See What You Are Told: Visual Attention Sink in Large Multimodal Models
作者: Seil Kang, Jinyeong Kim, Junhyeok Kim, Seong Jae Hwang
分类: cs.CV, cs.AI
发布日期: 2025-03-05
💡 一句话要点
揭示大模型视觉注意力陷阱,提出免训练的视觉注意力重分配方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态模型 视觉注意力 注意力机制 视觉理解 视觉幻觉 注意力重分配 Transformer 大语言模型
📋 核心要点
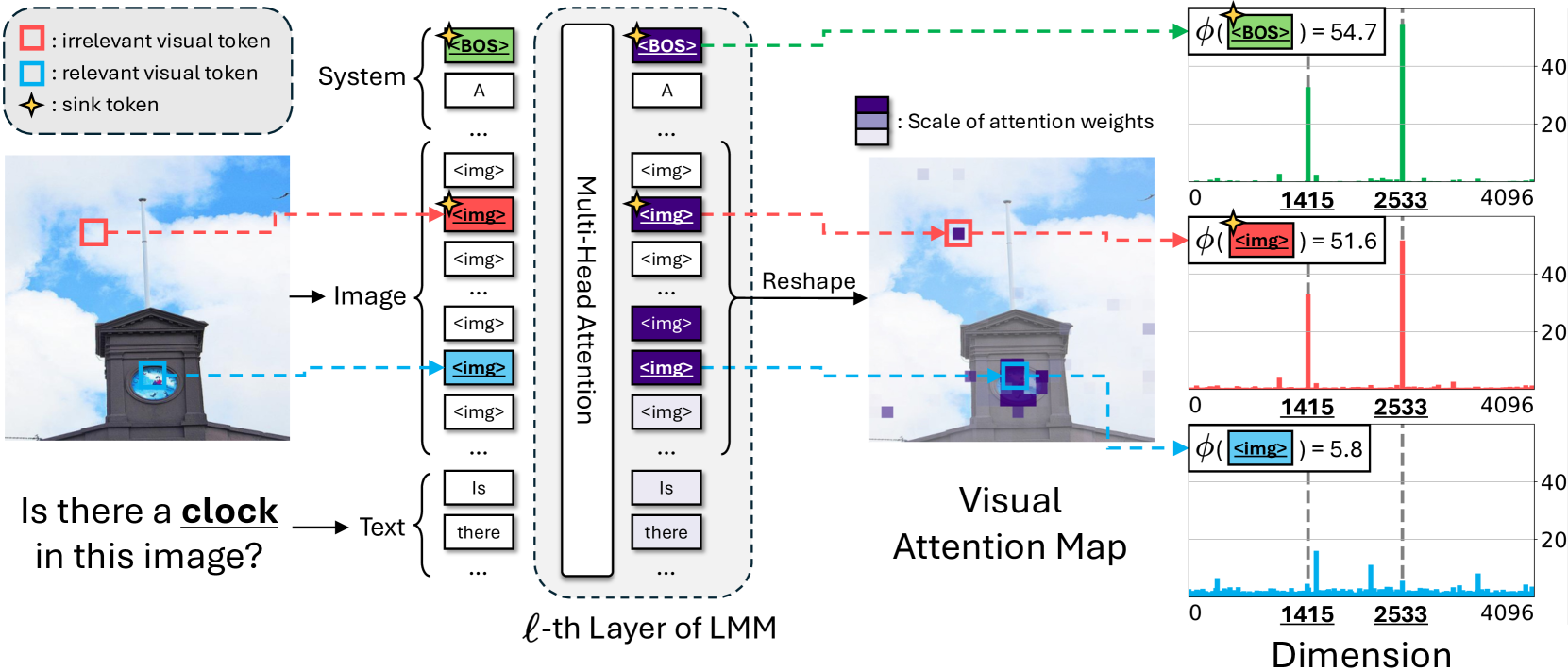
- 现有LMMs存在视觉注意力陷阱问题,即模型会将高注意力权重分配给与文本无关的特定视觉token。
- 论文提出视觉注意力重分配(VAR)方法,通过重新分配注意力预算来增强模型对图像的关注。
- 实验表明,VAR无需额外训练即可提升LMMs在多种视觉-语言任务上的性能,并有效缓解视觉幻觉。
📝 摘要(中文)
大型多模态模型(LMMs)通过Transformer解码器中文本和视觉token之间的注意力机制来“观察”图像。理想情况下,这些模型应专注于与文本token相关的关键视觉信息。然而,最近的研究表明,LMMs倾向于持续地将高注意力权重分配给特定的视觉token,即使这些token与相应的文本无关。本研究调查了这些无关视觉token出现的原因,并检验了它们的特性。研究结果表明,这种行为是由于某些隐藏状态维度的大量激活而产生的,类似于语言模型中的注意力陷阱。因此,我们将这种现象称为视觉注意力陷阱。我们的分析表明,移除这些无关的视觉陷阱token不会影响模型性能,尽管它们接收到很高的注意力权重。因此,我们将对这些token的注意力作为剩余资源进行回收,重新分配注意力预算以增强对图像的关注。为此,我们引入了视觉注意力重分配(VAR),这是一种在以图像为中心的注意力头中重新分配注意力的方法,我们认为这些注意力头天生就专注于视觉信息。VAR可以无缝地应用于不同的LMMs,以提高在各种任务上的性能,包括通用视觉-语言任务、视觉幻觉任务和以视觉为中心的任务,所有这些都无需额外的训练、模型或推理步骤。实验结果表明,VAR通过调整其内部注意力机制,使LMMs能够更有效地处理视觉信息,为增强LMMs的多模态能力提供了一个新的方向。
🔬 方法详解
问题定义:大型多模态模型在处理视觉信息时,存在“视觉注意力陷阱”问题。模型会将过多的注意力分配给图像中与当前文本描述无关的特定区域(视觉token),导致模型无法有效关注关键视觉信息。现有方法缺乏对这种现象的有效解释和解决方案,导致模型性能受限。
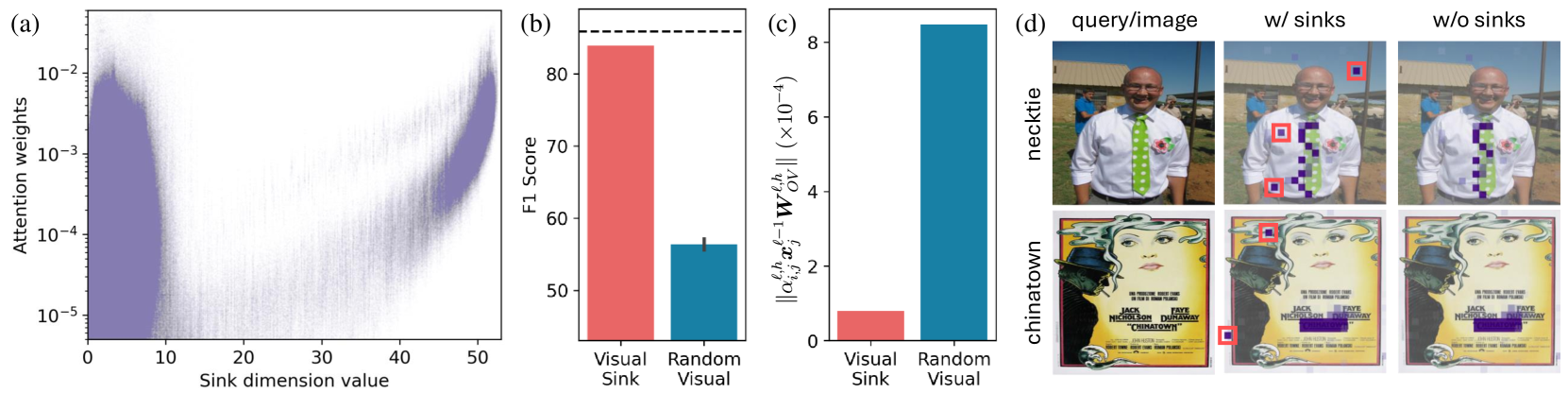
核心思路:论文的核心思路是识别并利用这些“视觉注意力陷阱”token。研究发现,这些token虽然获得了很高的注意力权重,但移除它们并不会显著影响模型性能。因此,可以将分配给这些token的注意力视为冗余资源,并将其重新分配给更重要的视觉区域,从而提高模型对关键视觉信息的关注度。
