UniTok: A Unified Tokenizer for Visual Generation and Understanding
作者: Chuofan Ma, Yi Jiang, Junfeng Wu, Jihan Yang, Xin Yu, Zehuan Yuan, Bingyue Peng, Xiaojuan Qi
分类: cs.CV, cs.AI
发布日期: 2025-02-27 (更新: 2025-10-24)
备注: NeurIPS 2025 Spotlight
🔗 代码/项目: GITHUB
💡 一句话要点
提出UniTok,通过多码本量化机制,统一视觉生成与理解的Tokenizer。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 视觉生成 视觉理解 Tokenizer 多码本量化 VQVAE CLIP 多模态学习 图像表示
📋 核心要点
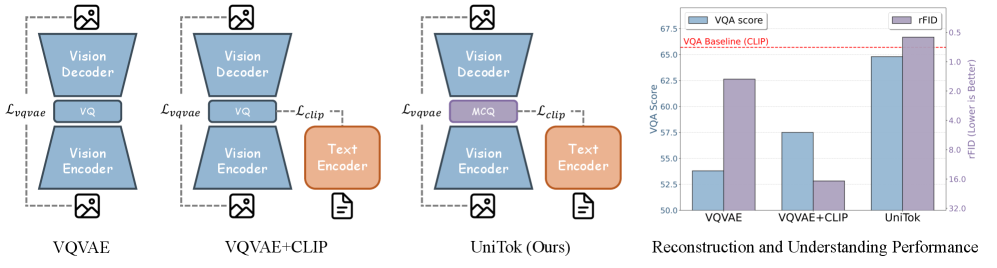
- 现有视觉生成和理解模型使用不同的tokenizer,阻碍了统一框架的构建,直接组合VQVAE和CLIP的训练目标会导致损失冲突。
- UniTok通过多码本量化机制,有效扩大词汇量和瓶颈维度,从而提升离散token空间的表示能力,解决损失冲突问题。
- 实验表明,UniTok在ImageNet上取得了0.38 rFID和78.6%零样本准确率,并能无缝集成到MLLM中,提升视觉生成能力。
📝 摘要(中文)
视觉生成和理解模型通常依赖于不同的tokenizer来处理图像,这给在单个框架内统一它们带来了关键挑战。最近的研究试图通过连接VQVAE(用于自回归生成)和CLIP(用于理解)的训练来构建统一的tokenizer。然而,直接组合这些训练目标已被观察到会导致严重的损失冲突。本文表明,重建和语义监督本质上并不冲突。相反,根本瓶颈在于离散token空间的有限表示能力。基于这些见解,我们引入了UniTok,一种统一的tokenizer,其特点是新颖的多码本量化机制,可以有效地扩大词汇量大小和瓶颈维度。在最终性能方面,UniTok在ImageNet上创造了0.38 rFID和78.6%零样本准确率的新纪录。此外,UniTok可以无缝集成到MLLM中,以解锁原生视觉生成能力,而不会影响理解性能。此外,我们表明UniTok有利于无cfg生成,在ImageNet 256×256基准测试中将gFID从14.6降低到2.5。
🔬 方法详解
问题定义:现有视觉生成和理解模型通常使用不同的tokenizer,导致无法在一个统一的框架中同时进行视觉生成和理解任务。直接将VQVAE(用于生成)和CLIP(用于理解)的训练目标结合,会产生严重的损失冲突,影响模型性能。现有tokenizer的表示能力不足是造成损失冲突的根本原因。
核心思路:论文的核心思路是通过提升离散token空间的表示能力来解决损失冲突问题。具体而言,通过设计一种多码本量化机制,扩大词汇量大小和瓶颈维度,从而使tokenizer能够更好地捕捉图像的细节和语义信息,从而缓解生成和理解任务之间的冲突。
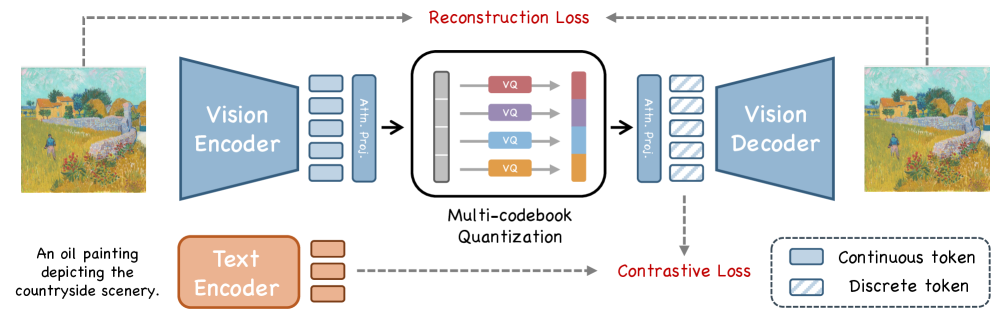
技术框架:UniTok的整体框架包括图像编码器、多码本量化器和图像解码器。图像编码器将输入图像转换为高维特征表示。多码本量化器将高维特征量化为多个离散的token,每个token来自不同的码本。图像解码器则根据这些token重建图像。在训练过程中,UniTok同时优化重建损失和语义对齐损失,以确保生成的token既能保留图像的细节信息,又能与图像的语义信息对齐。
关键创新:UniTok的关键创新在于其多码本量化机制。与传统的单码本量化方法相比,多码本量化可以显著扩大词汇量大小,从而提升token的表示能力。此外,UniTok还通过优化码本之间的相关性,进一步提升了token的表达能力。这种多码本量化机制是UniTok能够同时实现高质量图像生成和准确图像理解的关键。
