The Role of Visual Modality in Multimodal Mathematical Reasoning: Challenges and Insights
作者: Yufang Liu, Yao Du, Tao Ji, Jianing Wang, Yang Liu, Yuanbin Wu, Aimin Zhou, Mengdi Zhang, Xunliang Cai
分类: cs.CV, cs.AI
发布日期: 2025-03-06 (更新: 2025-06-04)
💡 一句话要点
揭示视觉模态在多模态数学推理中的作用,并提出HC-M3D数据集以增强视觉依赖
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态数学推理 视觉模态 数据集 视觉感知 HC-M3D
📋 核心要点
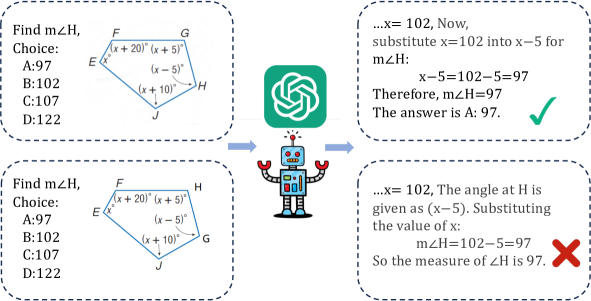
- 现有方法在多模态数学推理中对视觉信息的利用不足,模型性能对图像依赖性低。
- 提出HC-M3D数据集,旨在强制模型依赖图像信息进行推理,并区分细微的视觉差异。
- 实验表明,现有模型难以捕捉HC-M3D数据集中细微的视觉差异,且通用VQA能力的提升不一定能提高数学推理性能。
📝 摘要(中文)
最近的研究越来越关注多模态数学推理,特别强调相关数据集和基准的创建。尽管如此,视觉信息在推理中的作用尚未得到充分探索。我们的研究结果表明,现有的多模态数学模型对视觉信息的利用率极低,并且模型性能在很大程度上不受数据集中图像更改或删除的影响。我们将此归因于文本信息和答案选项的主导地位,这些选项无意中引导模型找到正确的答案。为了改进评估方法,我们引入了HC-M3D数据集,该数据集专门设计为需要依赖图像来解决问题,并使用相似但不同的图像来挑战模型,这些图像会改变正确的答案。在测试领先模型时,它们未能检测到这些细微的视觉差异,这表明当前视觉感知能力存在局限性。此外,我们观察到,通过组合各种类型的图像编码器来提高通用VQA能力的常用方法无助于数学推理性能。这一发现也对增强数学推理期间的视觉依赖性提出了挑战。我们的基准和代码可在https://github.com/Yufang-Liu/visual_modality_role上找到。
🔬 方法详解
问题定义:现有方法在多模态数学推理中,过度依赖文本信息和答案选项,而忽略了视觉信息的作用。即使移除或更改图像,模型性能也不会受到显著影响。这表明现有模型并没有真正理解图像内容,而是通过文本信息进行“作弊”。
