VOILA: Evaluation of MLLMs For Perceptual Understanding and Analogical Reasoning
作者: Nilay Yilmaz, Maitreya Patel, Yiran Lawrence Luo, Tejas Gokhale, Chitta Baral, Suren Jayasuriya, Yezhou Yang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-02-25 (更新: 2025-03-04)
备注: Accepted at ICLR 2025. Code and data: https://github.com/nlylmz/Voila
💡 一句话要点
提出VOILA基准,用于评估MLLM的感知理解和类比推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉理解 类比推理 基准测试 图像生成
📋 核心要点
- 现有MLLM在视觉理解方面表现良好,但在跨图像的抽象关系推理方面存在挑战。
- VOILA基准通过类比映射方法,要求MLLM生成图像以完成图像对之间的类比,评估其推理能力。
- 实验表明,MLLM在VOILA基准上表现不佳,难以理解图像间关系,但由简入繁的提示策略可以提高性能。
📝 摘要(中文)
多模态大型语言模型(MLLM)已成为整合视觉和文本信息的强大工具。尽管它们在视觉理解基准测试中表现出色,但衡量它们跨多个图像进行抽象推理的能力仍然是一个重大挑战。为了解决这个问题,我们引入了VOILA,这是一个大规模、开放式、动态的基准,旨在评估MLLM的感知理解和抽象关系推理能力。VOILA在视觉领域采用类比映射方法,要求模型生成一个图像,以完成两个给定的图像对(参考和应用)之间的类比,而无需依赖预定义的选项。我们的实验表明,VOILA中的类比推理任务对MLLM提出了挑战。通过多步骤分析,我们发现当前的MLLM难以理解图像间的关系,并且在高层次关系推理方面的能力有限。值得注意的是,我们观察到,遵循由简入繁的提示策略可以提高性能。对开源模型和GPT-4o的全面评估表明,在基于文本的答案中,具有挑战性场景的最佳准确率为13%(LLaMa 3.2),即使对于更简单的任务也仅为29%(GPT-4o),而人类在两个难度级别上的表现明显更高,为70%。
