MM-OR: A Large Multimodal Operating Room Dataset for Semantic Understanding of High-Intensity Surgical Environments
作者: Ege Özsoy, Chantal Pellegrini, Tobias Czempiel, Felix Tristram, Kun Yuan, David Bani-Harouni, Ulrich Eck, Benjamin Busam, Matthias Keicher, Nassir Navab
分类: cs.CV
发布日期: 2025-03-04
🔗 代码/项目: GITHUB
💡 一句话要点
提出MM-OR手术室多模态数据集与MM2SG模型,用于提升高强度手术环境的语义理解。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手术室场景理解 多模态数据集 场景图生成 视觉-语言模型 医疗人工智能
📋 核心要点
- 现有手术室数据集在规模、真实性和多模态信息融合方面存在不足,难以有效支持手术环境的全面理解和建模。
- 论文提出MM-OR数据集和MM2SG模型,旨在通过大规模多模态数据和视觉-语言模型,提升手术室场景的语义理解能力。
- 实验证明,MM2SG模型能够有效利用MM-OR数据集中的多模态信息,为手术室场景理解建立新的基准。
📝 摘要(中文)
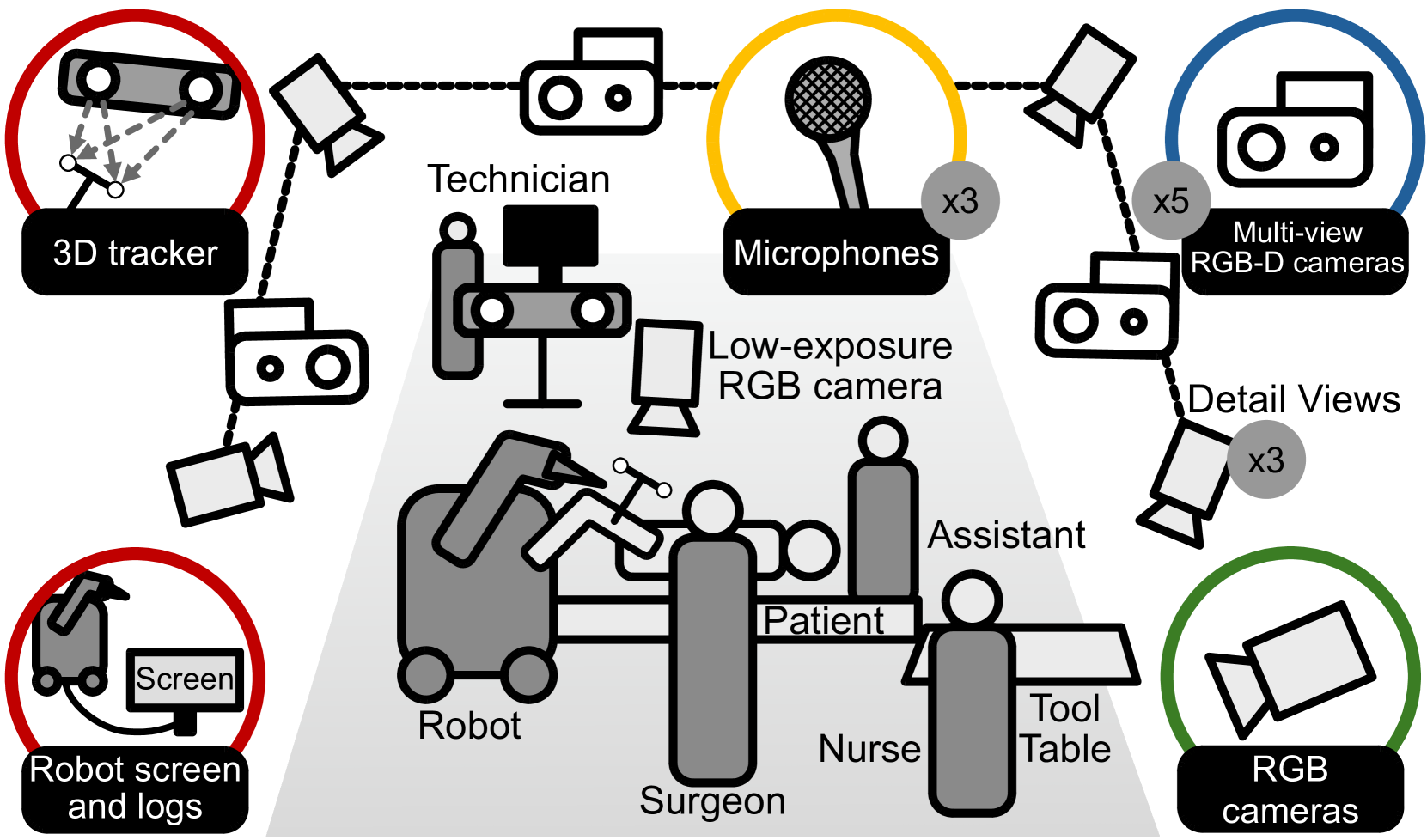
手术室(OR)是复杂且高风险的环境,需要精确理解医务人员、工具和设备之间的交互,以增强手术辅助、态势感知和患者安全。现有数据集在规模、真实性和多模态信息捕获方面存在不足,限制了OR建模的进展。为此,我们引入了MM-OR,一个真实且大规模的多模态时空OR数据集,也是首个支持多模态场景图生成的数据集。MM-OR捕获了全面的OR场景,包含RGB-D数据、细节视图、音频、语音转录、机器人日志和跟踪数据,并标注了全景分割、语义场景图和下游任务标签。此外,我们提出了MM2SG,首个用于场景图生成的多模态大型视觉-语言模型,并通过大量实验证明了其有效利用多模态输入的能力。MM-OR和MM2SG共同为整体OR理解建立了一个新的基准,并为复杂、高风险环境中的多模态场景分析开辟了道路。我们的代码和数据可在https://github.com/egeozsoy/MM-OR获取。
🔬 方法详解
