Improved YOLOv12 with LLM-Generated Synthetic Data for Enhanced Apple Detection and Benchmarking Against YOLOv11 and YOLOv10
作者: Ranjan Sapkota, Manoj Karkee
分类: cs.CV, cs.CL
发布日期: 2025-02-26 (更新: 2025-03-19)
备注: 8 pages, 5 Figures, 2 Tables
💡 一句话要点
利用LLM生成的合成数据改进YOLOv12,提升苹果检测性能并超越YOLOv11和YOLOv10
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 目标检测 YOLOv12 大型语言模型 合成数据 苹果检测 农业应用 计算机视觉
📋 核心要点
- 现有苹果检测方法依赖大量真实数据,标注成本高昂且耗时,限制了模型在不同环境下的泛化能力。
- 利用大型语言模型生成逼真的苹果图像数据集,用于训练YOLOv12模型,降低数据获取成本并提升模型性能。
- 实验结果表明,基于LLM合成数据训练的YOLOv12在精度、召回率和mAP@50等指标上均优于YOLOv11和YOLOv10。
📝 摘要(中文)
本研究评估了YOLOv12目标检测模型的性能,并将其与YOLOv11和YOLOv10在商业果园中苹果检测的性能进行了比较。模型的训练完全基于大型语言模型(LLM)生成的合成图像。YOLOv12n配置实现了最高的精度0.916,最高的召回率0.969,以及最高的平均精度均值(mAP@50)0.978。相比之下,YOLOv11系列中表现最好的是YOLO11x,其精度为0.857,召回率为0.85,mAP@50为0.91。对于YOLOv10系列,YOLOv10b和YOLOv10l均实现了最高的精度0.85,而YOLOv10n实现了最高的召回率0.8和mAP@50 0.89。这些发现表明,YOLOv12在基于LLM生成的真实数据集上训练时,在关键性能指标上超越了其前代产品。该技术还通过减少农业领域中大量手动数据收集的需求,提供了一种经济高效的解决方案。此外,本研究还比较了所有版本的YOLOv12、v11和v10的计算效率,其中YOLOv11n报告的最低推理时间为4.7毫秒,而YOLOv12n为5.6毫秒,YOLOv10n为5.9毫秒。虽然YOLOv12是新的,并且比YOLOv11和YOLOv10更准确,但YOLO11n仍然是YOLOv10、YOLOv11和YOLOv12系列模型中最快的YOLO模型。
🔬 方法详解
问题定义:论文旨在解决苹果目标检测中数据获取成本高昂的问题。传统方法依赖于人工标注的大量真实图像,这在时间和经济成本上都是巨大的负担。此外,真实数据的分布可能存在偏差,导致模型在不同光照、角度和遮挡条件下泛化能力不足。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成合成图像数据集,替代或补充真实数据,用于训练YOLOv12目标检测模型。通过LLM生成多样化的、带有标注的苹果图像,降低数据获取成本,并提高模型的泛化能力。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 使用LLM生成苹果的合成图像数据集,包括不同品种、成熟度、光照条件和背景的苹果图像。2) 使用生成的合成数据集训练YOLOv12、YOLOv11和YOLOv10等目标检测模型。3) 在真实的苹果图像数据集上评估训练好的模型的性能,包括精度、召回率和mAP@50等指标。4) 比较不同模型的计算效率,包括推理时间。
关键创新:该研究的关键创新在于将大型语言模型应用于目标检测的数据生成。与传统的图像生成方法相比,LLM能够生成更逼真、更多样化的图像,并且可以方便地控制图像的属性,例如苹果的品种、成熟度和光照条件。此外,该研究还验证了使用合成数据训练的YOLOv12模型在真实数据上的有效性。
关键设计:论文中关键的设计包括:1) 使用特定的LLM(具体模型未知)生成苹果图像,并设计合适的prompt来控制生成图像的质量和多样性。2) 选择YOLOv12作为目标检测模型,并针对苹果检测任务进行微调。3) 使用标准的评估指标(精度、召回率、mAP@50)来评估模型的性能。4) 比较不同版本的YOLO模型(YOLOv12n, YOLOv11x, YOLOv10b/l/n)在性能和计算效率上的差异。
