DongbaMIE: A Multimodal Information Extraction Dataset for Evaluating Semantic Understanding of Dongba Pictograms
作者: Xiaojun Bi, Shuo Li, Junyao Xing, Ziyue Wang, Fuwen Luo, Weizheng Qiao, Lu Han, Ziwei Sun, Peng Li, Yang Liu
分类: cs.CV
发布日期: 2025-03-05 (更新: 2025-05-22)
备注: Our dataset can be obtained from: https://github.com/thinklis/DongbaMIE
💡 一句话要点
构建DongbaMIE数据集,用于评估东巴象形文字语义理解的多模态信息抽取
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 东巴象形文字 多模态信息抽取 数据集构建 语义理解 文化遗产保护
📋 核心要点
- 现有研究缺乏东巴象形文字语义理解的相关数据集,阻碍了该领域的研究进展。
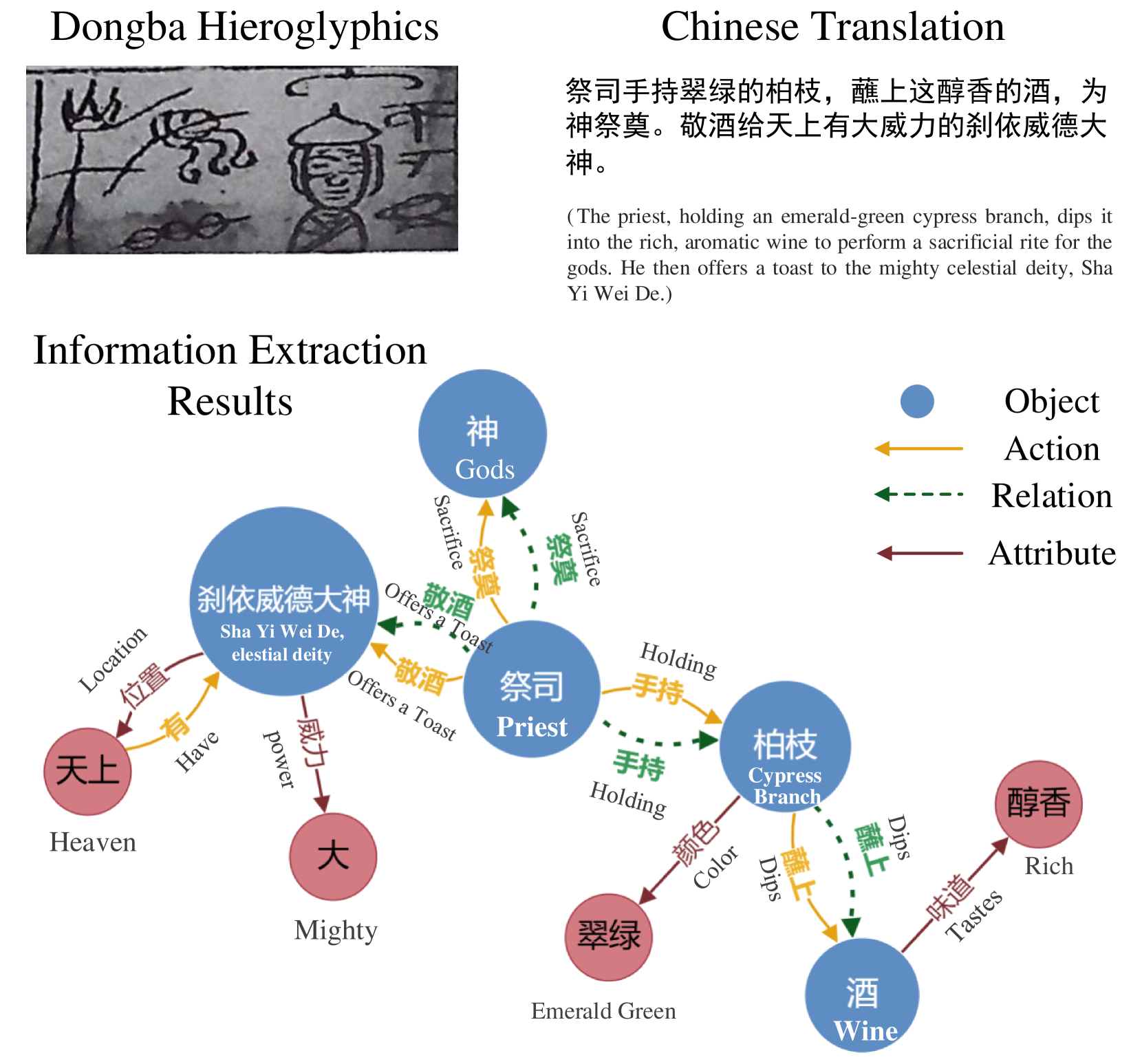
- 论文构建了DongbaMIE数据集,包含图像和对应的中文语义标注,覆盖对象、动作、关系和属性四个维度。
- 实验表明,主流多模态大模型在零样本和少样本学习下表现不佳,有监督微调后性能有所提升,但仍面临挑战。
📝 摘要(中文)
本文构建了首个专注于东巴象形文字多模态信息抽取的 extbf{DongbaMIE}数据集。东巴象形文字是世界上唯一仍在使用的象形文字,其象形表意特征蕴含着丰富的文化和语境信息。该数据集包含东巴象形文字的图像及其对应的中文语义标注,包括23,530个句子级别和2,539个段落级别的高质量文本-图像对。标注涵盖四个语义维度:对象、动作、关系和属性。对主流多模态大型语言模型的系统评估表明,这些模型在零样本和少样本学习下难以高效地执行东巴象形文字的信息抽取。虽然有监督的微调可以提高性能,但目前准确提取复杂的语义仍然是一个巨大的挑战。
🔬 方法详解
