LLaVE: Large Language and Vision Embedding Models with Hardness-Weighted Contrastive Learning
作者: Zhibin Lan, Liqiang Niu, Fandong Meng, Jie Zhou, Jinsong Su
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2025-03-04
备注: Preprint
💡 一句话要点
LLaVE:基于难度加权对比学习的大型语言-视觉嵌入模型,实现SOTA性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态嵌入 对比学习 难度加权 图像-文本检索 文本-视频检索
📋 核心要点
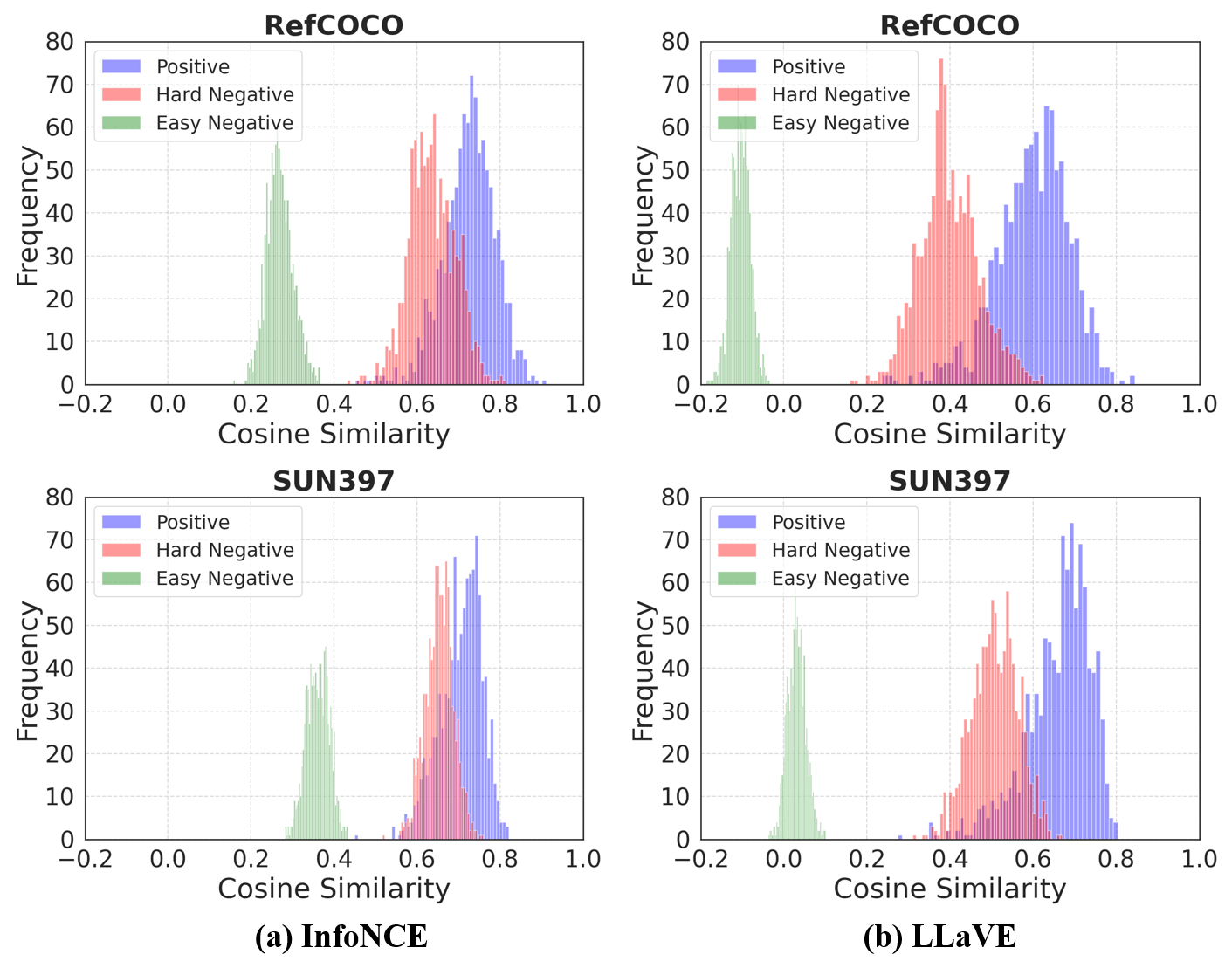
- 现有基于LMM的嵌入模型在训练时,正负样本对的相似度分布重叠严重,难以有效区分困难负样本。
- LLaVE框架基于负样本的区分难度,动态提升模型对负样本的表示学习能力,从而改善嵌入效果。
- 实验表明,LLaVE模型在MMEB基准上取得了SOTA性能,并且在文本-视频检索任务中展现出强大的泛化能力。
📝 摘要(中文)
通用的多模态嵌入模型在交错图像-文本检索、多模态RAG和多模态聚类等任务中起着关键作用。然而,我们的实验结果表明,现有的基于LMM的嵌入模型在使用标准InfoNCE损失训练时,正负样本对的相似度分布存在高度重叠,使得有效区分困难负样本变得具有挑战性。为了解决这个问题,我们提出了一个简单而有效的框架,该框架基于负样本的区分难度动态地改进嵌入模型对负样本的表示学习。在这个框架内,我们训练了一系列名为LLaVE的模型,并在涵盖4个元任务和36个数据集的MMEB基准上评估它们。实验结果表明,LLaVE建立了更强的基线,实现了最先进的(SOTA)性能,同时展示了强大的可扩展性和效率。具体来说,LLaVE-2B超过了之前的SOTA 7B模型,而LLaVE-7B实现了6.2个点的进一步性能提升。虽然LLaVE是在图像-文本数据上训练的,但它可以以零样本的方式推广到文本-视频检索任务,并取得强大的性能,展示了其转移到其他嵌入任务的巨大潜力。
🔬 方法详解
问题定义:论文旨在解决多模态嵌入模型在区分正负样本对时,由于相似度分布重叠而导致的困难负样本区分问题。现有方法,特别是基于InfoNCE损失训练的LMM模型,难以有效学习到区分性强的嵌入表示,限制了模型在多模态检索等任务中的性能。
