Variance-Aware Loss Scheduling for Multimodal Alignment in Low-Data Settings
作者: Sneh Pillai
分类: cs.CV
发布日期: 2025-03-05
备注: 8 pages, 4 figures
💡 一句话要点
提出方差感知损失调度方法,提升低数据量下多模态对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态对齐 对比学习 低数据学习 方差感知 损失调度
📋 核心要点
- 现有视觉-语言模型在低数据量下,对比学习易过拟合,导致模态对齐困难,训练过程不稳定。
- 提出方差感知损失调度方法,根据模型预测的统计变异性动态调整对比损失权重,优化训练过程。
- 实验表明,该方法在低数据量下提升了图像-文本检索准确率,并对噪声具有更强的鲁棒性。
📝 摘要(中文)
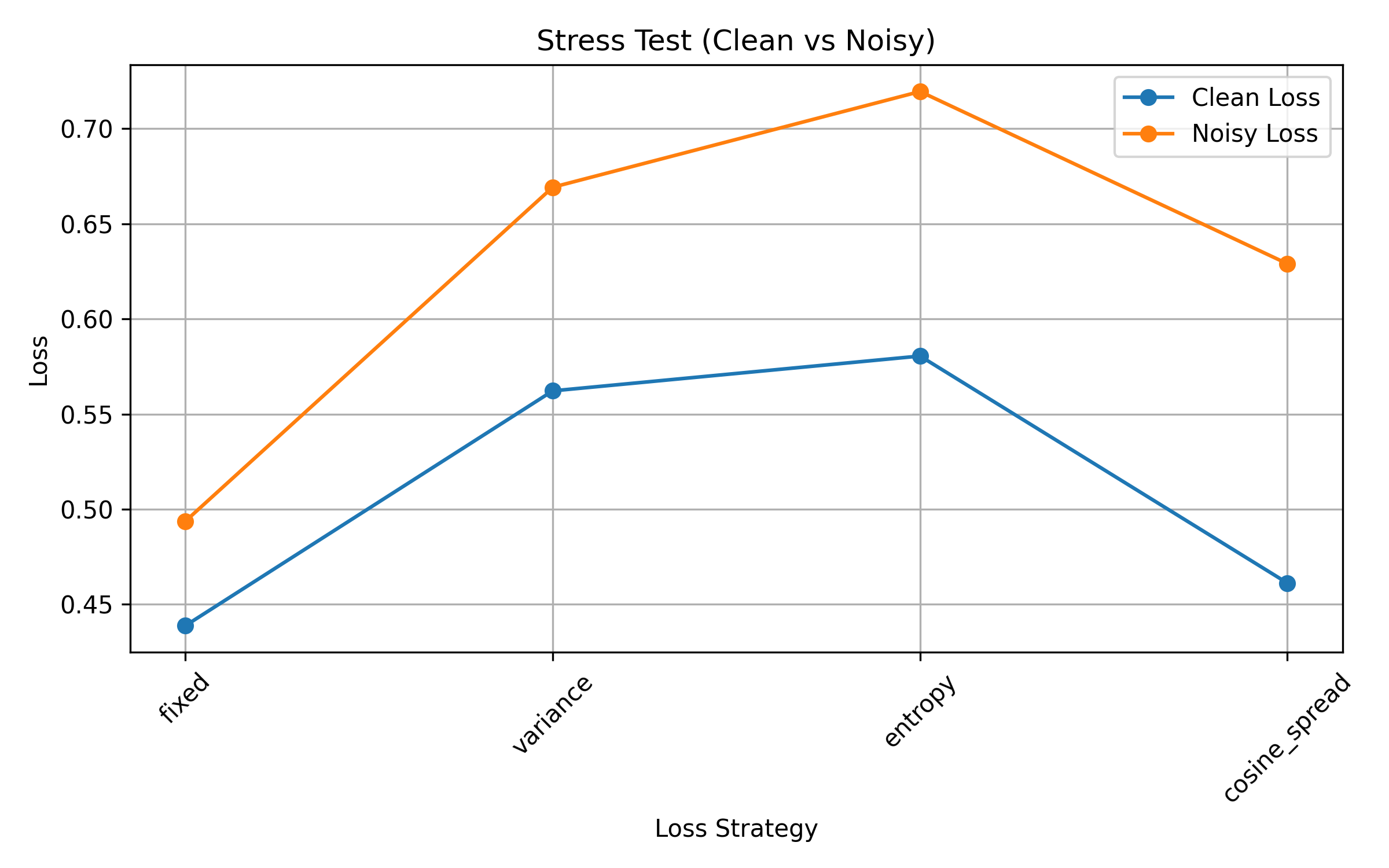
在图像-文本对齐任务中,训练视觉-语言模型通常需要大量数据以保证性能。在低数据场景下,标准的对比学习方法容易过拟合,导致训练不稳定,难以有效对齐不同模态的信息。本文提出了一种方差感知的损失调度方法,该方法基于模型对齐预测的统计变异性(不确定性)动态调整对比损失的权重。通过使用Flickr8k图像-文本数据集的子集来模拟低数据条件,实验表明,与固定权重的基线方法相比,该方法提高了图像-文本检索的准确率。同时,本文还与其他自适应权重策略(使用输出熵和余弦相似度分布)进行了比较,发现方差感知调度提供了最佳的整体权衡。定性分析表明,该方法产生了更独特的多模态嵌入,如t-SNE可视化所示。此外,在噪声注入的图像和文本压力测试中,方差引导的损失函数表现出更强的鲁棒性,在引入随机扰动时保持了更高的召回率。这些结果突出了自适应损失权重在低数据环境下多模态对齐中的优势。
🔬 方法详解
问题定义:论文旨在解决低数据量下,视觉-语言模型的多模态对齐问题。现有的对比学习方法在数据量不足时,容易过拟合,导致模型学习到的模态表示区分度不高,检索性能下降,且训练过程不稳定。
核心思路:论文的核心思路是利用模型预测的方差(即不确定性)来动态调整对比损失的权重。当模型对某个样本的预测方差较大时,说明模型对该样本的对齐关系不够确定,此时降低该样本的损失权重,避免模型过度拟合噪声样本。反之,如果模型对某个样本的预测方差较小,则增加该样本的损失权重,促使模型更好地学习该样本的对齐关系。
技术框架:整体框架包含图像编码器、文本编码器以及对比学习损失函数。首先,图像和文本分别通过各自的编码器提取特征表示。然后,计算图像和文本特征之间的相似度,并基于此计算对比学习损失。关键在于,在计算损失时,引入一个方差感知的权重,该权重根据模型对齐预测的方差动态调整。
关键创新:最重要的创新点在于提出了方差感知的损失调度机制。与传统的固定权重对比学习或基于熵、相似度等启发式规则的自适应权重方法不同,该方法直接利用模型预测的统计变异性来指导损失权重的调整,更加直接地反映了模型学习的不确定性。
关键设计:关键设计包括:1)如何计算模型预测的方差。论文采用多次采样的方式,通过计算多次采样结果之间的方差来估计模型预测的不确定性。2)如何将方差信息融入到损失函数中。论文设计了一个权重函数,该函数将方差映射到损失权重,使得方差越大,权重越小,反之亦然。具体的权重函数形式未知,需要在论文中查找。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在Flickr8k数据集的低数据量子集上,提出的方差感知损失调度方法显著提高了图像-文本检索的准确率,优于固定权重基线和其他自适应权重策略(如基于熵和余弦相似度分布的方法)。此外,在噪声注入的压力测试中,该方法表现出更强的鲁棒性,在引入随机扰动时保持了更高的召回率,证明了其在应对噪声数据方面的优势。
