Monocular Person Localization under Camera Ego-motion
作者: Yu Zhan, Hanjing Ye, Hong Zhang
分类: cs.CV, cs.RO
发布日期: 2025-03-04 (更新: 2025-11-24)
备注: Accepted by IROS2025. Project page: https://medlartea.github.io/rpf-quadruped/
💡 一句话要点
提出基于单目相机运动的四点人体模型定位方法,提升人机交互中定位精度
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 单目视觉 人体定位 相机运动 姿态估计 人机交互
📋 核心要点
- 现有单目相机人体定位方法在相机剧烈运动时表现不佳,因为它们依赖于固定相机假设或缺乏相机运动数据训练。
- 论文提出一种基于四点人体模型的联合优化方法,同时估计相机姿态和人体3D位置,以应对相机运动。
- 实验结果表明,该方法在公共数据集和真实机器人场景中,均优于现有方法,并成功应用于四足机器人的人员跟随系统。
📝 摘要(中文)
本文研究了在相机自我运动情况下,如何利用单目相机进行人体定位,这对于人机交互至关重要。现有方法要么依赖于固定相机的几何假设,要么使用在包含少量相机自我运动的数据集上训练的位置回归模型。这些方法容易受到剧烈相机自我运动的影响,导致人体定位不准确。本文将人体定位视为姿态估计问题的一部分,通过使用四点模型表示人体,联合估计2D相机姿态和人体的3D位置,并通过优化实现。在公共数据集和真实机器人实验中的评估表明,该方法在人体定位精度方面优于基线方法。该方法进一步被实现到人员跟随系统中,并部署在敏捷四足机器人上。
🔬 方法详解
问题定义:论文旨在解决单目相机在自身运动时,难以精确定位人体的问题。现有方法主要存在两个痛点:一是依赖固定相机的几何假设,无法处理相机运动;二是依赖于缺乏相机运动数据训练的模型,泛化能力差。这些方法在相机发生剧烈运动时,定位精度会显著下降。
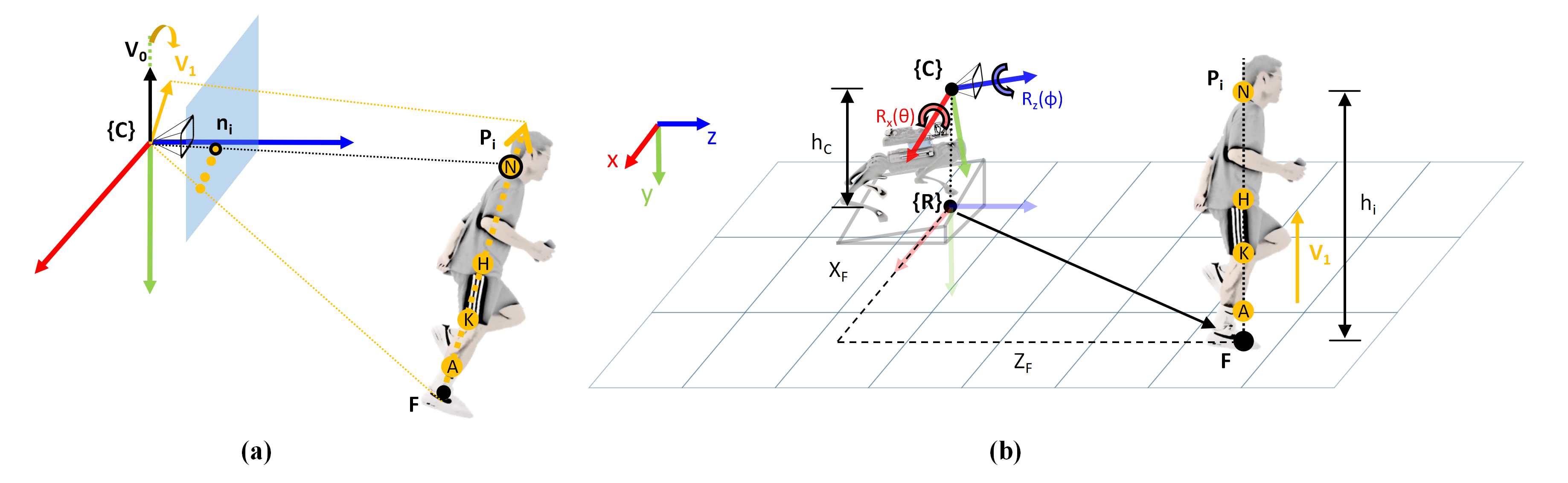
核心思路:论文的核心思路是将人体定位问题转化为一个姿态估计问题,并采用联合优化的方式解决。具体来说,使用一个四点模型来表示人体,同时估计相机的2D姿态和人体的3D位置。通过将相机姿态和人体位置的估计进行耦合,可以更好地利用图像信息,提高定位精度。
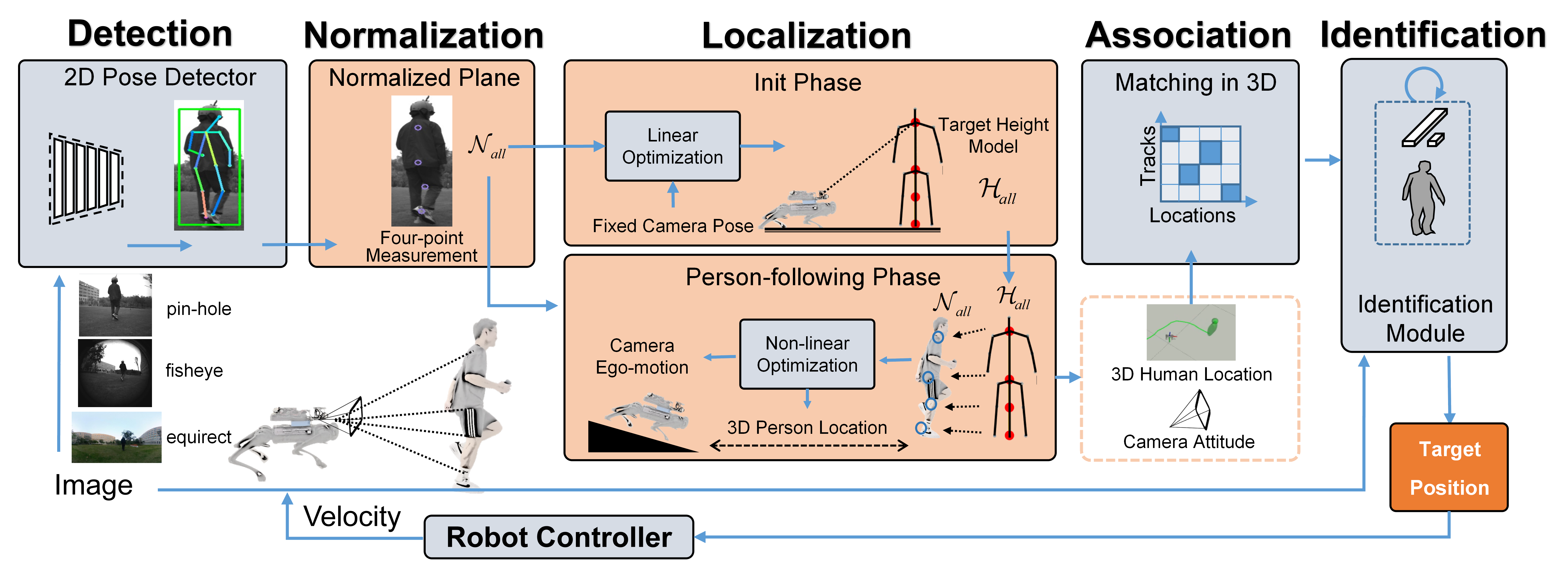
技术框架:该方法主要包含以下几个阶段:1) 使用单目相机获取图像;2) 检测图像中的人体,并提取四点模型;3) 建立一个优化问题,目标是最小化四点模型在图像上的投影误差,同时考虑相机姿态的先验信息;4) 使用优化算法(例如Levenberg-Marquardt算法)求解该优化问题,得到相机姿态和人体3D位置的估计。
关键创新:该方法最重要的技术创新点在于将相机姿态估计和人体定位进行联合优化。与传统方法分别进行相机姿态估计和人体定位不同,该方法将两者耦合在一起,可以互相约束,从而提高整体的定位精度。此外,使用四点模型表示人体,简化了姿态估计的复杂度,提高了计算效率。
