Mocap-2-to-3: Multi-view Lifting for Monocular Motion Recovery with 2D Pretraining
作者: Zhumei Wang, Zechen Hu, Ruoxi Guo, Huaijin Pi, Ziyong Feng, Sida Peng, Xiaowei Zhou, Mingtao Pei, Siyuan Huang
分类: cs.CV
发布日期: 2025-03-05 (更新: 2025-07-31)
备注: Project page: https://wangzhumei.github.io/mocap-2-to-3/
💡 一句话要点
Mocap-2-to-3:利用2D预训练的多视角提升进行单目运动恢复
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 单目运动恢复 3D人体姿态估计 2D预训练 多视角提升 扩散模型
📋 核心要点
- 现有单目运动恢复方法依赖3D数据,泛化性差,且难以估计绝对尺度的3D姿态。
- Mocap-2-to-3利用2D数据预训练,通过多视角提升从单目输入恢复绝对3D运动。
- 实验表明,该方法在运动真实感、绝对定位和泛化能力上优于现有技术。
📝 摘要(中文)
本文提出Mocap-2-to-3框架,旨在解决单目输入下绝对人体运动恢复的难题。现有方法依赖于有限环境下的3D训练数据,泛化能力受限,且难以从单目输入估计具有度量尺度的姿态。Mocap-2-to-3通过2D数据预训练实现单目输入的多视角提升,从而重建具有绝对位置的、度量精确的3D运动。该方法首先在大量2D数据集上预训练单视角扩散模型,然后使用公开3D数据微调多视角模型,以实现从单目输入生成视角一致的运动,使模型通过2D数据获取动作先验和多样性。此外,提出一种新的人体运动表示,解耦局部姿态和全局运动的学习,同时编码地面几何先验以加速收敛,从而在推理过程中逐步恢复绝对空间中的运动。实验结果表明,该方法在真实场景基准测试中超越了现有技术,在相机空间运动真实感和世界坐标系下的人体定位方面均表现出优越的泛化能力。
🔬 方法详解
问题定义:现有单目运动恢复方法依赖于在有限环境中采集的3D训练数据,导致模型在真实场景中的泛化能力不足。此外,从单目图像中准确估计具有度量尺度的3D人体姿态是一个具有挑战性的问题,尤其是在绝对空间中恢复运动轨迹。
核心思路:本文的核心思路是利用大量易于获取的2D人体运动数据进行预训练,从而学习到丰富的动作先验和运动多样性。通过将复杂的3D运动分解为多视角合成,并结合多视角一致性约束,可以从单目输入中恢复出准确的3D运动。
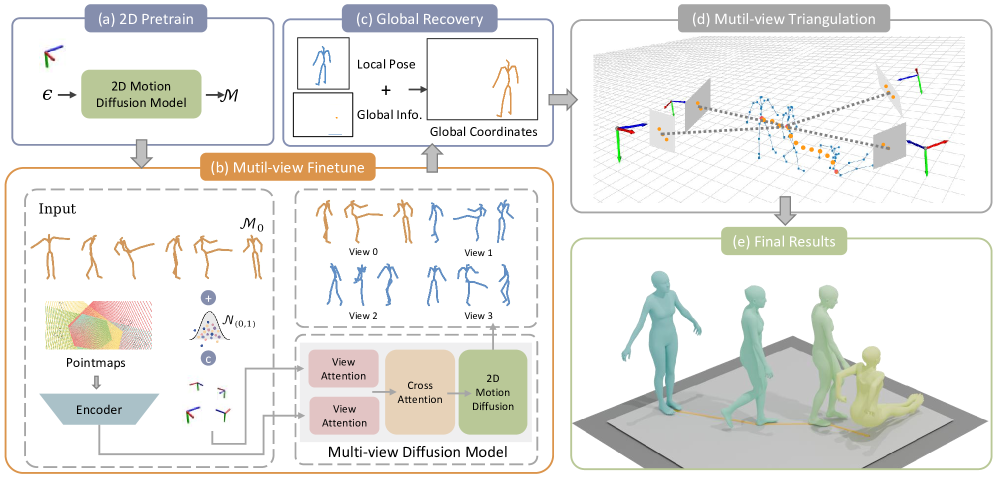
技术框架:Mocap-2-to-3框架包含两个主要阶段:2D预训练和多视角微调。首先,在大量的2D人体运动数据集上预训练一个单视角扩散模型,使其学习到丰富的动作先验。然后,使用公开的3D人体运动数据集微调一个多视角模型,该模型以单目图像作为输入,生成多个视角下一致的2D姿态序列,并最终提升为3D运动。此外,该框架还包含一个新颖的人体运动表示,用于解耦局部姿态和全局运动的学习。
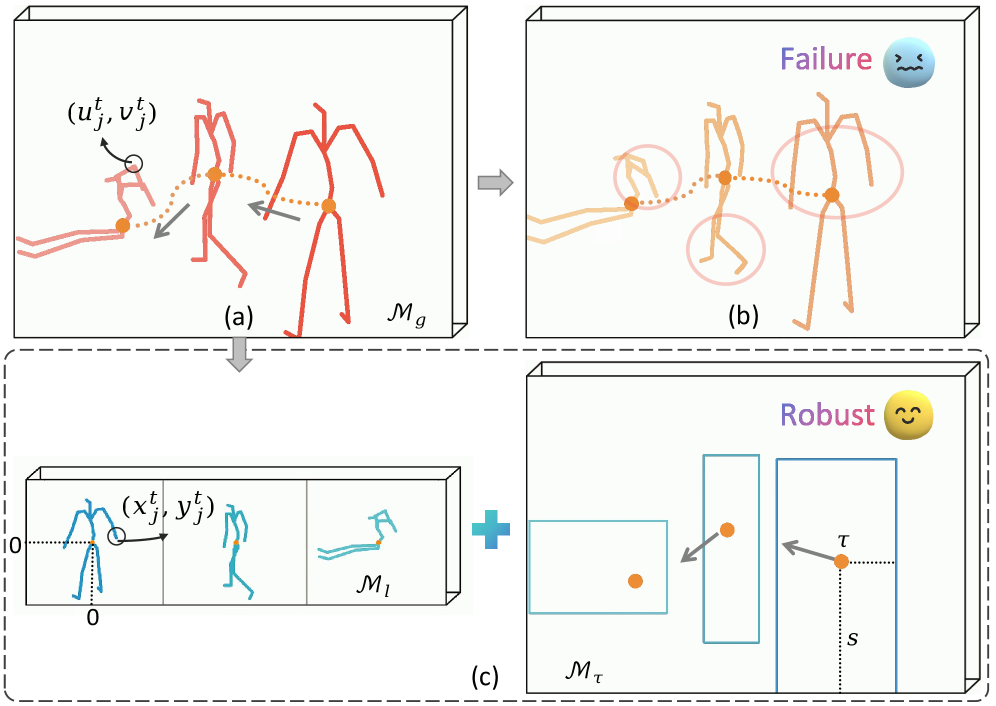
关键创新:该方法最重要的创新点在于利用2D数据进行预训练,从而克服了3D数据稀缺的问题,并显著提高了模型的泛化能力。此外,提出的解耦局部姿态和全局运动的人体运动表示,以及地面几何先验的引入,有助于更准确地恢复绝对空间中的运动。
