DoraCycle: Domain-Oriented Adaptation of Unified Generative Model in Multimodal Cycles
作者: Rui Zhao, Weijia Mao, Mike Zheng Shou
分类: cs.CV
发布日期: 2025-03-05
备注: CVPR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
DoraCycle:提出一种多模态循环的领域自适应统一生成模型,利用非配对数据实现模型进化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 领域自适应 生成模型 多模态学习 循环一致性 非配对数据 文本图像生成 风格迁移
📋 核心要点
- 现有领域自适应生成模型依赖大量配对数据,限制了其在数据稀缺领域的应用。
- DoraCycle利用多模态循环一致性,通过非配对数据实现生成模型的领域自适应,无需依赖大量标注。
- 实验表明,DoraCycle在风格化等任务上表现出色,少量配对数据即可完成特定身份等任务。
📝 摘要(中文)
将生成模型适配到特定领域是满足专业化需求的有效方法。然而,适配到某些复杂领域仍然具有挑战性,尤其是在这些领域需要大量配对数据来捕获目标分布时。由于来自单一模态(如视觉或语言)的非配对数据更容易获得,我们利用统一生成模型学习到的视觉和语言之间的双向映射,从而能够利用非配对数据进行领域自适应训练。具体来说,我们提出了DoraCycle,它集成了两个多模态循环:文本到图像到文本和图像到文本到图像。该模型通过在循环端点计算的交叉熵损失进行优化,其中两个端点共享相同的模态。这有助于模型在不依赖带注释的文本-图像对的情况下进行自我进化。实验结果表明,对于独立于配对知识的任务(如风格化),DoraCycle可以使用非配对数据有效地适配统一模型。对于涉及新配对知识的任务(如特定身份),少量配对图像-文本示例与更大规模的非配对数据的组合足以实现有效的面向领域的自适应。
🔬 方法详解
问题定义:现有领域自适应生成模型通常需要大量的配对数据,这在许多实际应用中是难以满足的。例如,要将一个通用的图像生成模型适配到特定风格的图像生成,或者生成特定人物的图像,都需要大量的该风格或人物的图像和对应的文本描述。获取这些配对数据成本高昂,限制了领域自适应生成模型的发展。
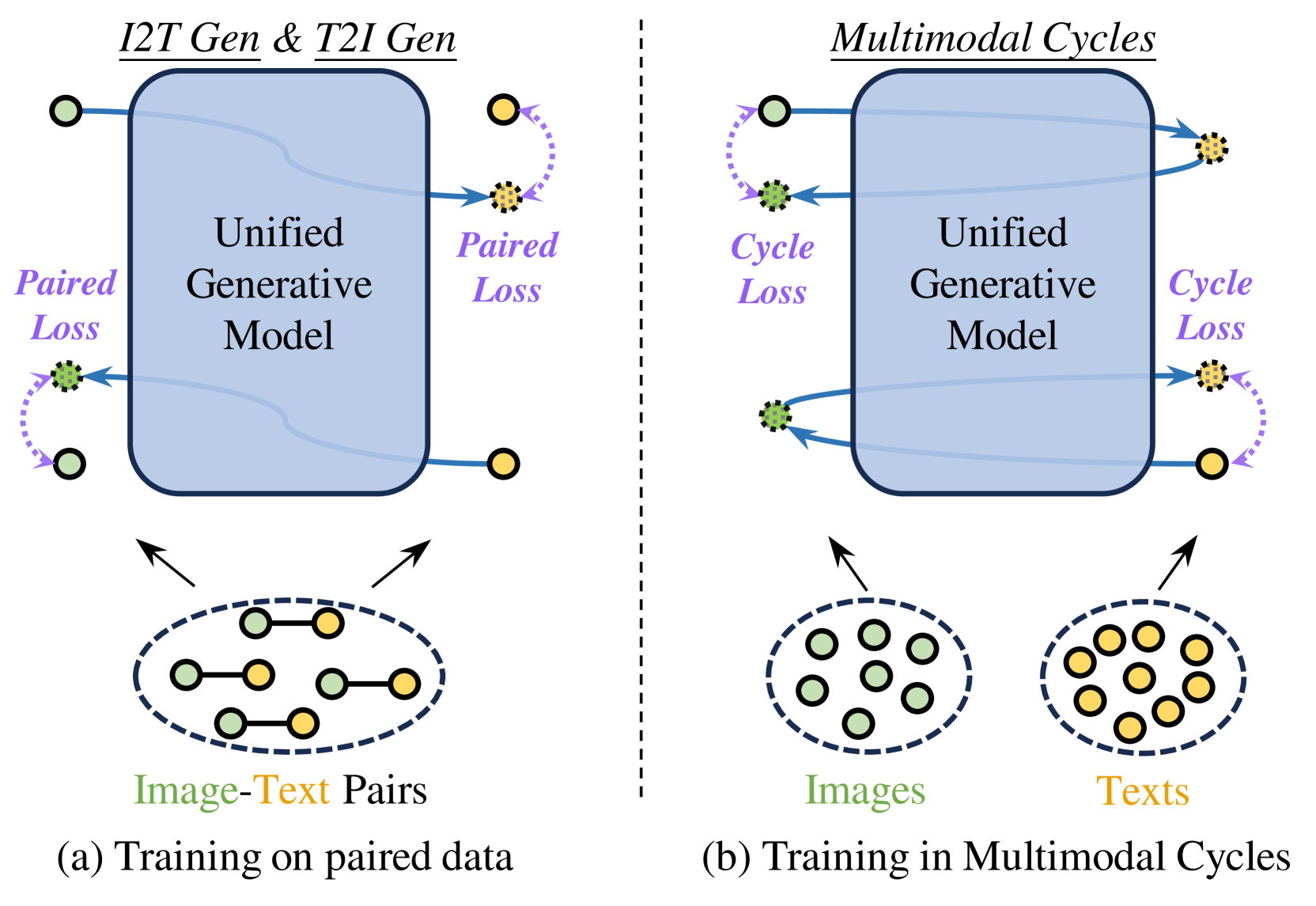
核心思路:DoraCycle的核心思路是利用多模态循环一致性,即通过文本生成图像,再由图像生成文本,或者反过来,图像生成文本,再由文本生成图像,保证循环前后模态内容的一致性。通过这种循环一致性约束,模型可以在没有配对数据的情况下学习到不同模态之间的映射关系,从而实现领域自适应。
技术框架:DoraCycle包含两个多模态循环:文本到图像到文本循环和图像到文本到图像循环。这两个循环共享一个统一的生成模型,该模型可以实现文本到图像的生成和图像到文本的生成。在训练过程中,模型通过最小化循环端点的交叉熵损失进行优化,即文本到图像再到文本的循环中,生成的文本要尽可能接近原始文本,图像到文本再到图像的循环中,生成的图像要尽可能接近原始图像。
关键创新:DoraCycle的关键创新在于利用多模态循环一致性来实现非配对数据的领域自适应。与传统的领域自适应方法相比,DoraCycle不需要大量的配对数据,只需要非配对的图像和文本数据即可。这大大降低了领域自适应的成本,使得模型可以更容易地应用到各种实际场景中。
