Active 6D Pose Estimation for Textureless Objects using Multi-View RGB Frames
作者: Jun Yang, Wenjie Xue, Sahar Ghavidel, Steven L. Waslander
分类: cs.CV, cs.RO
发布日期: 2025-03-05 (更新: 2025-12-15)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于多视角RGB图像的主动6D位姿估计方法,解决无纹理物体位姿估计难题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 6D位姿估计 无纹理物体 多视角视觉 主动感知 机器人抓取
📋 核心要点
- 单视角6D位姿估计器难以处理具有外观歧义、旋转对称性和严重遮挡的无纹理物体,限制了其应用范围。
- 该方法将6D位姿估计分解为3D平移估计和3D方向估计两个步骤,并结合主动感知策略选择最佳视角。
- 实验结果表明,该方法在多个数据集上优于现有技术,并且通过最佳视角策略,可以用更少的视角实现更高的位姿精度。
📝 摘要(中文)
本文提出了一种全面的主动感知框架,仅使用RGB图像估计无纹理物体的6D位姿。该方法的核心思想是将6D位姿估计解耦为两步顺序过程,从而显著提高精度和效率。首先,估计每个物体的3D平移,解决RGB图像固有的尺度和深度模糊性。然后,利用这些估计简化后续的3D方向确定任务,通过规范尺度模板匹配实现。在此基础上,引入主动感知策略,预测捕获RGB图像的最佳相机视角,有效降低物体位姿不确定性,提高位姿精度。在公共ROBI和TOD数据集以及我们重建的透明物体数据集T-ROBI上进行了评估。在相同相机视角下,我们的多视角位姿估计显著优于现有方法。此外,通过利用我们的最佳视角策略,我们的方法在所有评估的数据集上,以比基于启发式策略更少的视角实现了高位姿精度。
🔬 方法详解
问题定义:论文旨在解决仅使用RGB图像进行无纹理物体6D位姿估计的问题。现有方法,特别是基于单视角的方法,在处理外观模糊、旋转对称和严重遮挡等情况时表现不佳,导致位姿估计精度较低,鲁棒性不足。
核心思路:论文的核心思路是将6D位姿估计解耦为两个阶段:首先估计3D平移,然后估计3D旋转。这种解耦简化了问题,因为3D平移估计可以消除尺度和深度模糊性,从而为后续的3D旋转估计提供更准确的先验信息。此外,引入主动感知策略,通过预测下一个最佳视角来减少位姿不确定性。
技术框架:整体框架包含以下几个主要步骤:1) 多视角RGB图像采集;2) 3D平移估计,利用多视角信息消除尺度和深度模糊;3) 3D旋转估计,使用规范尺度模板匹配方法,利用前一步的平移估计结果;4) 主动感知,基于当前位姿估计的不确定性,预测下一个最佳视角。通过迭代执行这些步骤,逐步提高位姿估计的精度。
关键创新:该方法最重要的创新点在于将6D位姿估计解耦为平移和旋转两个阶段,并结合主动感知策略。这种解耦简化了问题,提高了估计精度。主动感知策略能够智能地选择视角,减少了所需的视角数量,提高了效率。与现有方法相比,该方法更适用于无纹理物体,并且能够更好地处理遮挡和模糊等情况。
关键设计:在3D平移估计阶段,可能使用了多视角几何约束,例如三角化或光束法平差。在3D旋转估计阶段,规范尺度模板匹配可能涉及对物体进行规范化,并使用模板匹配算法来找到最佳旋转。主动感知策略可能基于信息增益或位姿不确定性等指标来选择下一个最佳视角。具体的损失函数和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
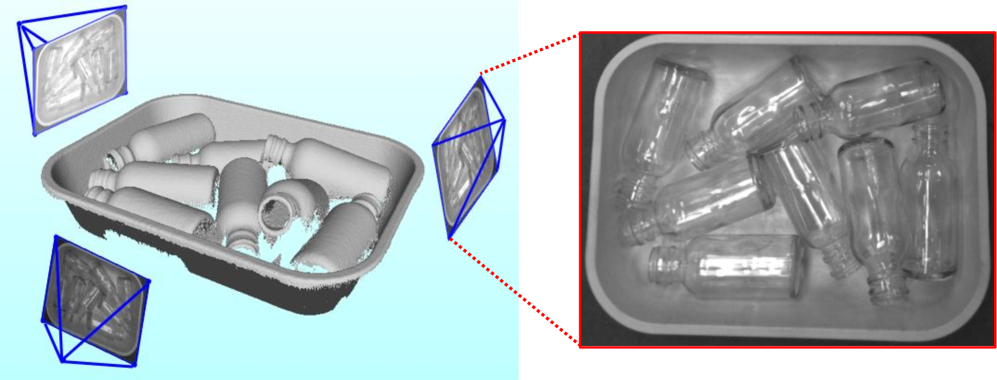


📊 实验亮点
该方法在ROBI、TOD和T-ROBI数据集上进行了评估,实验结果表明,在相同的相机视角下,该方法的多视角位姿估计显著优于现有方法。此外,通过利用最佳视角策略,该方法可以用比基于启发式策略更少的视角实现更高的位姿精度。具体的性能提升数据需要在论文中查找(未知)。
🎯 应用场景
该研究成果可应用于机器人抓取、工业自动化、增强现实等领域。在机器人抓取中,准确的6D位姿估计能够帮助机器人更好地识别和抓取物体。在工业自动化中,可以用于产品检测和装配。在增强现实中,可以实现虚拟物体与真实场景的精确对齐。未来,该技术有望进一步扩展到更复杂的场景和物体,例如透明物体和变形物体。
📄 摘要(原文)
Estimating the 6D pose of textureless objects from RGB images is an important problem in robotics. Due to appearance ambiguities, rotational symmetries, and severe occlusions, single-view based 6D pose estimators are still unable to handle a wide range of objects, motivating research towards multi-view pose estimation and next-best-view prediction that addresses these limitations. In this work, we propose a comprehensive active perception framework for estimating the 6D poses of textureless objects using only RGB images. Our approach is built upon a key idea: decoupling the 6D pose estimation into a two-step sequential process can greatly improve both accuracy and efficiency. First, we estimate the 3D translation of each object, resolving scale and depth ambiguities inherent to RGB images. These estimates are then used to simplify the subsequent task of determining the 3D orientation, which we achieve through canonical scale template matching. Building on this formulation, we then introduce an active perception strategy that predicts the next best camera viewpoint to capture an RGB image, effectively reducing object pose uncertainty and enhancing pose accuracy. We evaluate our method on the public ROBI and TOD datasets, as well as on our reconstructed transparent object dataset, T-ROBI. Under the same camera viewpoints, our multi-view pose estimation significantly outperforms state-of-the-art approaches. Furthermore, by leveraging our next-best-view strategy, our approach achieves high pose accuracy with fewer viewpoints than heuristic-based policies across all evaluated datasets. The accompanying video and T-ROBI dataset will be released on our project page: https://trailab.github.io/ActiveODPE.