🎯 应用场景
该研究成果可应用于图像-文本检索、视觉问答、图像描述生成等多种多模态任务中,尤其是在数据资源有限的场景下,例如医学图像报告检索、特定领域知识图谱构建等。通过提升低数据量下的多模态对齐效果,可以降低模型训练成本,加速模型部署,并拓展多模态技术在更多领域的应用。
📄 摘要(原文)
Training vision-language models for image-text alignment typically requires large datasets to achieve robust performance. In low-data scenarios, standard contrastive learning can struggle to align modalities effectively due to overfitting and unstable training dynamics. In this paper, we propose a variance-aware loss scheduling approach that dynamically adjusts the weighting of the contrastive loss based on the statistical variability (uncertainty) in the model's alignment predictions. Using a subset of the Flickr8k image-caption dataset to simulate limited data conditions, we demonstrate that our approach improves image-text retrieval accuracy compared to a fixed-weight baseline. We also compare against other adaptive weighting strategies (using output entropy and cosine similarity spread) and find that variance-aware scheduling provides the best overall trade-off. Qualitatively, our method yields more distinct multimodal embeddings as shown by t-SNE visualizations. Moreover, in a stress test with noise-injected captions and images, the variance-guided loss proves more robust, maintaining higher recall when random perturbations are introduced. These results highlight the benefit of adaptive loss weighting for multimodal alignment in low-data regimes.