I see what you mean: Co-Speech Gestures for Reference Resolution in Multimodal Dialogue
作者: Esam Ghaleb, Bulat Khaertdinov, Aslı Özyürek, Raquel Fernández
分类: cs.CV, cs.CL, cs.MM
发布日期: 2025-02-27 (更新: 2025-06-29)
备注: Accepted to Findings of ACL 2025
💡 一句话要点
提出基于自监督预训练的Co-Speech手势嵌入方法,用于多模态对话中的指代消解。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Co-Speech手势 指代消解 多模态对话 自监督学习 手势嵌入 人机交互
📋 核心要点
- 现有计算模型在理解Co-Speech手势如何指代对象方面存在不足,限制了人机交互的自然性。
- 提出一种自监督预训练方法,学习将身体动作与口语关联的手势表征,从而提升指代消解能力。
- 实验表明,该方法学习到的手势嵌入与专家标注对齐,且在指代消解任务中表现出显著的预测能力。
📝 摘要(中文)
在面对面交流中,我们使用包括语音和手势在内的多种模态来传递信息和解决对象指代。然而,从计算角度来看,具象型Co-Speech手势如何指代对象的研究仍然不足。为了弥补这一差距,我们引入了一个以具象型手势为中心的多模态指代消解任务,同时应对学习鲁棒手势嵌入的挑战。我们提出了一种自监督预训练方法,用于手势表征学习,该方法将身体动作与口语联系起来。实验表明,学习到的嵌入与专家标注对齐,并具有显著的预测能力。此外,当(1)使用多模态手势表征时(即使在推理时语音不可用),以及(2)利用对话历史时,指代消解的准确性进一步提高。总的来说,我们的研究结果突出了手势和语音在指代消解中的互补作用,为更自然的人机交互模型提供了一个方向。
🔬 方法详解
问题定义:论文旨在解决多模态对话中,如何利用Co-Speech手势进行准确的对象指代消解问题。现有方法主要依赖语音信息,忽略了手势的具象表达能力,导致在语音信息不足或存在歧义时,指代消解效果不佳。此外,如何学习到鲁棒且具有语义信息的手势嵌入也是一个挑战。
