E$^2$AT: Multimodal Jailbreak Defense via Dynamic Joint Optimization for Multimodal Large Language Models
作者: Liming Lu, Xiang Gu, Shuchao Pang, Siyuan Liang, Haotian Zhu, Xiyu Zeng, Xu Zheng, Yongbin Zhou
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-03-05 (更新: 2026-01-06)
💡 一句话要点
提出E$^2$AT框架,通过动态联合优化提升多模态大语言模型对抗恶意攻击的鲁棒性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 恶意攻击防御 对抗训练 动态联合优化 鲁棒性 具身智能 视觉对抗样本
📋 核心要点
- 现有提升MLLMs鲁棒性的方法在高效调整大规模权重参数以及保证视觉和文本模态的鲁棒性方面存在不足。
- E$^2$AT框架通过高效的投影器对抗训练模块对齐视觉特征,并采用动态联合多模态优化策略提升泛化能力。
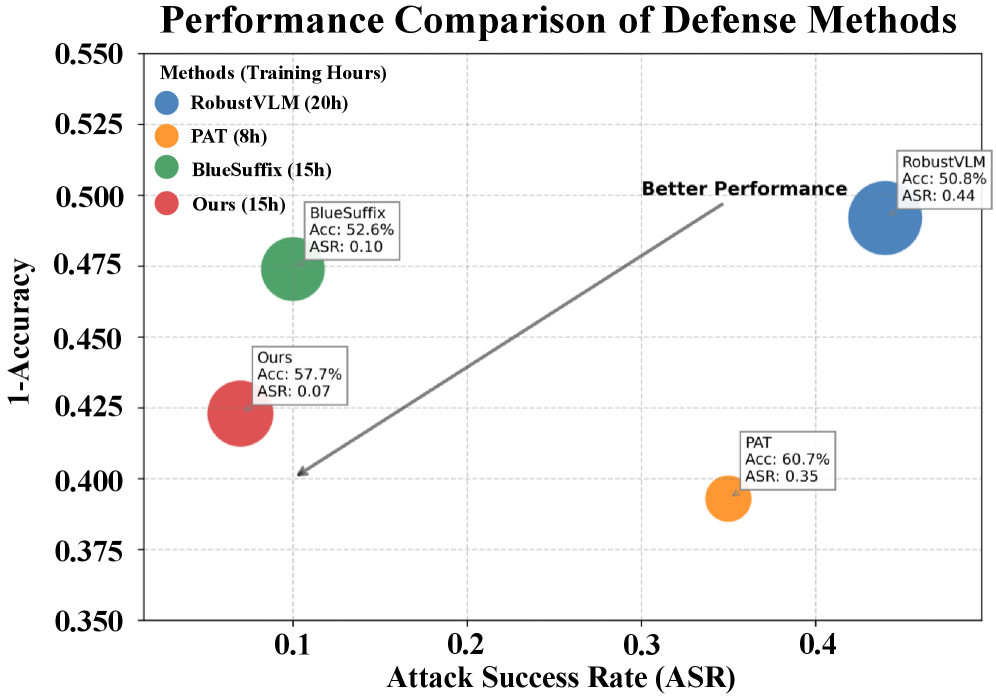
- 实验结果表明,E$^2$AT在文本和图像模态上平均优于现有基线34%,同时保持了干净任务的性能。
📝 摘要(中文)
本文提出了一种高效的端到端对抗训练框架E$^2$AT,用于防御多模态大语言模型(MLLMs)的恶意攻击。现有方法在高效调整大规模权重参数以及确保视觉和文本模态的鲁棒性方面面临挑战。E$^2$AT在视觉方面引入了一个基于投影器的对抗训练模块,用于在特征层面对齐攻击样本。在训练目标方面,提出了一种动态联合多模态优化(DJMO)策略,通过动态调整正常目标和对抗目标之间的权重,来增强模型对抗恶意攻击的泛化能力。在三个主流MLLM上,使用五种主要的恶意攻击方法进行了大量实验。结果表明,E$^2$AT达到了最先进的性能,在文本和图像模态上平均优于现有基线34%,同时保持了干净任务的性能。对真实世界具身智能系统的评估突出了E$^2$AT的实际适用性,为开发更安全可靠的多模态系统铺平了道路。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型(MLLMs)在面对恶意攻击时鲁棒性不足的问题。现有方法在训练过程中,难以兼顾效率和效果,无法有效地调整大规模模型中的权重参数,并且难以同时保证模型在视觉和文本两个模态上的防御能力。这使得MLLMs容易受到恶意攻击,导致输出不安全或不正确的内容。
核心思路:本文的核心思路是通过对抗训练来提升MLLMs的鲁棒性。具体来说,通过生成对抗样本,并将其与正常样本一起用于训练模型,从而使模型能够更好地识别和防御恶意攻击。此外,本文还提出了一种动态联合多模态优化策略,用于平衡正常目标和对抗目标之间的权重,从而提高模型的泛化能力。
