SAC-ViT: Semantic-Aware Clustering Vision Transformer with Early Exit
作者: Youbing Hu, Yun Cheng, Anqi Lu, Dawei Wei, Zhijun Li
分类: cs.CV, cs.AI
发布日期: 2025-02-27
💡 一句话要点
提出SAC-ViT,通过语义感知聚类和早退机制提升Vision Transformer的计算效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Vision Transformer 计算效率 早退机制 语义感知聚类 图像识别 轻量级模型 模型加速
📋 核心要点
- Vision Transformer虽然擅长全局建模,但其注意力机制的平方计算复杂度使其难以在资源受限的设备上部署。
- SAC-ViT通过早退机制过滤掉不重要的区域,并利用语义感知聚类减少冗余计算,从而提升计算效率。
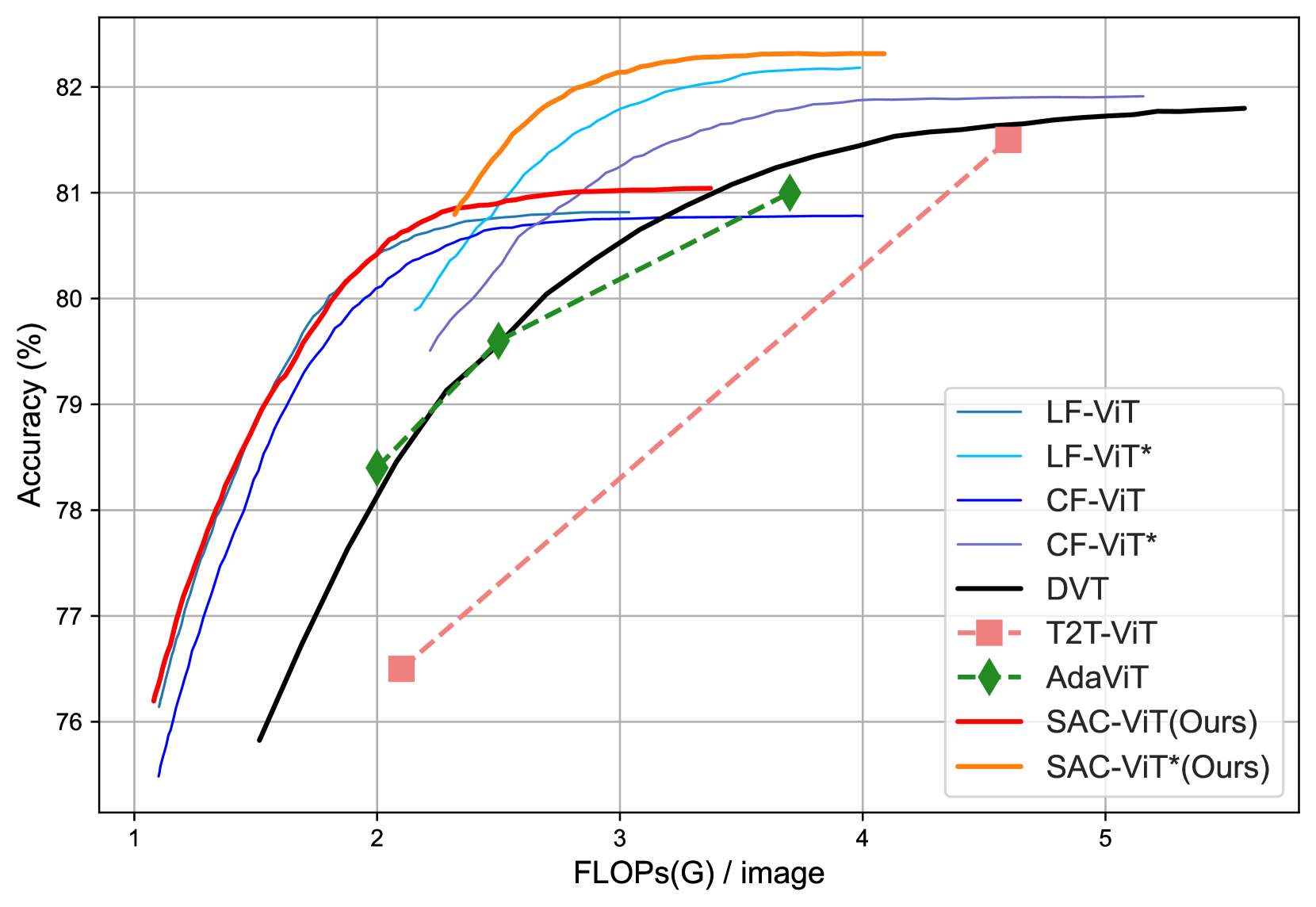
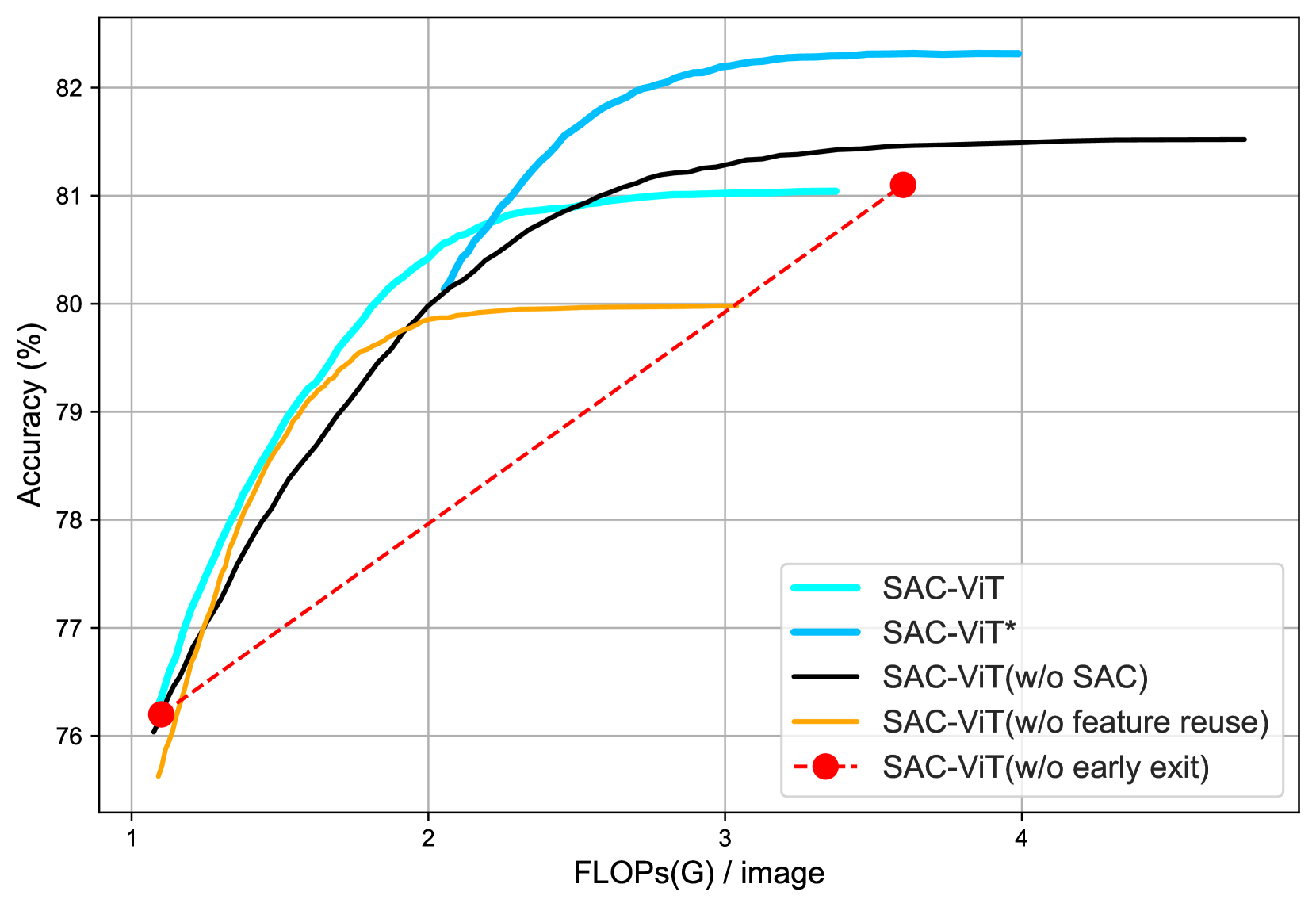
- 实验结果表明,SAC-ViT在不损失性能的前提下,显著降低了计算量,并提高了吞吐量。
📝 摘要(中文)
本文提出了一种语义感知聚类Vision Transformer (SAC-ViT),这是一种非迭代方法,旨在提高ViT的计算效率。SAC-ViT分两个阶段运行:早退 (EE) 和语义感知聚类 (SAC)。在EE阶段,处理下采样输入图像以提取全局语义信息并生成初始推理结果。如果这些结果不满足EE终止标准,则将信息聚类为目标和非目标token。在SAC阶段,目标token被映射回原始图像,裁剪并嵌入。然后将这些目标token与EE阶段重用的非目标token组合,并在每个集群内应用注意力机制。这种两阶段设计通过端到端优化,减少了空间冗余并提高了计算效率,从而显著提升了ViT的整体性能。大量实验证明了SAC-ViT的有效性,在不影响性能的情况下,减少了DeiT 62%的FLOPs,并实现了1.98倍的吞吐量。