关键设计:UniTok的关键设计包括码本的数量、每个码本的大小、以及码本之间的相关性约束。论文通过实验验证了不同参数设置对模型性能的影响,并选择了最优的参数组合。此外,论文还设计了一种新的损失函数,用于优化码本之间的相关性,从而进一步提升了token的表达能力。具体来说,使用了对比学习损失来对齐不同码本之间的特征表示,鼓励它们学习互补的信息。
🖼️ 关键图片

📊 实验亮点
UniTok在ImageNet数据集上取得了显著的性能提升,rFID指标达到了0.38,零样本分类准确率达到了78.6%,均超过了现有方法。此外,UniTok在cfg-free生成方面也表现出色,在ImageNet 256×256基准测试中将gFID从14.6降低到2.5。这些实验结果表明,UniTok能够有效地统一视觉生成和理解任务,并提升模型的整体性能。
🎯 应用场景
UniTok具有广泛的应用前景,例如可以应用于多模态大模型,使其具备原生的视觉生成能力,从而实现更强大的视觉-语言交互。此外,UniTok还可以应用于图像编辑、图像修复等任务,为这些任务提供更强大的图像表示能力。该研究对于推动通用人工智能的发展具有重要意义。
📄 摘要(原文)
Visual generative and understanding models typically rely on distinct tokenizers to process images, presenting a key challenge for unifying them within a single framework. Recent studies attempt to address this by connecting the training of VQVAE (for autoregressive generation) and CLIP (for understanding) to build a unified tokenizer. However, directly combining these training objectives has been observed to cause severe loss conflicts. In this paper, we show that reconstruction and semantic supervision do not inherently conflict. Instead, the underlying bottleneck stems from limited representational capacity of discrete token space. Building on these insights, we introduce UniTok, a unified tokenizer featuring a novel multi-codebook quantization mechanism that effectively scales up the vocabulary size and bottleneck dimension. In terms of final performance, UniTok sets a new record of 0.38 rFID and 78.6% zero-shot accuracy on ImageNet. Besides, UniTok can be seamlessly integrated into MLLMs to unlock native visual generation capability, without compromising the understanding performance. Additionally, we show that UniTok favors cfg-free generation, reducing gFID from 14.6 to 2.5 on ImageNet 256$\times$256 benchmark. GitHub: https://github.com/FoundationVision/UniTok.