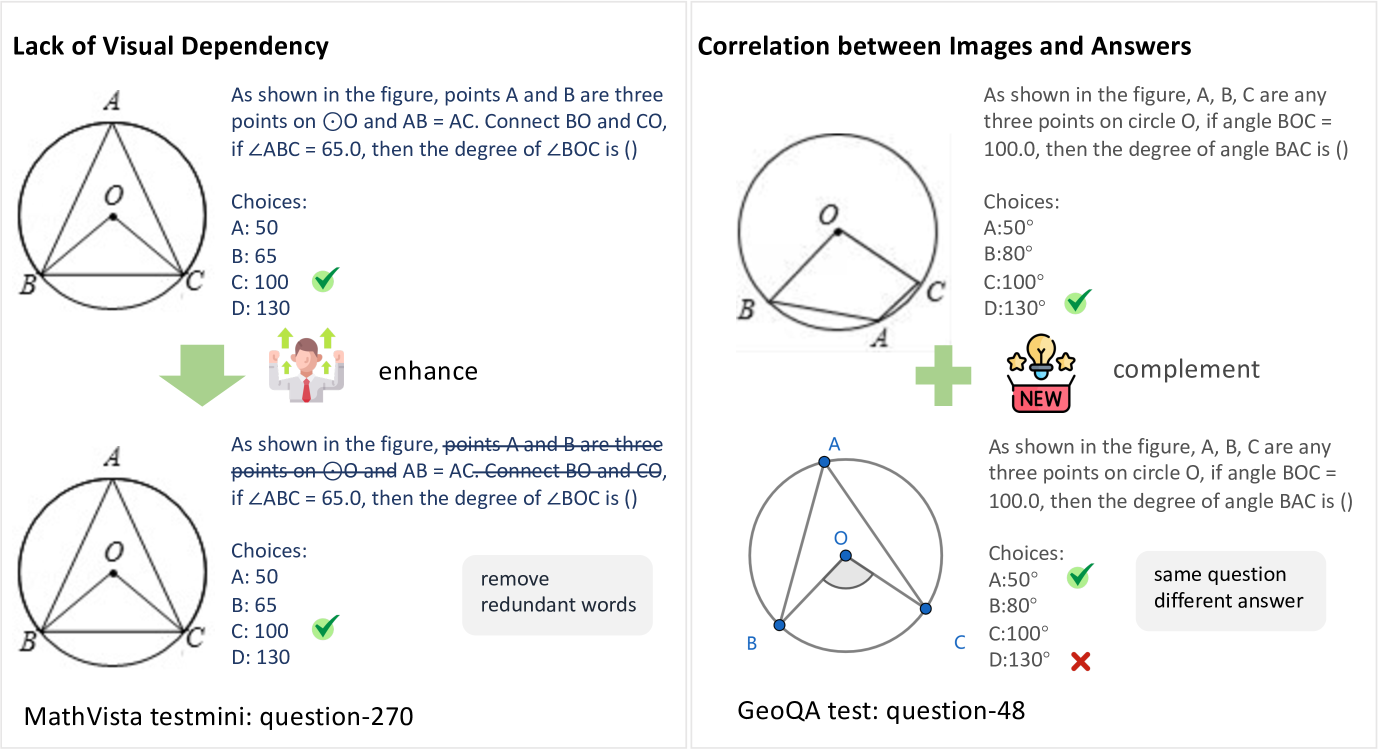
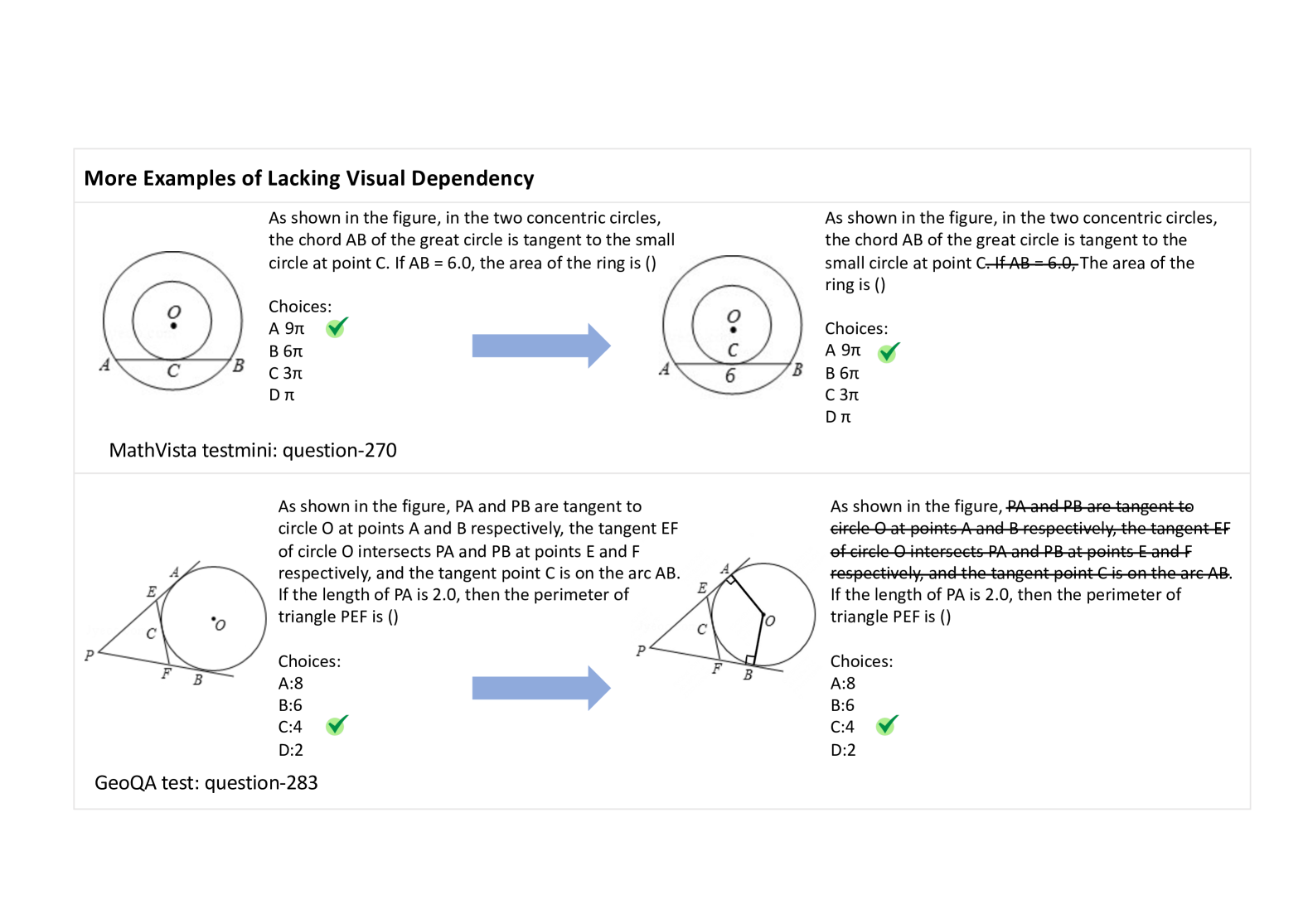
核心思路:为了解决这个问题,论文的核心思路是创建一个更具挑战性的数据集,该数据集需要模型真正理解图像内容才能正确解答问题。通过设计包含细微视觉差异的图像,迫使模型关注图像信息,并区分这些差异对答案的影响。
技术框架:论文主要贡献在于提出了一个新的数据集HC-M3D。该数据集的设计目标是增强模型对视觉信息的依赖性。具体来说,HC-M3D包含需要依赖图像信息才能解决的数学问题,并且这些问题中包含相似但不同的图像,这些图像的细微差异会导致不同的正确答案。论文使用该数据集评估了现有模型的性能。
关键创新:HC-M3D数据集的关键创新在于其设计理念,即通过细微的视觉差异来挑战模型的视觉感知能力。与以往的数据集不同,HC-M3D不仅仅是简单地将图像和文本信息结合在一起,而是要求模型真正理解图像内容,并将其与文本信息结合起来进行推理。
关键设计:HC-M3D数据集的关键设计在于图像的选择和问题的设计。图像的选择需要保证图像之间存在细微的视觉差异,而问题的设计需要保证这些视觉差异对答案产生影响。此外,论文还考虑了数据集的平衡性,以避免模型出现偏差。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有领先模型在HC-M3D数据集上表现不佳,无法有效区分细微的视觉差异,验证了现有模型对视觉信息利用不足的结论。同时,研究发现,提升通用VQA能力并不能直接提高数学推理性能,表明需要针对数学推理任务进行专门的视觉信息利用方法研究。
🎯 应用场景
该研究成果可应用于提升多模态数学推理模型的性能,尤其是在需要视觉信息辅助理解的场景中,例如教育领域的智能辅导系统、科学研究中的数据分析工具等。通过增强模型对视觉信息的理解能力,可以提高其解决复杂问题的能力,并拓展其应用范围。
📄 摘要(原文)
Recent research has increasingly focused on multimodal mathematical reasoning, particularly emphasizing the creation of relevant datasets and benchmarks. Despite this, the role of visual information in reasoning has been underexplored. Our findings show that existing multimodal mathematical models minimally leverage visual information, and model performance remains largely unaffected by changes to or removal of images in the dataset. We attribute this to the dominance of textual information and answer options that inadvertently guide the model to correct answers. To improve evaluation methods, we introduce the HC-M3D dataset, specifically designed to require image reliance for problem-solving and to challenge models with similar, yet distinct, images that change the correct answer. In testing leading models, their failure to detect these subtle visual differences suggests limitations in current visual perception capabilities. Additionally, we observe that the common approach of improving general VQA capabilities by combining various types of image encoders does not contribute to math reasoning performance. This finding also presents a challenge to enhancing visual reliance during math reasoning. Our benchmark and code would be available at \href{https://github.com/Yufang-Liu/visual_modality_role}{https://github.com/Yufang-Liu/visual_modality_role}.