🔬 方法详解
问题定义:Vision Transformer (ViT) 在图像识别领域表现出色,但其全局注意力机制导致计算复杂度高,尤其是在高分辨率图像上。这限制了ViT在资源受限设备上的应用。现有方法通常采用迭代的方式来降低计算复杂度,但效率提升有限。
核心思路:SAC-ViT的核心思路是通过非迭代的方式,首先利用早退机制快速过滤掉不重要的图像区域,然后对剩余区域进行语义感知聚类,从而减少需要进行全局注意力计算的token数量,降低计算冗余。
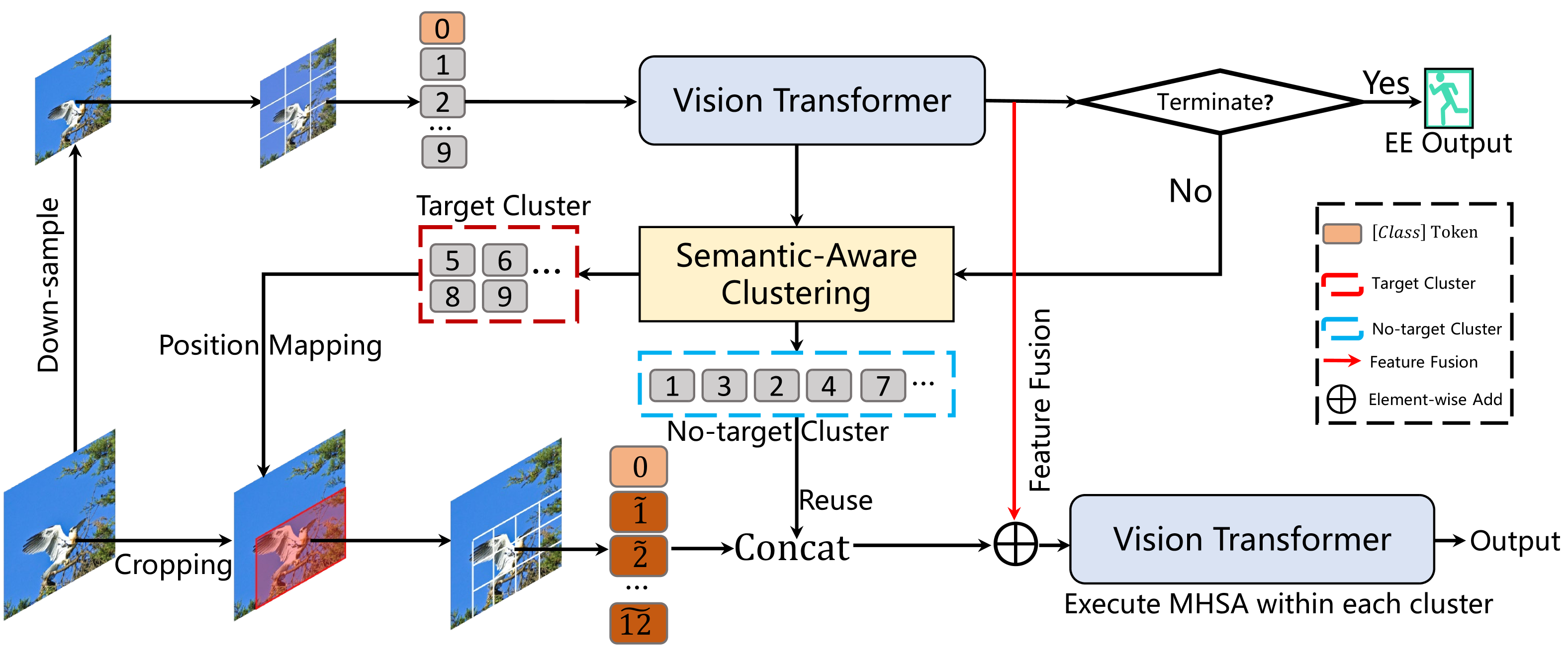
技术框架:SAC-ViT包含两个主要阶段:早退 (Early Exit, EE) 阶段和语义感知聚类 (Semantic-Aware Clustering, SAC) 阶段。在EE阶段,输入图像被下采样并处理,生成初步的推理结果。如果结果满足预设的置信度阈值,则提前终止推理。否则,将token聚类为目标和非目标token。在SAC阶段,目标token被映射回原始图像,裁剪并嵌入,然后与EE阶段的非目标token合并,并在每个聚类内部应用注意力机制。
关键创新:SAC-ViT的关键创新在于其非迭代的两阶段设计。早退机制能够快速过滤掉不重要的区域,减少后续计算量。语义感知聚类能够将相关的token聚集在一起,从而在局部进行注意力计算,避免全局注意力带来的高计算复杂度。与现有方法相比,SAC-ViT无需迭代优化,效率更高。
