和未来规划。
核心思路:Vinci的核心思路是将第一人称视觉基础模型与大型语言模型相结合,构建一个名为EgoVideo-VL的模型。通过这种方式,系统能够理解第一人称视角视频中的视觉信息,并利用语言模型进行推理、总结和规划。此外,引入记忆模块来处理长视频流,保留上下文信息。
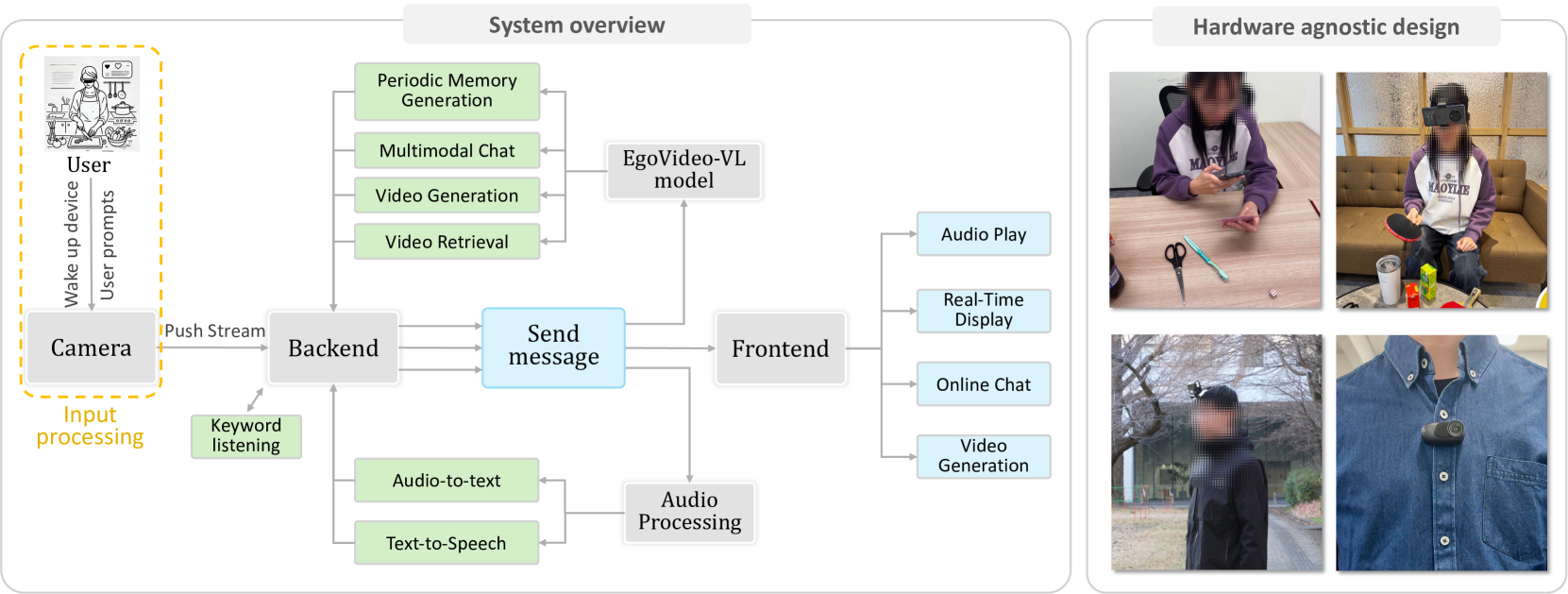
技术框架:Vinci系统包含以下主要模块:1) EgoVideo-VL模型,用于视觉-语言理解;2) 记忆模块,用于处理长视频流并保留上下文历史;3) 生成模块,用于生成视觉动作演示;4) 检索模块,用于检索相关的技能学习操作视频。整体流程是,首先通过EgoVideo-VL模型对第一人称视频进行分析,然后利用记忆模块维护上下文信息,最后根据用户的需求,通过生成模块或检索模块提供相应的辅助信息。
关键创新:Vinci的关键创新在于EgoVideo-VL模型,它将第一人称视觉基础模型与大型语言模型相结合,实现了对第一人称视角视频的深度理解和推理。此外,Vinci的硬件无关性也是一个重要的创新,使其能够在各种设备上部署。
关键设计:EgoVideo-VL模型的具体网络结构和训练方式未知,论文中没有详细描述。记忆模块的具体实现方式也未知。生成模块和检索模块的具体实现细节同样未知。这些是需要进一步研究才能明确的技术细节。
🖼️ 关键图片

📊 实验亮点
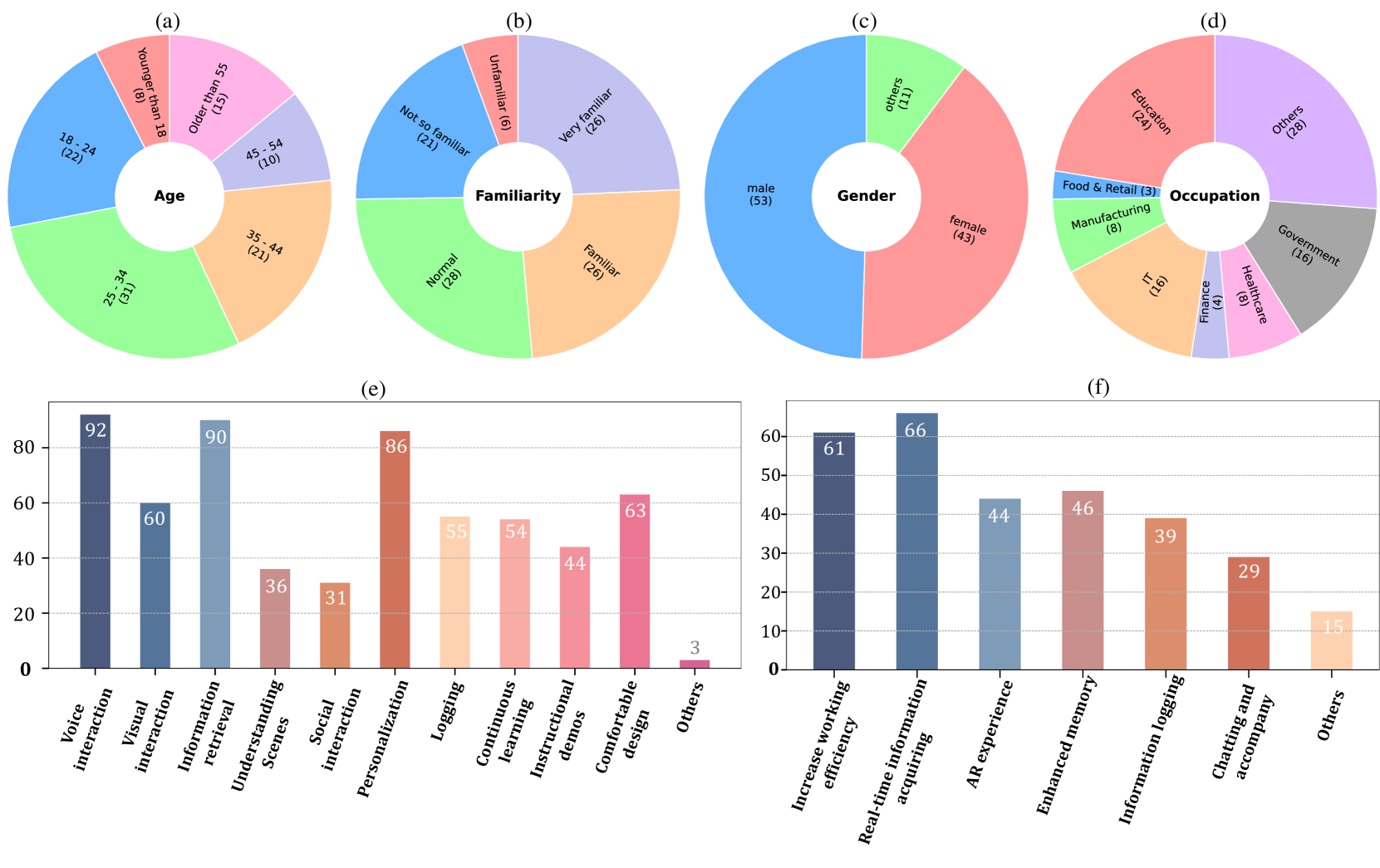
实验结果表明,EgoVideo-VL模型在多个公共基准测试中表现出色,证明了其视觉-语言推理和上下文理解能力。用户研究也验证了Vinci在实际场景中的有效性,突出了其适应性和可用性。具体的性能数据和对比基线在论文中没有明确给出,需要查阅原文。
🎯 应用场景
Vinci具有广泛的应用前景,例如在智能家居、辅助生活、远程协作和教育培训等领域。它可以帮助用户更好地理解周围环境,学习新技能,并进行有效的沟通和协作。未来,Vinci有望成为个人智能助手的核心组成部分,提升人们的生活质量和工作效率。
📄 摘要(原文)
We present Vinci, a vision-language system designed to provide real-time, comprehensive AI assistance on portable devices. At its core, Vinci leverages EgoVideo-VL, a novel model that integrates an egocentric vision foundation model with a large language model (LLM), enabling advanced functionalities such as scene understanding, temporal grounding, video summarization, and future planning. To enhance its utility, Vinci incorporates a memory module for processing long video streams in real time while retaining contextual history, a generation module for producing visual action demonstrations, and a retrieval module that bridges egocentric and third-person perspectives to provide relevant how-to videos for skill acquisition. Unlike existing systems that often depend on specialized hardware, Vinci is hardware-agnostic, supporting deployment across a wide range of devices, including smartphones and wearable cameras. In our experiments, we first demonstrate the superior performance of EgoVideo-VL on multiple public benchmarks, showcasing its vision-language reasoning and contextual understanding capabilities. We then conduct a series of user studies to evaluate the real-world effectiveness of Vinci, highlighting its adaptability and usability in diverse scenarios. We hope Vinci can establish a new framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. Including the frontend, backend, and models, all codes of Vinci are available at https://github.com/OpenGVLab/vinci.