Joint Fusion and Encoding: Advancing Multimodal Retrieval from the Ground Up
作者: Lang Huang, Qiyu Wu, Zhongtao Miao, Toshihiko Yamasaki
分类: cs.CV
发布日期: 2025-02-27
💡 一句话要点
提出联合融合编码框架,从底层增强多模态检索性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 跨模态融合 联合融合编码 单塔架构 MLLM 指令调优 早期融合
📋 核心要点
- 现有双塔架构在多模态检索中忽略了视觉和文本之间的细粒度交互,限制了对复杂查询的理解。
- 提出联合融合编码框架,从底层融合视觉和文本信息,实现早期跨模态交互,增强上下文理解。
- 通过两阶段训练,将MLLM适配为检索器,在多模态检索任务上超越传统方法,尤其在需要模态融合的任务中。
📝 摘要(中文)
信息检索在当今互联网应用中至关重要,但传统语义匹配技术在捕捉复杂查询所需的细粒度跨模态交互方面存在不足。虽然晚期融合的双塔架构试图通过独立编码视觉和文本数据,然后在高层合并它们来弥补这一差距,但它们经常忽略了全面理解所必需的微妙相互作用。本文严格评估了这些局限性,并提出了一个统一的检索框架,该框架从底层融合视觉和文本线索,从而实现早期跨模态交互以增强上下文解释。通过一个两阶段的训练过程——包括后训练适应和指令调优——我们使用一个简单的单塔架构将MLLM适配为检索器。我们的方法在各种检索场景中优于传统方法,尤其是在处理复杂的多模态输入时。值得注意的是,与不需要模态融合的任务相比,联合融合编码器在需要模态融合的任务上产生了更大的改进,突出了早期集成策略的变革潜力,并为上下文感知和有效的信息检索指明了一个有希望的方向。
🔬 方法详解
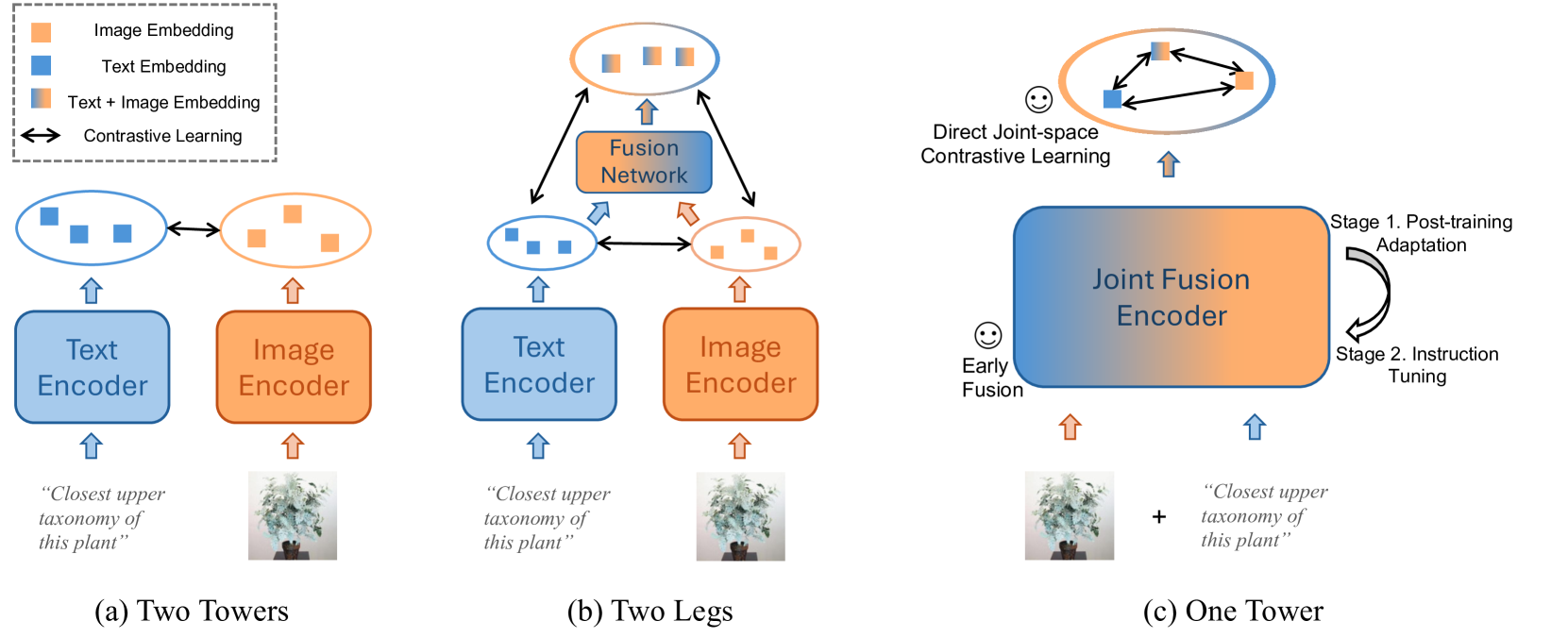
问题定义:现有基于双塔结构的跨模态检索方法,通常采用晚期融合策略,即先独立编码视觉和文本信息,然后在高层进行融合。这种方式忽略了视觉和文本在底层可能存在的细粒度交互,导致模型难以理解复杂的跨模态查询,尤其是在需要深度融合的任务中表现不佳。
核心思路:本文的核心思路是从底层开始融合视觉和文本信息,实现早期跨模态交互。通过联合处理视觉和文本输入,模型可以更好地理解上下文信息,捕捉模态间的细微关联,从而提升检索性能。作者认为,早期融合能够使模型更全面地理解多模态输入,从而更好地应对复杂查询。