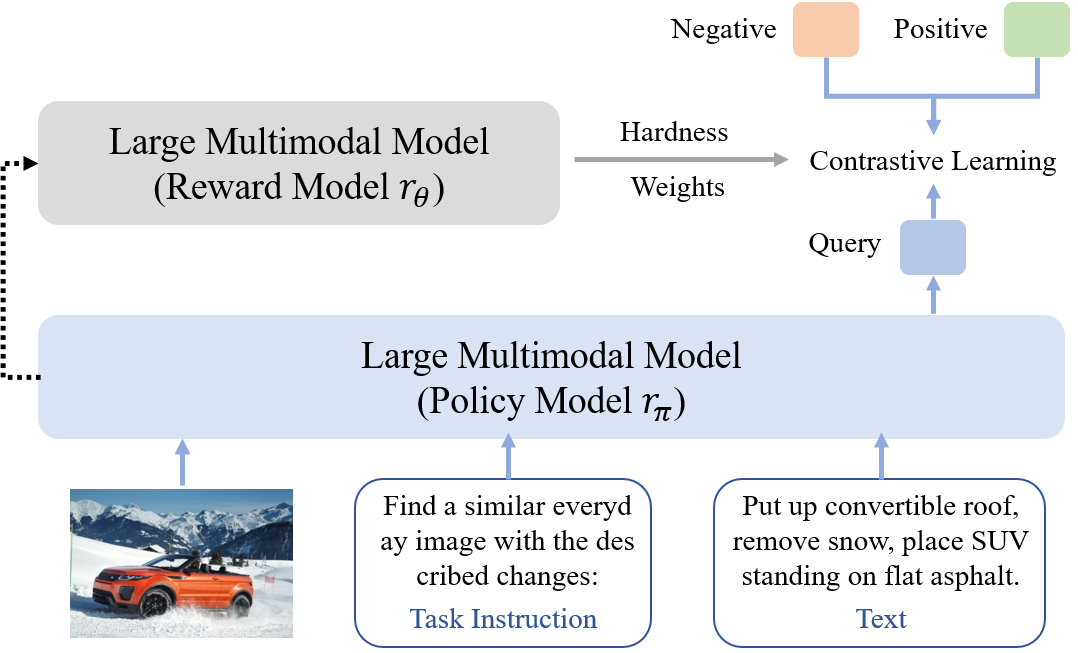
核心思路:论文的核心思路是根据负样本的区分难度,动态调整模型对负样本的学习权重。通过对困难负样本给予更高的关注,促使模型学习到更具区分性的嵌入表示,从而更好地分离正负样本对。这种方法旨在解决传统对比学习方法中,所有负样本同等对待的问题。
技术框架:LLaVE框架主要包含以下几个阶段:1) 使用大型语言模型(LLM)或视觉模型(Vision Model)提取图像和文本的初始特征表示。2) 构建图像-文本对,包括正样本对和负样本对。3) 计算正负样本对之间的相似度,并根据相似度确定负样本的区分难度。4) 使用难度加权的对比学习损失函数训练模型,优化嵌入表示。
关键创新:论文的关键创新在于提出了难度加权对比学习方法,该方法能够根据负样本的区分难度动态调整学习权重。与传统的对比学习方法相比,LLaVE更加关注困难负样本,从而能够学习到更具区分性的嵌入表示。这种方法能够有效缓解正负样本相似度分布重叠的问题。
关键设计:LLaVE框架的关键设计包括:1) 使用预训练的LLM和视觉模型作为特征提取器。2) 设计难度加权对比学习损失函数,例如,可以基于负样本的相似度排名或相似度值来确定权重。3) 探索不同的难度加权策略,例如,线性加权、指数加权等。4) 通过实验选择合适的超参数,例如,温度系数、权重调整系数等。
🖼️ 关键图片
📊 实验亮点
LLaVE模型在MMEB基准测试中取得了显著的性能提升。LLaVE-2B超越了之前的SOTA 7B模型,而LLaVE-7B进一步提升了6.2个百分点。此外,LLaVE模型在文本-视频检索任务中展现出强大的零样本泛化能力,证明了其在不同模态和任务之间的迁移潜力。这些实验结果表明,LLaVE模型具有强大的表示学习能力和泛化能力。
🎯 应用场景
LLaVE模型具有广泛的应用前景,包括但不限于:图像-文本检索、文本-视频检索、多模态RAG(检索增强生成)、多模态聚类、跨模态理解等。该模型可以用于构建更智能的搜索引擎、推荐系统和对话系统,提升用户体验和信息获取效率。此外,该模型还可以应用于机器人视觉、自动驾驶等领域,实现更精准的环境感知和决策。
📄 摘要(原文)
Universal multimodal embedding models play a critical role in tasks such as interleaved image-text retrieval, multimodal RAG, and multimodal clustering. However, our empirical results indicate that existing LMM-based embedding models trained with the standard InfoNCE loss exhibit a high degree of overlap in similarity distribution between positive and negative pairs, making it challenging to distinguish hard negative pairs effectively. To deal with this issue, we propose a simple yet effective framework that dynamically improves the embedding model's representation learning for negative pairs based on their discriminative difficulty. Within this framework, we train a series of models, named LLaVE, and evaluate them on the MMEB benchmark, which covers 4 meta-tasks and 36 datasets. Experimental results show that LLaVE establishes stronger baselines that achieve state-of-the-art (SOTA) performance while demonstrating strong scalability and efficiency. Specifically, LLaVE-2B surpasses the previous SOTA 7B models, while LLaVE-7B achieves a further performance improvement of 6.2 points. Although LLaVE is trained on image-text data, it can generalize to text-video retrieval tasks in a zero-shot manner and achieve strong performance, demonstrating its remarkable potential for transfer to other embedding tasks.