EVE: Towards End-to-End Video Subtitle Extraction with Vision-Language Models
作者: Haiyang Yu, Mengyang Zhao, Jinghui Lu, Ke Niu, Yanjie Wang, Weijie Yin, Weitao Jia, Teng Fu, Yang Liu, Jun Liu, Hong Chen
分类: cs.CV
发布日期: 2025-03-06 (更新: 2025-12-04)
💡 一句话要点
提出EVE框架,利用视觉-语言模型实现端到端视频字幕提取,并构建大规模数据集ViSa。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频字幕提取 视觉-语言模型 端到端学习 时空建模 大规模数据集
📋 核心要点
- 现有视频字幕提取方法依赖多阶段框架,存在误差累积和时间依赖性利用不足的问题。
- EVE框架利用LVLM,通过时空字幕显著性模块提取字幕信息,实现端到端字幕和时间戳预测。
- 构建了大规模视频字幕数据集ViSa,包含250万+视频,为研究提供基准。
📝 摘要(中文)
视频字幕在短视频和电影中起着至关重要的作用,它们不仅有助于模型更好地理解视频内容,还支持视频翻译和内容检索等应用。现有的视频字幕提取方法通常依赖于多阶段框架,误差会在各个阶段累积,并且由于逐帧处理而无法充分利用时间依赖性。此外,尽管一些大型视觉-语言模型(LVLM)具有强大的OCR能力,但预测字幕文本的准确时间戳仍然具有挑战性。为此,我们提出了一个基于LVLM的端到端视频字幕提取框架EVE,它可以同时输出字幕及其时间戳。具体来说,我们引入了一个双分支时空字幕显著性(S³)模块,作为LVLM的适配器,能够表示字幕相关内容,并仅使用少量token来考虑帧间相关性。在该模块中,空间语义上下文聚合分支聚合高层全局语义,以提供空间视觉上下文信息,而时间字幕token查询分支在考虑跨帧时间相关性的同时,显式地查询字幕相关token。S³模块保留的少量token被馈送到语言模型,然后语言模型直接输出字幕文本及其时间戳。此外,我们构建了第一个专门用于视频字幕提取的大规模数据集ViSa,其中包含超过250万个带有时间戳和双语注释的视频,从而为社区提供了一个组织良好的训练和评估基准。
🔬 方法详解
问题定义:现有视频字幕提取方法通常采用多阶段流程,例如先检测文本区域,再进行OCR识别,最后进行时间戳对齐。这种pipeline式的结构会导致误差在各个阶段累积,影响最终的提取精度。此外,现有方法通常逐帧处理视频,忽略了视频帧之间的时间相关性,无法有效利用上下文信息来提高字幕提取的准确性。即使是强大的LVLM,也难以直接预测准确的字幕时间戳。
核心思路:EVE框架的核心思路是利用LVLM强大的视觉和语言理解能力,构建一个端到端的字幕提取模型。通过引入时空字幕显著性(S³)模块,将视频帧中的字幕相关信息压缩成少量token,并输入到LVLM中,从而实现字幕文本和时间戳的联合预测。这样可以避免多阶段流程中的误差累积,并充分利用视频帧之间的时间相关性。
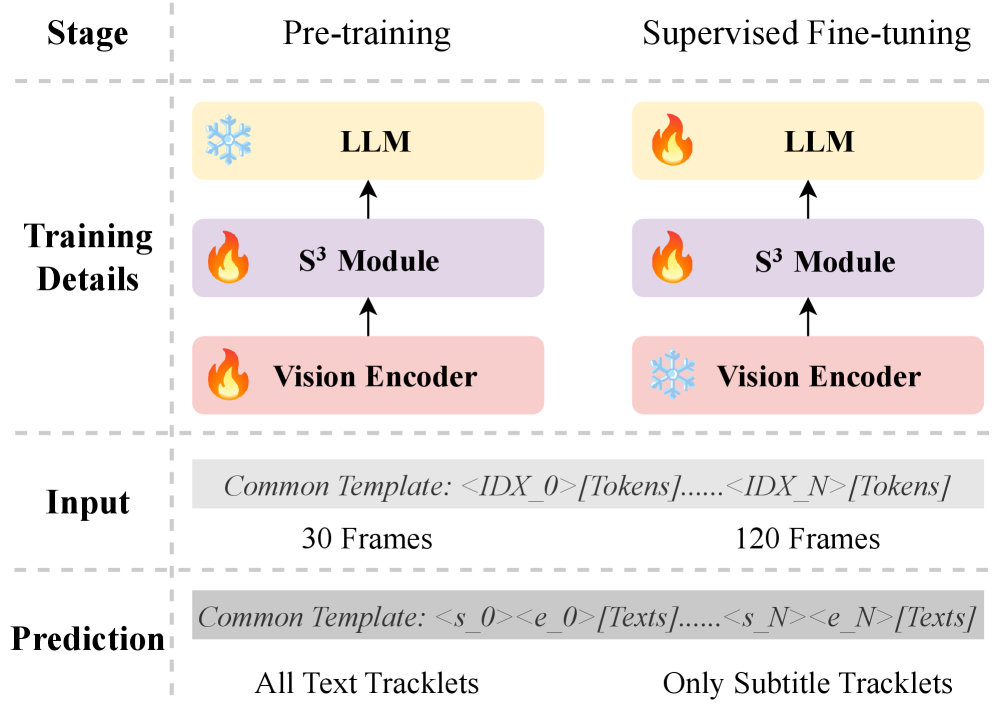
技术框架:EVE框架主要包含两个核心模块:视觉编码器(通常是预训练的LVLM的视觉部分)和时空字幕显著性(S³)模块。视觉编码器负责提取视频帧的视觉特征。S³模块包含两个分支:空间语义上下文聚合分支和时间字幕token查询分支。空间语义上下文聚合分支负责聚合高层全局语义信息,提供空间视觉上下文。时间字幕token查询分支则显式地查询字幕相关的token,并考虑跨帧的时间相关性。最后,S³模块输出的少量token被输入到LVLM的语言模型部分,直接预测字幕文本和时间戳。
关键创新:EVE框架的关键创新在于提出了时空字幕显著性(S³)模块。该模块能够有效地提取视频帧中的字幕相关信息,并将其压缩成少量token,从而降低了计算复杂度,并使得LVLM能够更好地关注字幕内容。此外,S³模块同时考虑了空间语义上下文和时间相关性,从而提高了字幕提取的准确性。与现有方法相比,EVE框架实现了端到端的字幕提取,避免了多阶段流程中的误差累积。
关键设计:S³模块的设计是EVE框架的关键。空间语义上下文聚合分支可能采用注意力机制或卷积神经网络来聚合全局语义信息。时间字幕token查询分支可能采用可学习的查询向量来显式地查询字幕相关的token,并使用循环神经网络或Transformer来建模时间相关性。损失函数可能包括字幕文本预测损失和时间戳预测损失。具体参数设置和网络结构细节未知,需要参考论文具体实现。