关键设计:论文中一些关键的设计包括:1) 使用四点模型表示人体,这四个点可以是人体的关键部位,例如头顶、左右肩和脚底;2) 优化目标函数包含两部分:一是四点模型在图像上的投影误差,二是相机姿态的先验信息;3) 使用Levenberg-Marquardt算法求解优化问题,该算法具有较好的收敛性和鲁棒性。具体的参数设置和损失函数形式在论文中有详细描述,但具体数值未知。
🖼️ 关键图片

📊 实验亮点
论文在公共数据集和真实机器人实验中验证了该方法的有效性。实验结果表明,该方法在人体定位精度方面优于现有的基线方法。具体的数据和提升幅度在论文中给出,但此处无法提供具体数值。此外,该方法还被成功应用于四足机器人的人员跟随系统,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可广泛应用于人机交互、机器人导航、智能监控等领域。例如,在服务机器人中,可以利用该方法实现对人的精准定位和跟踪,从而实现更自然、更流畅的人机交互。在智能监控领域,可以用于检测和跟踪人群中的特定个体,提高监控效率和安全性。未来,该方法可以进一步扩展到多人定位、复杂场景定位等问题,具有广阔的应用前景。
📄 摘要(原文)
Localizing a person from a moving monocular camera is critical for Human-Robot Interaction (HRI). To estimate the 3D human position from a 2D image, existing methods either depend on the geometric assumption of a fixed camera or use a position regression model trained on datasets containing little camera ego-motion. These methods are vulnerable to severe camera ego-motion, resulting in inaccurate person localization. We consider person localization as a part of a pose estimation problem. By representing a human with a four-point model, our method jointly estimates the 2D camera attitude and the person's 3D location through optimization. Evaluations on both public datasets and real robot experiments demonstrate our method outperforms baselines in person localization accuracy. Our method is further implemented into a person-following system and deployed on an agile quadruped robot.