技术框架:该框架采用单塔架构,将视觉和文本信息联合输入到一个多模态语言模型(MLLM)中。整个训练过程分为两个阶段:首先是后训练适应(Post-Training Adaptation),旨在使MLLM适应检索任务;然后是指令调优(Instruction Tuning),通过指令引导模型学习如何进行有效的跨模态检索。这种两阶段训练策略能够充分利用MLLM的预训练知识,并使其更好地适应特定的检索场景。
关键创新:该论文的关键创新在于提出了联合融合编码的思想,并将其应用于多模态检索任务中。与传统的双塔结构和晚期融合策略不同,该方法从底层开始融合视觉和文本信息,实现了早期跨模态交互。这种早期融合的方式能够使模型更好地理解上下文信息,捕捉模态间的细微关联,从而提升检索性能。
关键设计:该框架使用MLLM作为基础模型,并采用两阶段训练策略。在后训练适应阶段,作者可能使用了对比学习或掩码语言模型等方法,使MLLM适应检索任务。在指令调优阶段,作者设计了一系列指令,引导模型学习如何进行有效的跨模态检索。具体的损失函数和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片
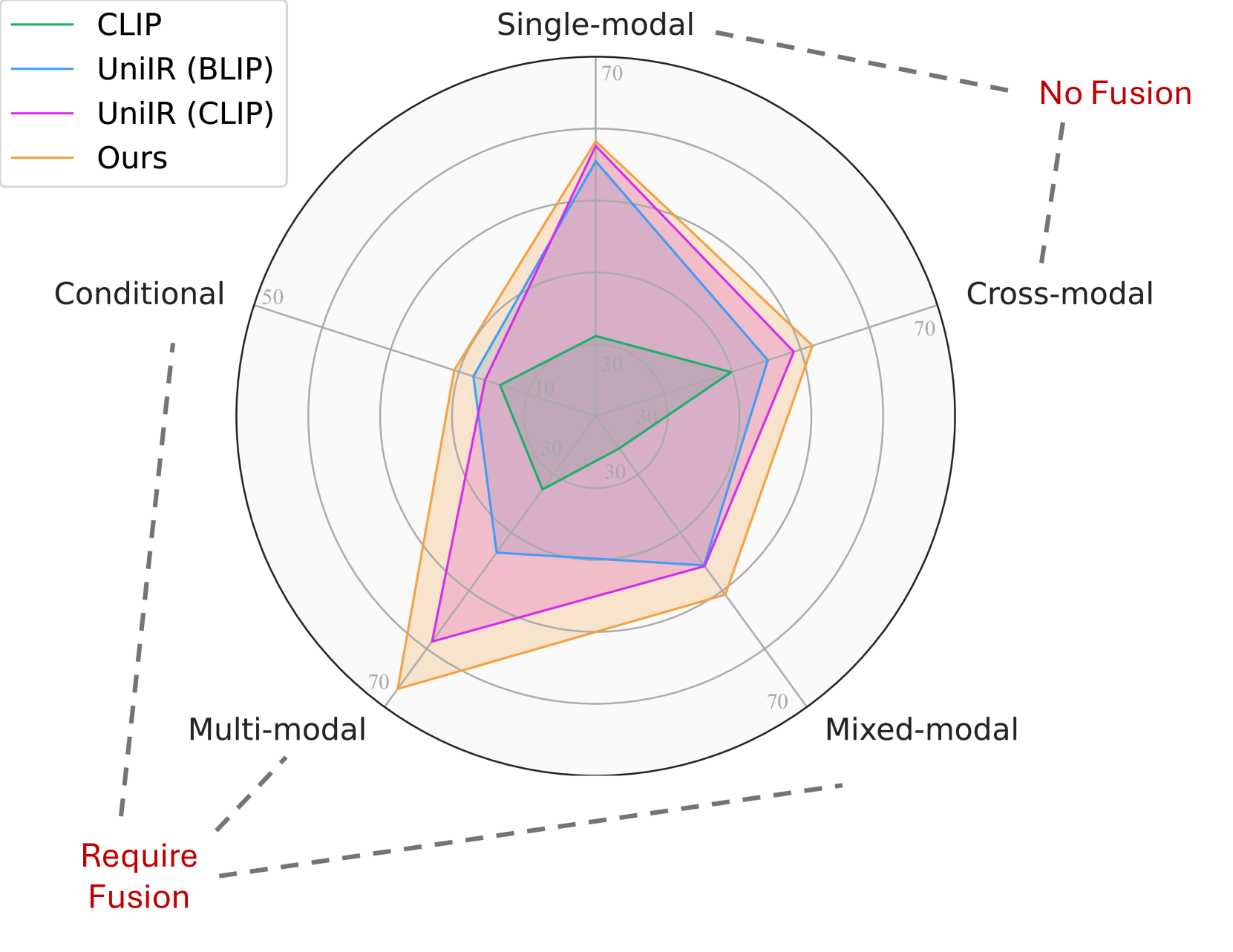
📊 实验亮点
实验结果表明,该方法在各种多模态检索场景中优于传统方法,尤其是在需要模态融合的任务中表现突出。与不需要模态融合的任务相比,联合融合编码器在需要模态融合的任务上产生了更大的改进,验证了早期集成策略的有效性。具体的性能提升数据需要在论文中进一步查找。
🎯 应用场景
该研究成果可广泛应用于图像/视频检索、跨模态问答、电商搜索等领域。通过提升多模态检索的准确性和效率,可以改善用户体验,提高信息获取效率。未来,该方法有望应用于更复杂的场景,例如智能客服、自动驾驶等,实现更智能、更人性化的信息服务。
📄 摘要(原文)
Information retrieval is indispensable for today's Internet applications, yet traditional semantic matching techniques often fall short in capturing the fine-grained cross-modal interactions required for complex queries. Although late-fusion two-tower architectures attempt to bridge this gap by independently encoding visual and textual data before merging them at a high level, they frequently overlook the subtle interplay essential for comprehensive understanding. In this work, we rigorously assess these limitations and introduce a unified retrieval framework that fuses visual and textual cues from the ground up, enabling early cross-modal interactions for enhancing context interpretation. Through a two-stage training process--comprising post-training adaptation followed by instruction tuning--we adapt MLLMs as retrievers using a simple one-tower architecture. Our approach outperforms conventional methods across diverse retrieval scenarios, particularly when processing complex multi-modal inputs. Notably, the joint fusion encoder yields greater improvements on tasks that require modality fusion compared to those that do not, underscoring the transformative potential of early integration strategies and pointing toward a promising direction for contextually aware and effective information retrieval.