关键设计:DoraCycle使用交叉熵损失作为循环一致性的约束。具体来说,对于文本到图像再到文本的循环,模型使用生成的文本和原始文本之间的交叉熵损失来衡量循环一致性。对于图像到文本再到图像的循环,模型使用生成的图像和原始图像之间的交叉熵损失来衡量循环一致性。此外,模型还使用了对抗训练来提高生成图像的质量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DoraCycle在风格化任务上表现出色,仅使用非配对数据即可实现有效的领域自适应。对于涉及新配对知识的任务,例如特定身份的图像生成,DoraCycle只需要少量配对数据和大量非配对数据即可达到良好的效果。这表明DoraCycle具有很强的泛化能力和适应性。
🎯 应用场景
DoraCycle具有广泛的应用前景,例如图像风格迁移、文本驱动的图像编辑、特定人物的图像生成等。该方法可以应用于艺术创作、广告设计、游戏开发等领域,为用户提供更加个性化和定制化的内容生成服务。未来,DoraCycle可以进一步扩展到其他模态,例如音频和视频,实现更加丰富和多样的内容生成。
📄 摘要(原文)
Adapting generative models to specific domains presents an effective solution for satisfying specialized requirements. However, adapting to some complex domains remains challenging, especially when these domains require substantial paired data to capture the targeted distributions. Since unpaired data from a single modality, such as vision or language, is more readily available, we utilize the bidirectional mappings between vision and language learned by the unified generative model to enable training on unpaired data for domain adaptation. Specifically, we propose DoraCycle, which integrates two multimodal cycles: text-to-image-to-text and image-to-text-to-image. The model is optimized through cross-entropy loss computed at the cycle endpoints, where both endpoints share the same modality. This facilitates self-evolution of the model without reliance on annotated text-image pairs. Experimental results demonstrate that for tasks independent of paired knowledge, such as stylization, DoraCycle can effectively adapt the unified model using only unpaired data. For tasks involving new paired knowledge, such as specific identities, a combination of a small set of paired image-text examples and larger-scale unpaired data is sufficient for effective domain-oriented adaptation. The code will be released at https://github.com/showlab/DoraCycle.