问题定义:论文旨在解决东巴象形文字语义理解中的信息抽取问题。现有方法由于缺乏高质量的数据集,难以有效训练模型,导致对东巴象形文字的语义理解能力不足。主流多模态大模型在处理这种特殊的象形文字时,面临着零样本和小样本学习的挑战,无法直接应用。
核心思路:论文的核心思路是构建一个高质量的多模态数据集DongbaMIE,该数据集包含丰富的东巴象形文字图像和对应的语义标注,涵盖对象、动作、关系和属性四个维度。通过提供充足的训练数据,促进模型学习东巴象形文字的语义信息,从而提升信息抽取性能。
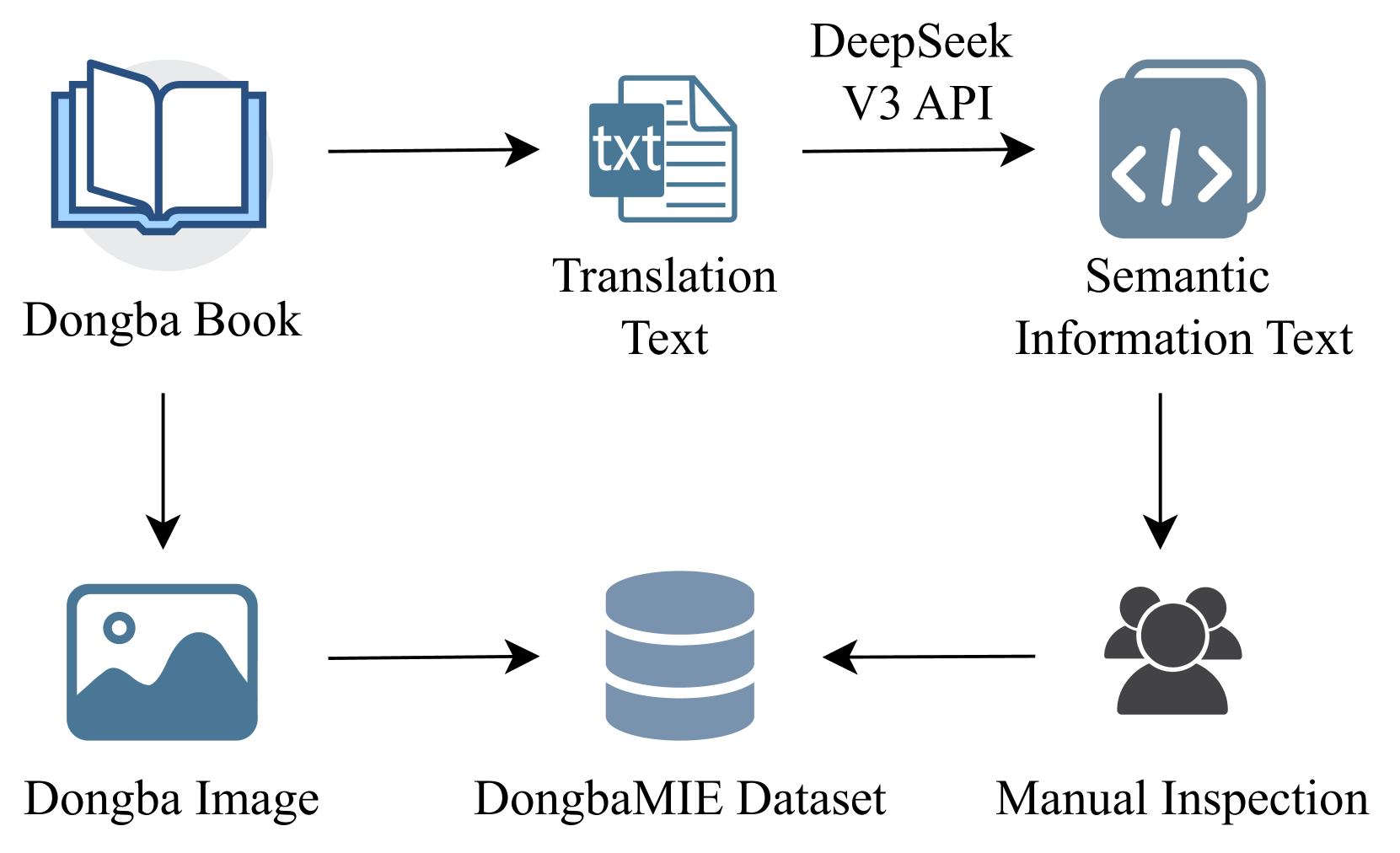
技术框架:该研究的主要工作是数据集的构建。首先,收集东巴象形文字的图像数据,并进行清洗和预处理。然后,对图像进行人工标注,标注内容包括对象、动作、关系和属性四个语义维度。标注完成后,对数据进行质量控制,确保标注的准确性和一致性。最后,将数据整理成句子级别和段落级别的文本-图像对,形成最终的DongbaMIE数据集。
关键创新:该论文的关键创新在于构建了首个专注于东巴象形文字多模态信息抽取的数据集。与现有数据集相比,DongbaMIE数据集专门针对东巴象形文字的特点进行设计,包含丰富的语义信息和高质量的标注,为相关研究提供了重要的数据基础。
关键设计:数据集包含23,530个句子级别和2,539个段落级别的文本-图像对。标注涵盖四个语义维度:对象、动作、关系和属性。论文没有涉及具体的模型设计或训练策略,而是侧重于数据集的构建和评估。评估实验使用了主流的多模态大型语言模型,并进行了零样本、少样本和有监督微调的实验。
🖼️ 关键图片

📊 实验亮点
实验结果表明,主流多模态大模型在DongbaMIE数据集上进行零样本和少样本学习时,信息抽取性能较差。通过有监督的微调,模型性能得到显著提升,但准确提取复杂语义仍然面临挑战。这表明DongbaMIE数据集能够有效评估模型对东巴象形文字语义的理解能力,并为未来的研究提供了明确的方向。
🎯 应用场景
该研究成果可应用于东巴文化的数字化保护和传承,例如,构建智能化的东巴象形文字识别和翻译系统,辅助研究人员进行文献解读和文化研究。此外,该数据集也可以促进多模态信息抽取技术的发展,为其他小众语言和文化遗产的保护提供借鉴。
📄 摘要(原文)
Dongba pictographic is the only pictographic script still in use in the world. Its pictorial ideographic features carry rich cultural and contextual information. However, due to the lack of relevant datasets, research on semantic understanding of Dongba hieroglyphs has progressed slowly. To this end, we constructed \textbf{DongbaMIE} - the first dataset focusing on multimodal information extraction of Dongba pictographs. The dataset consists of images of Dongba hieroglyphic characters and their corresponding semantic annotations in Chinese. It contains 23,530 sentence-level and 2,539 paragraph-level high-quality text-image pairs. The annotations cover four semantic dimensions: object, action, relation and attribute. Systematic evaluation of mainstream multimodal large language models shows that the models are difficult to perform information extraction of Dongba hieroglyphs efficiently under zero-shot and few-shot learning. Although supervised fine-tuning can improve the performance, accurate extraction of complex semantics is still a great challenge at present.