问题定义:现有手术室数据集规模有限,缺乏真实感,并且未能充分捕捉手术室环境的多模态特性(如视觉、听觉、机器人数据等)。这限制了对手术室场景的全面理解,阻碍了手术辅助、态势感知和患者安全等领域的发展。现有方法难以有效利用这些多模态信息进行场景理解和推理。
核心思路:论文的核心思路是构建一个大规模、真实且多模态的手术室数据集MM-OR,并设计一个能够有效利用多模态信息的视觉-语言模型MM2SG。通过提供丰富的数据和强大的模型,促进手术室场景的语义理解和推理。
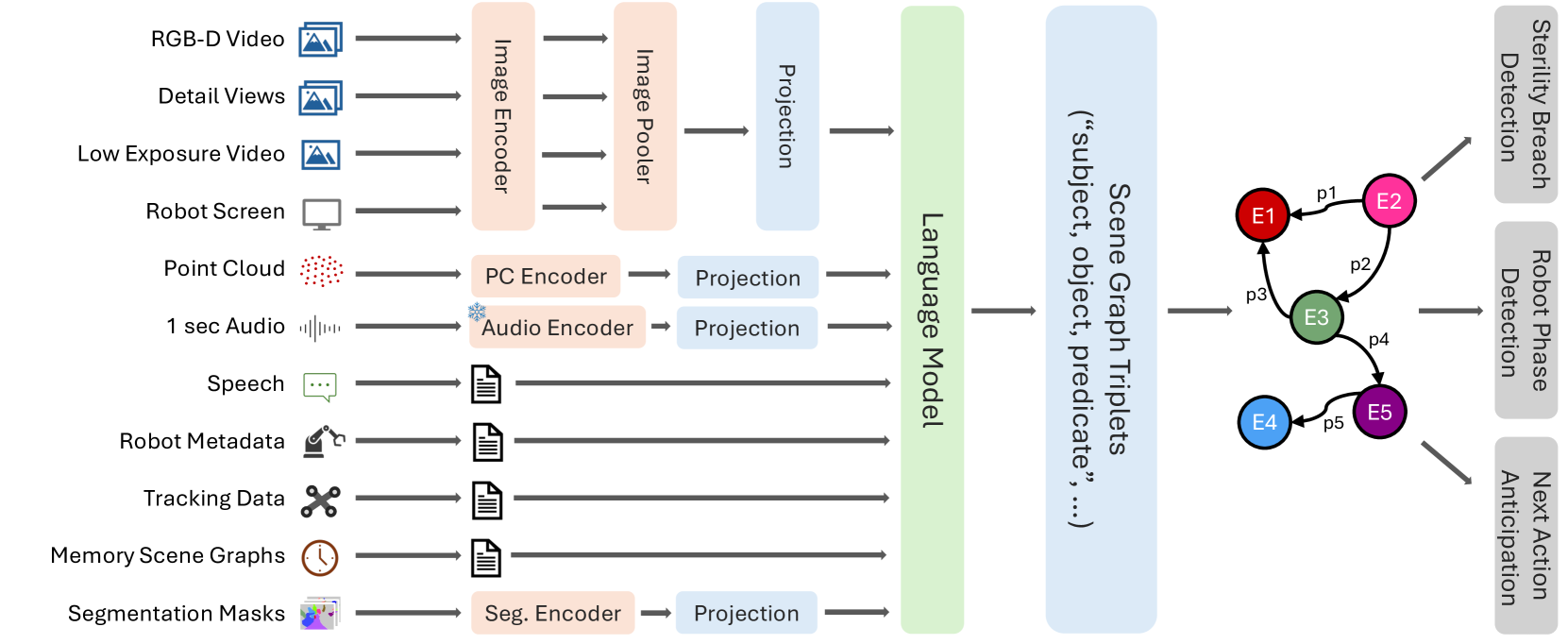
技术框架:整体框架包含两个主要部分:MM-OR数据集的构建和MM2SG模型的训练与评估。MM-OR数据集包含RGB-D数据、细节视图、音频、语音转录、机器人日志和跟踪数据,并进行了全景分割、语义场景图和下游任务标签的标注。MM2SG模型是一个基于Transformer的视觉-语言模型,旨在从多模态输入中生成场景图。
关键创新:论文的关键创新在于:1) 提出了首个大规模多模态手术室数据集MM-OR,为相关研究提供了丰富的数据资源。2) 提出了首个用于场景图生成的多模态大型视觉-语言模型MM2SG,能够有效融合多种模态的信息。3) 将多模态场景图生成任务引入手术室环境,为手术室的智能化应用提供了新的思路。
关键设计:MM-OR数据集的设计考虑了手术室环境的复杂性和多样性,包含了多种模态的数据,并进行了详细的标注。MM2SG模型采用了Transformer架构,并针对多模态输入进行了优化,具体的技术细节(如损失函数、网络结构等)在论文中进行了详细描述(具体细节未知)。
🖼️ 关键图片

📊 实验亮点
论文提出了MM2SG模型,并在MM-OR数据集上进行了实验验证。实验结果表明,MM2SG模型能够有效利用多模态输入,生成准确的场景图,为手术室场景理解提供了新的方法。具体的性能数据和对比基线在论文中进行了详细描述(具体数值未知),但整体而言,该模型在多模态场景图生成任务上取得了显著的成果。
🎯 应用场景
该研究成果可应用于手术室的智能化改造,例如:开发智能手术辅助系统,通过理解手术场景,为医生提供实时的建议和指导;提升手术室的态势感知能力,及时发现潜在的风险;提高患者安全性,减少医疗事故的发生。此外,该研究也可推广到其他复杂、高风险的环境中,如灾难救援、工业生产等。
📄 摘要(原文)
Operating rooms (ORs) are complex, high-stakes environments requiring precise understanding of interactions among medical staff, tools, and equipment for enhancing surgical assistance, situational awareness, and patient safety. Current datasets fall short in scale, realism and do not capture the multimodal nature of OR scenes, limiting progress in OR modeling. To this end, we introduce MM-OR, a realistic and large-scale multimodal spatiotemporal OR dataset, and the first dataset to enable multimodal scene graph generation. MM-OR captures comprehensive OR scenes containing RGB-D data, detail views, audio, speech transcripts, robotic logs, and tracking data and is annotated with panoptic segmentations, semantic scene graphs, and downstream task labels. Further, we propose MM2SG, the first multimodal large vision-language model for scene graph generation, and through extensive experiments, demonstrate its ability to effectively leverage multimodal inputs. Together, MM-OR and MM2SG establish a new benchmark for holistic OR understanding, and open the path towards multimodal scene analysis in complex, high-stakes environments. Our code, and data is available at https://github.com/egeozsoy/MM-OR.