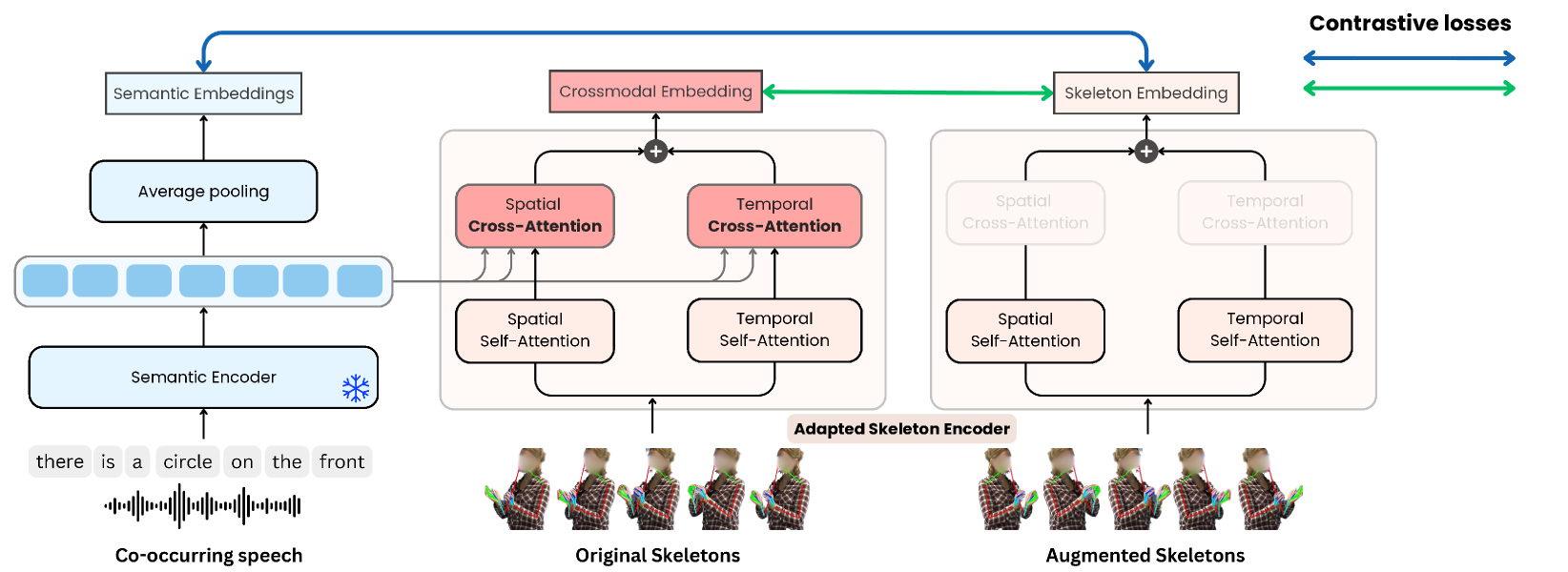
核心思路:论文的核心思路是通过自监督学习,将手势的视觉信息与对应的口语信息对齐,从而学习到能够表达对象指代关系的手势嵌入。这种方法利用了Co-Speech手势与口语之间的自然关联,无需人工标注即可学习到有用的手势表征。
技术框架:整体框架包含两个主要阶段:1) 自监督预训练阶段:利用大量的Co-Speech手势和对应的语音数据,通过对比学习等方法,训练手势嵌入模型,使其能够区分不同的手势表达。2) 指代消解阶段:将预训练好的手势嵌入模型应用于指代消解任务,结合语音信息和对话历史,预测手势所指代的对象。
关键创新:论文的关键创新在于提出了基于自监督预训练的手势嵌入学习方法。与传统的监督学习方法相比,该方法无需人工标注,可以利用大量的无标注数据进行训练,从而学习到更鲁棒和泛化的手势表征。此外,该方法还考虑了Co-Speech手势与口语之间的关联,使得学习到的手势嵌入能够更好地表达对象指代关系。
关键设计:在自监督预训练阶段,论文采用了对比学习的框架,设计了一个损失函数,使得相似的手势表达在嵌入空间中更加接近,而不相似的手势表达则更加远离。具体的网络结构未知,但可以推测使用了Transformer或类似的序列模型来处理手势和语音数据。在指代消解阶段,论文将手势嵌入、语音信息和对话历史作为输入,使用一个分类器来预测手势所指代的对象。具体的分类器结构未知。
🖼️ 关键图片

📊 实验亮点
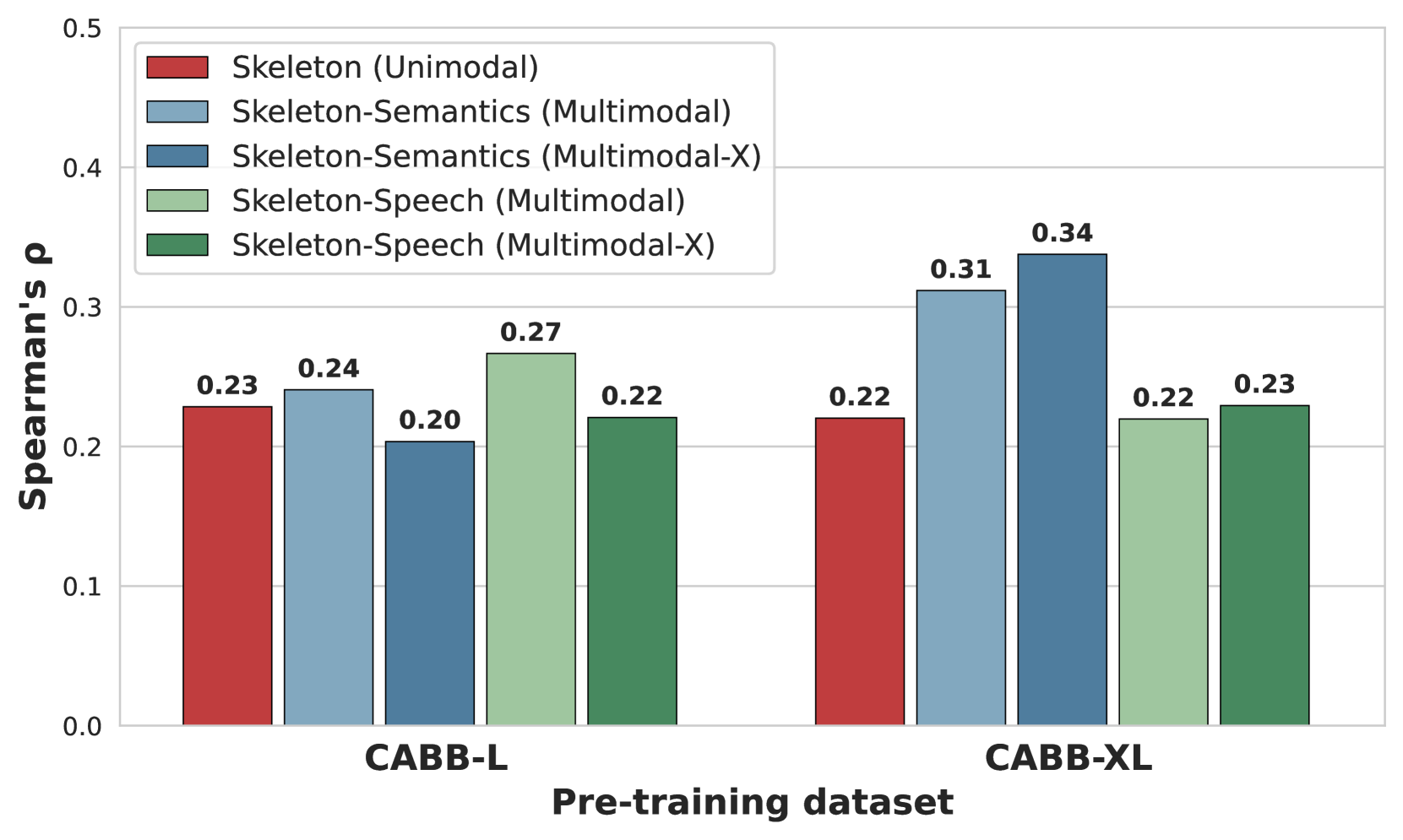
实验结果表明,该方法学习到的手势嵌入与专家标注对齐,并且在指代消解任务中取得了显著的提升。即使在语音信息不可用时,仅使用手势信息也能达到较高的指代消解准确率。此外,利用对话历史信息可以进一步提高指代消解的性能。具体提升幅度未知。
🎯 应用场景
该研究成果可应用于人机交互、虚拟助手、机器人导航等领域。通过理解Co-Speech手势,机器可以更准确地理解人类的意图,从而实现更自然、更高效的人机交互。例如,在智能家居场景中,用户可以通过手势控制家电设备,而无需使用语音或触摸屏。
📄 摘要(原文)
In face-to-face interaction, we use multiple modalities, including speech and gestures, to communicate information and resolve references to objects. However, how representational co-speech gestures refer to objects remains understudied from a computational perspective. In this work, we address this gap by introducing a multimodal reference resolution task centred on representational gestures, while simultaneously tackling the challenge of learning robust gesture embeddings. We propose a self-supervised pre-training approach to gesture representation learning that grounds body movements in spoken language. Our experiments show that the learned embeddings align with expert annotations and have significant predictive power. Moreover, reference resolution accuracy further improves when (1) using multimodal gesture representations, even when speech is unavailable at inference time, and (2) leveraging dialogue history. Overall, our findings highlight the complementary roles of gesture and speech in reference resolution, offering a step towards more naturalistic models of human-machine interaction.