Afford-X: Generalizable and Slim Affordance Reasoning for Task-oriented Manipulation
作者: Xiaomeng Zhu, Yuyang Li, Leiyao Cui, Pengfei Li, Huan-ang Gao, Yixin Zhu, Hao Zhao
分类: cs.CV, cs.RO
发布日期: 2025-03-05 (更新: 2025-09-12)
💡 一句话要点
Afford-X:面向任务操作的通用且轻量级的可供性推理模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 可供性推理 任务导向操作 多模态融合 机器人操作 大型数据集 注意力机制 轻量级模型
📋 核心要点
- 现有可供性推理模型泛化能力弱,难以适应新场景,而大型语言模型部署成本高,不适合本地设备。
- Afford-X通过构建大规模数据集LVIS-Aff,并设计Verb Attention和Bi-Fusion模块,提升模型的多模态理解和泛化能力。
- Afford-X在可供性推理任务上取得了显著提升,参数量小,推理速度快,适合部署在机器人等本地设备上。
📝 摘要(中文)
本文提出了一种用于任务导向操作的可供性推理方法。可供性推理,即基于物理属性推断物体功能的能力,对于人类和人工智能的任务规划至关重要。现有的可供性推理模型泛化性不足,限制了其在新场景中的应用。同时,大型语言模型(LLMs)虽然具有推理能力,但难以在本地设备上部署。为此,本文构建了一个大规模数据集LVIS-Aff,包含1496个任务和11.9万张图像,旨在提高可供性推理的泛化能力。基于此数据集,开发了Afford-X,一个端到端的可训练可供性推理模型,它结合了Verb Attention和Bi-Fusion模块来提升多模态理解。Afford-X的性能比非LLM方法提高了12.1%,比之前的会议论文提高了1.2%。此外,它仅有1.87亿参数,推理速度比GPT-4V API快近50倍。实验表明,Afford-X能够有效支持机器人在各种任务和环境中进行任务导向的操作。
🔬 方法详解
问题定义:论文旨在解决现有可供性推理模型泛化能力不足,以及大型语言模型部署成本高的问题。现有方法难以在新场景中准确推断物体的功能,限制了其在任务导向操作中的应用。
核心思路:论文的核心思路是构建一个大规模、多样化的数据集LVIS-Aff,并设计一个轻量级的可训练模型Afford-X,以提高可供性推理的泛化能力和效率。通过Verb Attention和Bi-Fusion模块,增强模型对多模态信息的理解,从而更准确地推断物体的功能。
技术框架:Afford-X是一个端到端的可训练模型,其整体架构包含以下几个主要模块:1) 图像特征提取模块:用于提取输入图像的视觉特征。2) 文本特征提取模块:用于提取任务描述或指令的文本特征。3) Verb Attention模块:用于关注与任务相关的动词,从而更好地理解任务目标。4) Bi-Fusion模块:用于融合视觉和文本特征,实现多模态信息的有效交互。5) 可供性预测模块:基于融合后的特征,预测物体在特定任务中的可供性。
关键创新:论文的关键创新在于:1) 构建了大规模数据集LVIS-Aff,为可供性推理提供了更丰富的训练数据。2) 提出了Verb Attention模块,能够有效关注与任务相关的动词,提高模型对任务目标的理解。3) 设计了Bi-Fusion模块,能够更好地融合视觉和文本特征,提升多模态理解能力。与现有方法相比,Afford-X在泛化能力和效率方面都具有优势。
关键设计:Verb Attention模块通过注意力机制,根据任务描述中的动词,对视觉特征进行加权,从而突出与任务相关的区域。Bi-Fusion模块采用双向融合的方式,分别将视觉特征和文本特征映射到同一空间,然后进行融合。损失函数采用交叉熵损失,用于优化可供性预测的准确性。模型的参数量控制在1.87亿,以保证推理速度和部署的便捷性。
🖼️ 关键图片

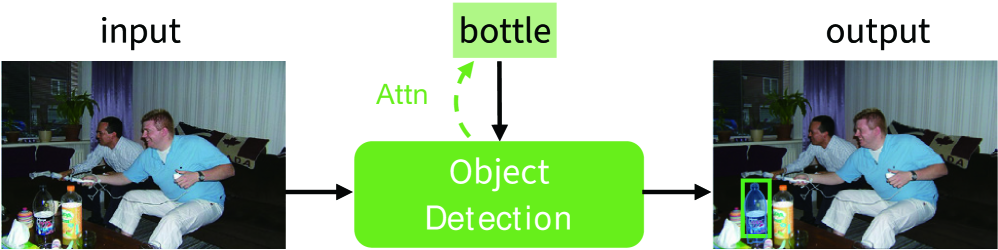
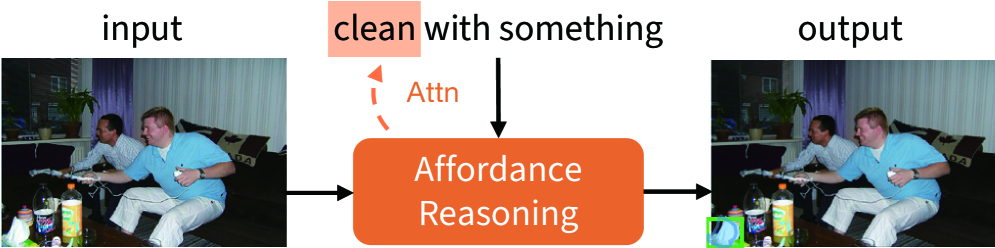
📊 实验亮点
Afford-X在LVIS-Aff数据集上取得了显著的性能提升,相比于非LLM方法,性能提升高达12.1%,相比于之前的会议论文,也提升了1.2%。同时,Afford-X保持了轻量级的模型结构,参数量仅为1.87亿,推理速度比GPT-4V API快近50倍。这些实验结果表明,Afford-X在可供性推理的准确性、效率和泛化能力方面都具有优势。
🎯 应用场景