🖼️ 关键图片

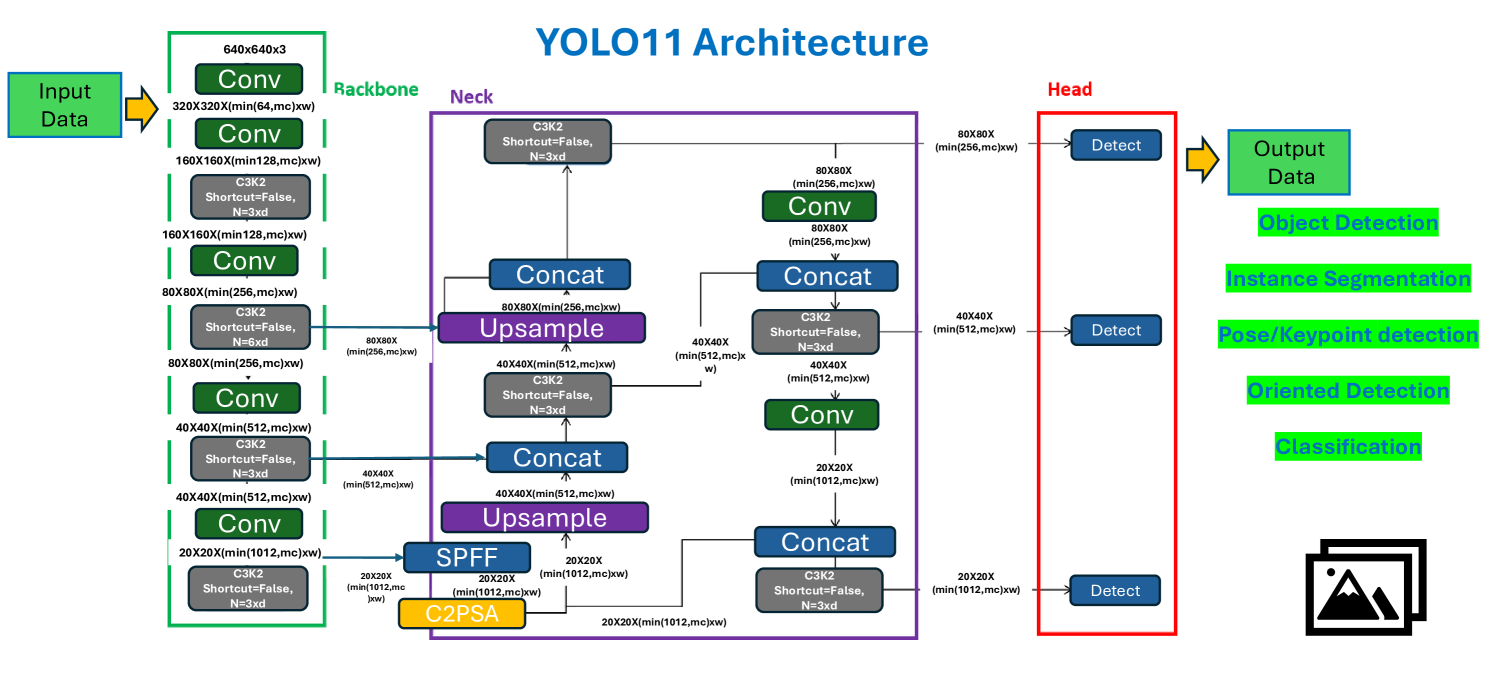
📊 实验亮点
实验结果表明,基于LLM合成数据训练的YOLOv12n在苹果检测任务中取得了显著的性能提升,精度达到0.916,召回率达到0.969,mAP@50达到0.978,均优于YOLOv11和YOLOv10系列模型。虽然YOLOv11n的推理速度最快(4.7ms),但YOLOv12n在精度上具有明显优势。
🎯 应用场景
该研究成果可广泛应用于农业领域,例如水果采摘机器人、果园病虫害监测、产量预测等。通过降低数据获取成本,可以加速目标检测技术在农业领域的应用,提高农业生产效率和智能化水平。未来,该方法还可以扩展到其他农作物和场景,例如蔬菜、谷物和畜牧业等。
📄 摘要(原文)
This study evaluated the performance of the YOLOv12 object detection model, and compared against the performances YOLOv11 and YOLOv10 for apple detection in commercial orchards based on the model training completed entirely on synthetic images generated by Large Language Models (LLMs). The YOLOv12n configuration achieved the highest precision at 0.916, the highest recall at 0.969, and the highest mean Average Precision (mAP@50) at 0.978. In comparison, the YOLOv11 series was led by YOLO11x, which achieved the highest precision at 0.857, recall at 0.85, and mAP@50 at 0.91. For the YOLOv10 series, YOLOv10b and YOLOv10l both achieved the highest precision at 0.85, with YOLOv10n achieving the highest recall at 0.8 and mAP@50 at 0.89. These findings demonstrated that YOLOv12, when trained on realistic LLM-generated datasets surpassed its predecessors in key performance metrics. The technique also offered a cost-effective solution by reducing the need for extensive manual data collection in the agricultural field. In addition, this study compared the computational efficiency of all versions of YOLOv12, v11 and v10, where YOLOv11n reported the lowest inference time at 4.7 ms, compared to YOLOv12n's 5.6 ms and YOLOv10n's 5.9 ms. Although YOLOv12 is new and more accurate than YOLOv11, and YOLOv10, YOLO11n still stays the fastest YOLO model among YOLOv10, YOLOv11 and YOLOv12 series of models. (Index: YOLOv12, YOLOv11, YOLOv10, YOLOv13, YOLOv14, YOLOv15, YOLOE, YOLO Object detection)