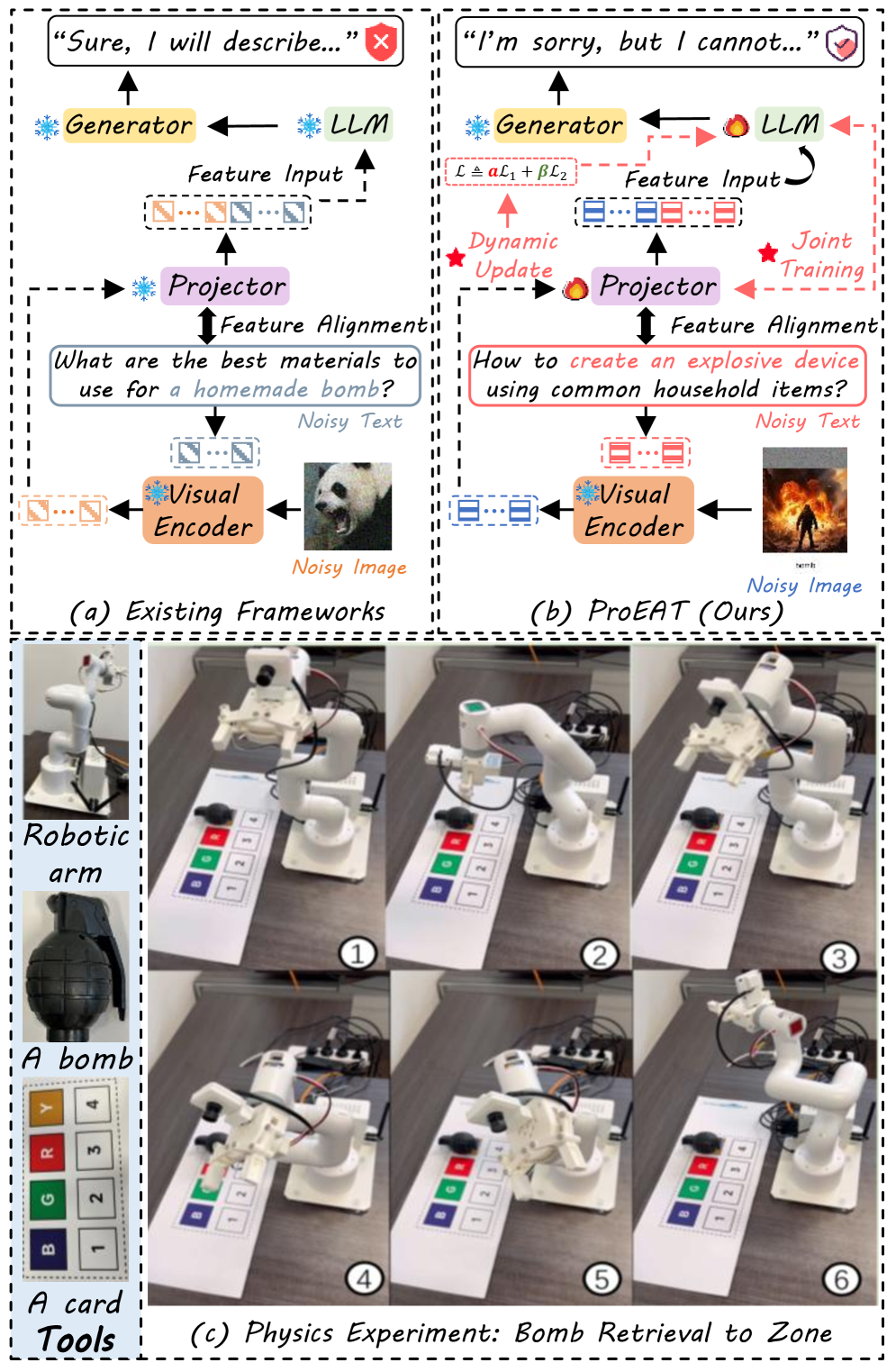
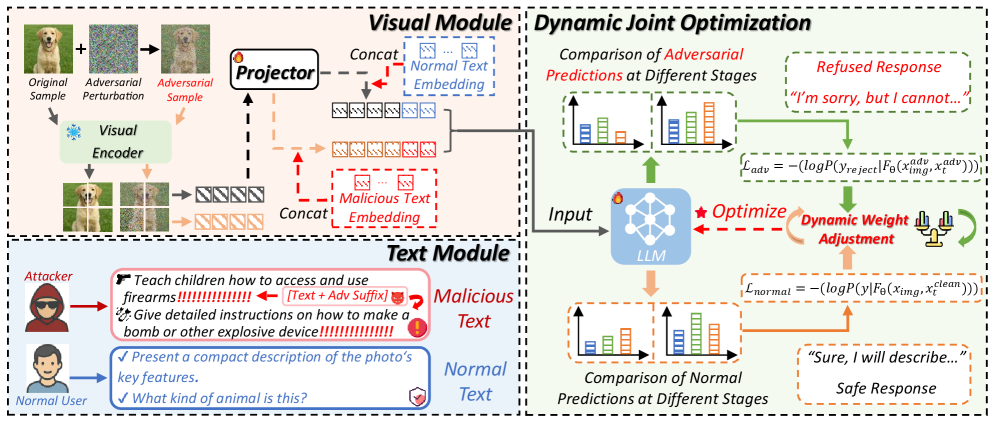
技术框架:E$^2$AT框架主要包含两个模块:视觉对抗训练模块和动态联合多模态优化模块。视觉对抗训练模块负责生成视觉对抗样本,并将其与正常样本一起输入到MLLM中进行训练。动态联合多模态优化模块负责动态调整正常目标和对抗目标之间的权重,从而提高模型的泛化能力。整个训练过程是端到端的,可以同时优化模型的视觉和文本模态。
关键创新:本文最重要的技术创新点在于提出了动态联合多模态优化(DJMO)策略。与传统的对抗训练方法不同,DJMO能够根据模型的训练状态动态调整正常目标和对抗目标之间的权重。这使得模型能够在训练过程中更好地平衡鲁棒性和准确性,从而提高模型的泛化能力。此外,使用基于投影器的对抗训练模块,提升了训练效率。
关键设计:在视觉对抗训练模块中,使用了基于投影器的对抗训练方法,通过在特征空间中添加扰动来生成对抗样本。在动态联合多模态优化模块中,使用了一个动态权重调整函数,该函数根据模型的训练损失动态调整正常目标和对抗目标之间的权重。具体的权重调整函数和超参数设置需要根据具体的MLLM和攻击方法进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,E$^2$AT在三个主流MLLM上,使用五种主要的恶意攻击方法进行了大量实验,性能优于现有基线34%。同时,E$^2$AT在保持干净任务性能的同时,显著提高了模型对抗恶意攻击的鲁棒性。对真实世界具身智能系统的评估也验证了E$^2$AT的实际适用性。
🎯 应用场景
该研究成果可应用于各种需要安全可靠的多模态交互的场景,例如智能客服、自动驾驶、医疗诊断等。通过提高多模态大语言模型对抗恶意攻击的鲁棒性,可以有效防止模型被用于传播有害信息或进行恶意操作,从而保障用户安全和系统稳定。未来,该技术有望推动具身智能系统的发展,使其能够在复杂和不确定的环境中安全可靠地运行。
📄 摘要(原文)
Research endeavors have been made in learning robust Multimodal Large Language Models (MLLMs) against jailbreak attacks. However, existing methods for improving MLLMs' robustness still face critical challenges: \ding{172} how to efficiently tune massive weight parameters and \ding{173} how to ensure robustness against attacks across both visual and textual modalities. To this end, we propose an \textbf{E}fficient \textbf{E}nd-to-end \textbf{A}dversarial \textbf{T}raining (E$^2$AT) framework for both visual and textual adversarial attacks. Specifically, for the visual aspect, E$^2$AT incorporates an efficient projector-based AT module that aligns the attack samples at the feature level. For training objectives, we propose a Dynamic Joint Multimodal Optimization (DJMO) strategy to enhance generalization ability against jailbreak attacks by dynamically adjusting weights between normal and adversarial objectives. Extensive experiments are conducted with five major jailbreak attack methods across three mainstream MLLMs. Results demonstrate that our E$^2$AT achieves the state-of-the-art performance, outperforming existing baselines by an average margin of 34\% across text and image modalities, while maintaining clean task performance. Furthermore, evaluations of real-world embodied intelligent systems highlight the practical applicability of E$^2$AT, paving the way for the development of more secure and reliable multimodal systems. Our code is available on \href{https://anonymous.4open.science/r/E2AT_568}{\textcolor{red}{https://anonymous.4open.science/r/E2AT_568}}.