Afford-X可应用于机器人操作、智能家居、自动驾驶等领域。它可以帮助机器人在未知环境中理解物体的功能,从而完成各种任务,例如抓取、放置、组装等。在智能家居中,Afford-X可以帮助设备理解用户的意图,提供更智能的服务。在自动驾驶中,它可以帮助车辆理解交通标志和道路状况,提高驾驶安全性。该研究的实际价值在于提高了机器人和人工智能系统的自主性和适应性,未来有望推动这些技术在现实世界中的广泛应用。
📄 摘要(原文)
Object affordance reasoning, the ability to infer object functionalities based on physical properties, is fundamental for task-oriented planning and activities in both humans and Artificial Intelligence (AI). This capability, required for planning and executing daily activities in a task-oriented manner, relies on commonsense knowledge of object physics and functionalities, extending beyond simple object recognition. Current computational models for affordance reasoning from perception lack generalizability, limiting their applicability in novel scenarios. Meanwhile, comprehensive Large Language Models (LLMs) with emerging reasoning capabilities are challenging to deploy on local devices for task-oriented manipulations. Here, we introduce LVIS-Aff, a large-scale dataset comprising 1,496 tasks and 119k images, designed to enhance the generalizability of affordance reasoning from perception. Utilizing this dataset, we develop Afford-X, an end-to-end trainable affordance reasoning model that incorporates Verb Attention and Bi-Fusion modules to improve multi-modal understanding. This model achieves up to a 12.1% performance improvement over the best-reported results from non-LLM methods, while also demonstrating a 1.2% enhancement compared to our previous conference paper. Additionally, it maintains a compact 187M parameter size and infers nearly 50 times faster than the GPT-4V API. Our work demonstrates the potential for efficient, generalizable affordance reasoning models that can be deployed on local devices for task-oriented manipulations. We showcase Afford-X's effectiveness in enabling task-oriented manipulations for robots across various tasks and environments, underscoring its efficiency and broad implications for advancing robotics and AI systems in real-world applications.