关键设计:SAC-ViT的关键设计包括:1) 早退机制的置信度阈值设置,需要平衡推理速度和准确率;2) 语义感知聚类的聚类算法选择,需要保证聚类效果和计算效率;3) 目标token映射回原始图像时的裁剪策略,需要保证包含足够的目标信息;4) 损失函数的设计,需要同时优化分类准确率和计算效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SAC-ViT在ImageNet数据集上,与DeiT相比,减少了62%的FLOPs,同时实现了1.98倍的吞吐量,而性能没有明显下降。这表明SAC-ViT在提高计算效率方面具有显著优势。此外,SAC-ViT的性能优于其他一些轻量级ViT模型,证明了其有效性。
🎯 应用场景
SAC-ViT适用于各种需要高效图像识别的场景,例如移动设备上的图像分类、目标检测和图像分割。它还可以应用于自动驾驶、机器人视觉等领域,在这些领域中,计算资源通常受到限制,需要快速准确的图像处理能力。SAC-ViT的未来发展方向包括进一步优化聚类算法和早退机制,以实现更高的计算效率和更好的性能。
📄 摘要(原文)
The Vision Transformer (ViT) excels in global modeling but faces deployment challenges on resource-constrained devices due to the quadratic computational complexity of its attention mechanism. To address this, we propose the Semantic-Aware Clustering Vision Transformer (SAC-ViT), a non-iterative approach to enhance ViT's computational efficiency. SAC-ViT operates in two stages: Early Exit (EE) and Semantic-Aware Clustering (SAC). In the EE stage, downsampled input images are processed to extract global semantic information and generate initial inference results. If these results do not meet the EE termination criteria, the information is clustered into target and non-target tokens. In the SAC stage, target tokens are mapped back to the original image, cropped, and embedded. These target tokens are then combined with reused non-target tokens from the EE stage, and the attention mechanism is applied within each cluster. This two-stage design, with end-to-end optimization, reduces spatial redundancy and enhances computational efficiency, significantly boosting overall ViT performance. Extensive experiments demonstrate the efficacy of SAC-ViT, reducing 62% of the FLOPs of DeiT and achieving 1.98 times throughput without compromising performance.