🖼️ 关键图片


📊 实验亮点
论文构建了大规模视频字幕数据集ViSa,包含超过250万个视频,为视频字幕提取研究提供了宝贵的数据资源。实验结果未知,但端到端框架和S³模块的设计预计能显著提升字幕提取的准确性和效率,尤其是在时间戳预测方面。
🎯 应用场景
EVE框架在视频字幕提取领域具有广泛的应用前景,例如可以用于自动生成视频字幕,提高视频的可访问性;可以用于视频翻译,帮助用户理解不同语言的视频内容;还可以用于视频内容检索,方便用户查找包含特定字幕的视频片段。该研究有助于推动视频理解和多模态学习的发展。
📄 摘要(原文)
Video subtitles play a crucial role in short videos and movies, as they not only help models better understand video content but also support applications such as video translation and content retrieval. Existing video subtitle extraction methods typically rely on multi-stage frameworks, where errors accumulate across stages and temporal dependencies are underutilized due to frame-wise processing. Moreover, although some Large Vision-Language Models (LVLMs) possess strong OCR capabilities, predicting accurate timestamps for subtitle texts remains challenging. To this end, we propose an End-to-end Video subtitle Extraction framework based on LVLMs, named EVE, which can output subtitles and their timestamps simultaneously. Specifically, we introduce a dual-branch Spatiotemporal Subtitle-Salient (S\textsuperscript{3}) Module that serves as an adapter for LVLMs, capable of representing subtitle-related content and considering inter-frame correlations using only a small number of tokens. Within this module, the Spatial Semantic Context Aggregate branch aggregates high-level global semantics to provide spatial visual contextual information, while the Temporal Subtitle Token Query branch explicitly queries subtitle-relevant tokens while considering temporal correlation across frames. The small number of tokens retained by the S\textsuperscript{3} module are fed to the language model, which then directly outputs the subtitle text along with its timestamps. Furthermore, we construct the first large-scale dataset dedicated to video subtitle extraction, ViSa, containing over 2.5M videos with timestamped and bilingual annotation, thereby providing the community with a well-organized training and evaluation benchmark.