Label-Efficient LiDAR Semantic Segmentation with 2D-3D Vision Transformer Adapters
作者: Julia Hindel, Rohit Mohan, Jelena Bratulic, Daniele Cattaneo, Thomas Brox, Abhinav Valada
分类: cs.CV
发布日期: 2025-03-05
💡 一句话要点
提出BALViT,利用2D-3D Vision Transformer适配器实现LiDAR语义分割的标签高效学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LiDAR语义分割 视觉Transformer 2D-3D适配器 标签高效学习 知识迁移
📋 核心要点
- 现有LiDAR语义分割模型依赖大量标注数据,且缺乏有效的预训练方法和视觉领域的知识迁移。
- BALViT利用冻结的视觉模型作为特征编码器,通过2D-3D适配器融合range-view和bird's-eye-view LiDAR信息。
- 在SemanticKITTI和nuScenes数据集上的实验表明,BALViT在少量数据下显著优于现有方法,实现了标签高效学习。
📝 摘要(中文)
LiDAR语义分割模型通常从随机初始化开始训练,因为缺乏大型、多样化的数据集阻碍了通用预训练。此外,大多数点云分割架构都包含自定义网络层,限制了视觉架构的进步迁移。受通用基础模型的启发,我们提出了BALViT,一种利用冻结视觉模型作为非模态特征编码器来学习强大的LiDAR编码器的新方法。具体来说,BALViT结合了range-view和bird's-eye-view LiDAR编码机制,并通过一种新颖的2D-3D适配器将它们结合起来。range-view特征通过冻结的图像骨干网络处理,而bird's-eye-view分支通过多次交叉注意力交互来增强它们。因此,我们不断地用领域相关的知识改进视觉网络,从而产生一种强大的标签高效LiDAR编码机制。在SemanticKITTI和nuScenes基准上的大量评估表明,BALViT在小数据量的情况下优于最先进的方法。代码和模型已公开。
🔬 方法详解
问题定义:LiDAR语义分割任务需要大量的标注数据,而现有方法难以有效利用视觉领域的预训练模型,导致在数据量有限的情况下性能不佳。现有的点云分割架构通常包含自定义网络层,限制了视觉领域先进架构的迁移能力。
核心思路:利用预训练的视觉模型作为LiDAR数据的特征编码器,通过设计2D-3D适配器,将range-view图像特征和bird's-eye-view点云特征进行融合,从而实现知识迁移和标签高效学习。核心在于利用视觉模型强大的特征提取能力,并将其适配到LiDAR数据上。
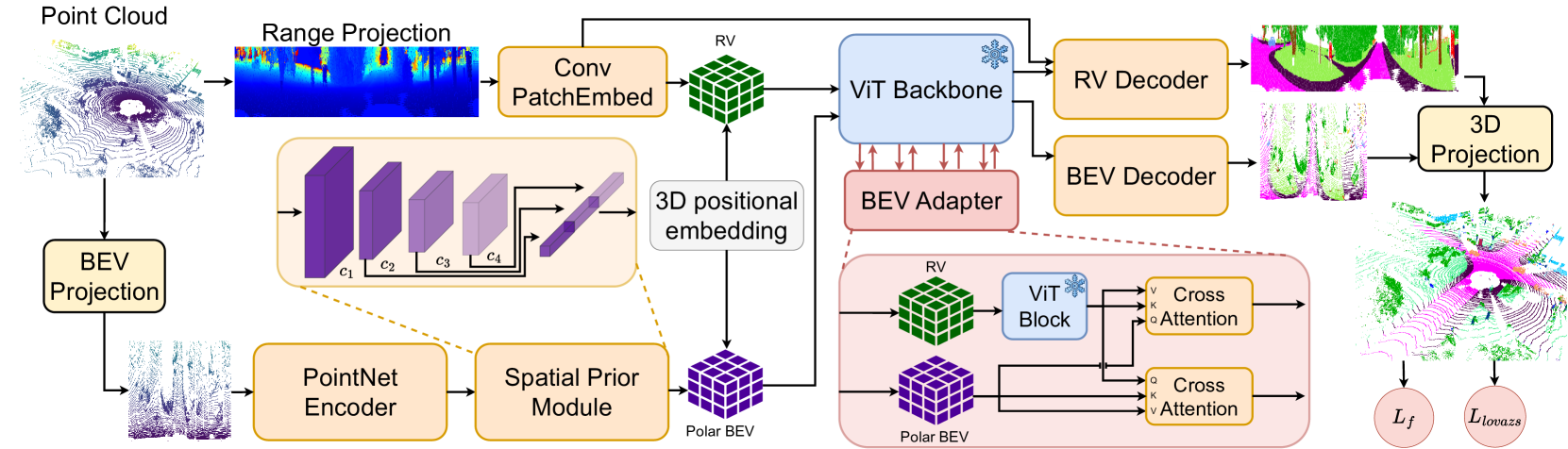
技术框架:BALViT包含两个主要分支:range-view分支和bird's-eye-view分支。range-view分支使用冻结的视觉骨干网络(如Vision Transformer)提取特征。bird's-eye-view分支则通过交叉注意力机制与range-view特征进行交互,从而增强特征表示。最后,通过2D-3D适配器将两个分支的特征融合,用于最终的语义分割。
关键创新:该方法的核心创新在于2D-3D适配器的设计,它能够有效地将视觉模型的特征迁移到LiDAR数据上,并融合不同视角的特征。此外,利用冻结的视觉模型避免了从头开始训练,大大减少了对标注数据的需求。与现有方法相比,BALViT更有效地利用了视觉领域的知识,实现了标签高效学习。