关键设计:在2D预训练阶段,使用扩散模型生成高质量的2D姿态序列。在多视角微调阶段,使用视角一致性损失来约束不同视角下生成的2D姿态的一致性。人体运动表示将全局运动分解为平移和旋转,并分别进行学习。地面几何先验通过损失函数进行约束,促使模型生成符合物理规律的运动。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Mocap-2-to-3在Human3.6M和3DPW等数据集上取得了显著的性能提升,在相机空间运动真实感和世界坐标系下的人体定位方面均优于现有方法。尤其是在3DPW数据集上,该方法在绝对轨迹误差方面取得了显著的降低,表明其具有更强的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可广泛应用于虚拟现实、增强现实、游戏开发、动画制作、运动分析、康复训练等领域。通过单目视频即可重建真实的人体运动,无需昂贵的动作捕捉设备,降低了应用门槛,具有重要的实际应用价值和商业前景。未来可进一步扩展到多人运动捕捉、复杂环境交互等场景。
📄 摘要(原文)
Recovering absolute human motion from monocular inputs is challenging due to two main issues. First, existing methods depend on 3D training data collected from limited environments, constraining out-of-distribution generalization. The second issue is the difficulty of estimating metric-scale poses from monocular input. To address these challenges, we introduce Mocap-2-to-3, a novel framework that performs multi-view lifting from monocular input by leveraging 2D data pre-training, enabling the reconstruction of metrically accurate 3D motions with absolute positions. To leverage abundant 2D data, we decompose complex 3D motion into multi-view syntheses. We first pretrain a single-view diffusion model on extensive 2D datasets, then fine-tune a multi-view model using public 3D data to enable view-consistent motion generation from monocular input, allowing the model to acquire action priors and diversity through 2D data. Furthermore, to recover absolute poses, we propose a novel human motion representation that decouples the learning of local pose and global movements, while encoding geometric priors of the ground to accelerate convergence. This enables progressive recovery of motion in absolute space during inference. Experimental results on in-the-wild benchmarks demonstrate that our method surpasses state-of-the-art approaches in both camera-space motion realism and world-grounded human positioning, while exhibiting superior generalization capability. Our code will be made publicly available.