LION-FS: Fast & Slow Video-Language Thinker as Online Video Assistant
作者: Wei Li, Bing Hu, Rui Shao, Leyang Shen, Liqiang Nie
分类: cs.CV
发布日期: 2025-03-05 (更新: 2025-03-06)
备注: Accept to CVPR 2025, Project page: https://github.com/JiuTian-VL/LION-FS
💡 一句话要点
提出LION-FS,一种快速&慢速视频语言模型,用于在线视频助手,提升效率与效果。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线视频助手 第一人称视角视频 快速&慢速处理 多模态融合 关键帧提取 路由机制 视频语言模型
📋 核心要点
- 现有在线视频助手为了实时性牺牲了效果,通常处理低帧率视频并使用粗粒度的视觉特征。
- LION-FS采用快速路径和慢速路径相结合的策略,快速路径决定是否需要响应,慢速路径优化关键帧以生成更精确的响应。
- 实验结果表明,LION-FS在在线视频任务上实现了最先进的效果和效率,显著提升了性能。
📝 摘要(中文)
本文提出了一种“快速&慢速视频语言思考器”(LION-FS),作为在线视频助手,旨在实现实时、主动、时间精确和上下文准确的响应,从而克服现有在线视频助手为了实时效率而牺牲效果的问题,这些助手通常处理低帧率视频并使用粗粒度的视觉特征。LION-FS采用两阶段优化策略:1)快速路径:基于路由的响应确定,逐帧评估是否需要立即响应;采用令牌聚合路由动态融合时空特征,并利用令牌丢弃路由消除冗余特征,从而提高响应确定精度并有效处理更高帧率的输入。2)慢速路径:多粒度关键帧增强,优化响应生成过程中的关键帧;通过多粒度池化提取细粒度的空间特征和人-环境交互特征,并将这些特征集成到精心设计的多模态思考模板中,以指导更精确的响应生成。在在线视频任务上的综合评估表明,LION-FS实现了最先进的效果和效率。
🔬 方法详解
问题定义:现有在线视频助手在处理第一人称视角视频对话时,为了保证实时性,通常采用低帧率视频和粗粒度视觉特征,导致助手效果不佳,无法提供时间精确和上下文准确的响应。因此,如何在保证实时性的前提下,提升在线视频助手的效果是一个关键问题。
核心思路:LION-FS的核心思路是采用“快速&慢速”双路径处理机制。快速路径负责快速判断是否需要响应,慢速路径则负责对关键帧进行精细化处理,生成更准确的响应。这种设计旨在平衡实时性和准确性,从而克服现有方法的局限性。
技术框架:LION-FS包含两个主要模块:快速路径和慢速路径。快速路径采用基于路由的响应确定机制,逐帧评估是否需要立即响应。慢速路径则采用多粒度关键帧增强策略,提取细粒度的空间特征和人-环境交互特征,并将其集成到多模态思考模板中,以指导更精确的响应生成。整体流程是先通过快速路径筛选关键帧,然后通过慢速路径对关键帧进行精细化处理,最后生成响应。
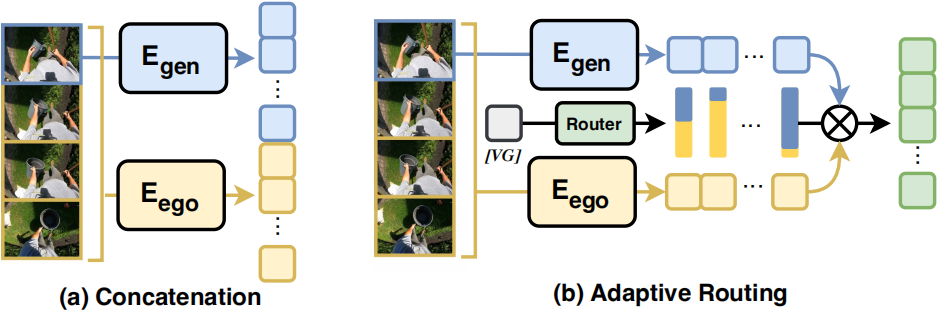
关键创新:LION-FS的关键创新在于其“快速&慢速”双路径处理机制,以及在快速路径中采用的令牌聚合路由和令牌丢弃路由。令牌聚合路由可以动态融合时空特征,而无需增加令牌数量,令牌丢弃路由则可以消除冗余特征,从而提高响应确定精度和效率。此外,多粒度关键帧增强策略和多模态思考模板也是重要的创新点。
关键设计:在快速路径中,令牌聚合路由和令牌丢弃路由的具体实现方式未知,论文中可能包含相关细节。在慢速路径中,多粒度池化的具体粒度设置,以及多模态思考模板的具体结构和参数设置未知。损失函数的设计也未知,可能包含针对在线视频助手任务的特殊设计。
🖼️ 关键图片


📊 实验亮点
论文在在线视频任务上进行了综合评估,实验结果表明,LION-FS在效果和效率方面均达到了最先进水平。具体的性能数据和对比基线未知,但摘要中明确指出LION-FS实现了state-of-the-art的性能,表明其具有显著的优势。
🎯 应用场景
LION-FS具有广泛的应用前景,可以应用于智能家居、远程协助、可穿戴设备等领域。例如,在智能家居中,LION-FS可以作为用户的智能助手,根据用户的视觉输入提供实时的帮助和指导。在远程协助中,LION-FS可以帮助专家远程指导用户完成复杂任务。未来,LION-FS有望成为人们日常生活中不可或缺的一部分。
📄 摘要(原文)
First-person video assistants are highly anticipated to enhance our daily lives through online video dialogue. However, existing online video assistants often sacrifice assistant efficacy for real-time efficiency by processing low-frame-rate videos with coarse-grained visual features.To overcome the trade-off between efficacy and efficiency, we propose "Fast & Slow Video-Language Thinker" as an onLIne videO assistaNt, LION-FS, achieving real-time, proactive, temporally accurate, and contextually precise responses. LION-FS adopts a two-stage optimization strategy: 1)Fast Path: Routing-Based Response Determination evaluates frame-by-frame whether an immediate response is necessary. To enhance response determination accuracy and handle higher frame-rate inputs efficiently, we employ Token Aggregation Routing to dynamically fuse spatiotemporal features without increasing token numbers, while utilizing Token Dropping Routing to eliminate redundant features. 2)Slow Path: Multi-granularity Keyframe Augmentation optimizes keyframes during response generation. To provide comprehensive and detailed responses beyond atomic actions constrained by training data, fine-grained spatial features and human-environment interaction features are extracted through multi-granular pooling. These features are further integrated into a meticulously designed multimodal Thinking Template to guide more precise response generation. Comprehensive evaluations on online video tasks demonstrate that LION-FS achieves state-of-the-art efficacy and efficiency.