关键设计:range-view分支采用预训练的Vision Transformer,并将其参数冻结,以防止在LiDAR数据上过拟合。bird's-eye-view分支使用Transformer结构,并通过交叉注意力机制与range-view特征进行交互。2D-3D适配器采用简单的线性层或卷积层,将两个分支的特征映射到相同的维度空间,然后进行融合。损失函数采用标准的交叉熵损失函数,用于监督语义分割任务。
🖼️ 关键图片


📊 实验亮点
BALViT在SemanticKITTI和nuScenes数据集上进行了评估,结果表明,在少量数据的情况下,BALViT显著优于现有的最先进方法。例如,在SemanticKITTI数据集上,使用1/8的数据进行训练,BALViT的性能超过了使用全部数据训练的基线模型。这表明BALViT具有很强的标签高效学习能力。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智慧城市等领域。通过减少对大量标注数据的依赖,可以降低LiDAR语义分割模型的部署成本,加速相关技术的落地。未来,该方法可以扩展到其他传感器模态,实现更鲁棒、更高效的环境感知。
📄 摘要(原文)
LiDAR semantic segmentation models are typically trained from random initialization as universal pre-training is hindered by the lack of large, diverse datasets. Moreover, most point cloud segmentation architectures incorporate custom network layers, limiting the transferability of advances from vision-based architectures. Inspired by recent advances in universal foundation models, we propose BALViT, a novel approach that leverages frozen vision models as amodal feature encoders for learning strong LiDAR encoders. Specifically, BALViT incorporates both range-view and bird's-eye-view LiDAR encoding mechanisms, which we combine through a novel 2D-3D adapter. While the range-view features are processed through a frozen image backbone, our bird's-eye-view branch enhances them through multiple cross-attention interactions. Thereby, we continuously improve the vision network with domain-dependent knowledge, resulting in a strong label-efficient LiDAR encoding mechanism. Extensive evaluations of BALViT on the SemanticKITTI and nuScenes benchmarks demonstrate that it outperforms state-of-the-art methods on small data regimes. We make the code and models publicly available at: http://balvit.cs.uni-freiburg.de.