技术框架:论文提出的Visual Attention Redistribution (VAR) 方法主要包含以下步骤:1) 识别图像中心注意力头:通过分析不同注意力头对视觉信息的关注程度,筛选出主要关注图像信息的注意力头。2) 识别视觉注意力陷阱token:确定哪些视觉token获得了过高的注意力权重,但与当前文本描述无关。3) 注意力重分配:将分配给视觉注意力陷阱token的注意力权重重新分配给其他视觉token,从而增强模型对关键视觉信息的关注。
关键创新:该方法最重要的创新点在于,它无需额外的训练或模型修改,即可有效提升LMMs的视觉理解能力。通过简单地重新分配现有的注意力资源,VAR能够显著提高模型在各种视觉-语言任务上的性能。此外,该研究揭示了LMMs中视觉注意力陷阱现象的存在,为后续研究提供了新的方向。
关键设计:VAR的关键设计在于如何有效地识别图像中心注意力头和视觉注意力陷阱token。论文可能采用了一些启发式规则或统计方法来完成这些任务。例如,可以通过分析注意力权重分布的熵值或方差来识别图像中心注意力头。对于视觉注意力陷阱token的识别,可以考虑使用文本相关性分析或视觉显著性检测等方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VAR方法在多个视觉-语言任务上取得了显著的性能提升。例如,在通用视觉-语言任务中,VAR能够提高模型在图像描述生成和视觉问答任务上的准确率。在视觉幻觉任务中,VAR能够有效减少模型产生的错误视觉描述。更重要的是,VAR在无需额外训练的情况下,即可实现这些性能提升,使其具有很高的实用价值。
🎯 应用场景
该研究成果可广泛应用于各种需要视觉理解能力的多模态任务中,例如图像描述生成、视觉问答、视觉推理等。通过提升LMMs的视觉理解能力,可以改善人机交互体验,提高自动化系统的智能化水平,并为智能机器人、自动驾驶等领域的发展提供技术支持。此外,该方法还有助于缓解LMMs的视觉幻觉问题,提高模型的可靠性和安全性。
📄 摘要(原文)
Large multimodal models (LMMs) "see" images by leveraging the attention mechanism between text and visual tokens in the transformer decoder. Ideally, these models should focus on key visual information relevant to the text token. However, recent findings indicate that LMMs have an extraordinary tendency to consistently allocate high attention weights to specific visual tokens, even when these tokens are irrelevant to the corresponding text. In this study, we investigate the property behind the appearance of these irrelevant visual tokens and examine their characteristics. Our findings show that this behavior arises due to the massive activation of certain hidden state dimensions, which resembles the attention sink found in language models. Hence, we refer to this phenomenon as the visual attention sink. In particular, our analysis reveals that removing the irrelevant visual sink tokens does not impact model performance, despite receiving high attention weights. Consequently, we recycle the attention to these tokens as surplus resources, redistributing the attention budget to enhance focus on the image. To achieve this, we introduce Visual Attention Redistribution (VAR), a method that redistributes attention in image-centric heads, which we identify as innately focusing on visual information. VAR can be seamlessly applied across different LMMs to improve performance on a wide range of tasks, including general vision-language tasks, visual hallucination tasks, and vision-centric tasks, all without the need for additional training, models, or inference steps. Experimental results demonstrate that VAR enables LMMs to process visual information more effectively by adjusting their internal attention mechanisms, offering a new direction to enhancing the multimodal capabilities of LMMs.