🔬 方法详解
问题定义:现有MLLM在视觉理解任务上取得了显著进展,但其抽象关系推理能力,特别是跨多个图像的类比推理能力,仍然是一个未被充分探索的领域。现有的视觉理解基准通常侧重于识别图像中的对象或属性,而忽略了图像之间的复杂关系。因此,缺乏一个能够有效评估MLLM在感知理解和抽象关系推理方面能力的基准。
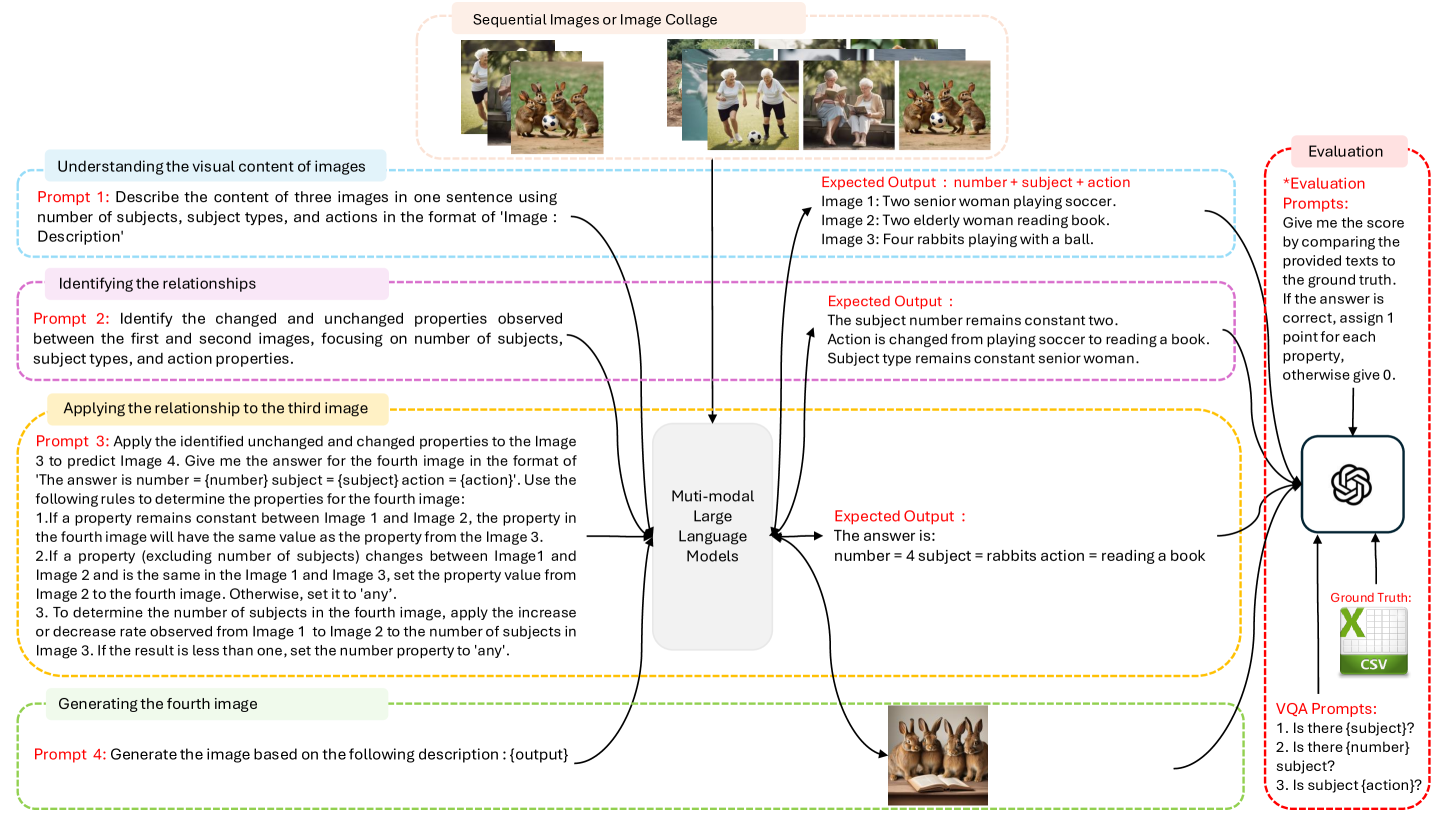
核心思路:VOILA的核心思路是利用视觉领域的类比映射来评估MLLM的推理能力。通过提供两对图像(参考对和应用对),要求MLLM生成一个图像,使得应用对之间的关系与参考对之间的关系相似。这种方法能够有效地测试MLLM理解和推理图像之间抽象关系的能力,而无需依赖预定义的选项。
技术框架:VOILA基准的整体框架包括以下几个主要组成部分:1) 数据集构建:构建包含各种视觉类比关系的大规模数据集。2) 任务定义:定义类比推理任务,要求MLLM生成完成类比的图像。3) 评估指标:设计评估MLLM生成图像质量和推理准确性的指标。4) 多步骤分析:采用多步骤分析方法,深入了解MLLM在不同推理阶段的表现。5) 由简入繁的提示策略:探索由简入繁的提示策略,以提高MLLM的推理能力。
关键创新:VOILA的关键创新在于其采用类比映射方法来评估MLLM的感知理解和抽象关系推理能力。与传统的视觉理解基准不同,VOILA侧重于评估MLLM理解和推理图像之间抽象关系的能力,而不是简单地识别图像中的对象或属性。此外,VOILA是一个开放式基准,允许MLLM生成图像,而不是从预定义的选项中进行选择,这使得评估更加全面和具有挑战性。
关键设计:VOILA的关键设计包括:1) 数据集的多样性:数据集包含各种视觉类比关系,涵盖不同的对象、属性和场景。2) 任务的难度:任务的难度可调,允许评估MLLM在不同难度级别下的推理能力。3) 评估指标的全面性:评估指标包括图像质量、推理准确性和一致性等方面,以全面评估MLLM的性能。4) 多步骤分析的细致性:多步骤分析深入了解MLLM在不同推理阶段的表现,有助于发现其优势和不足。5) 由简入繁的提示策略的有效性:由简入繁的提示策略能够有效地提高MLLM的推理能力,表明了提示工程在提高MLLM性能方面的重要性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,当前MLLM在VOILA基准上表现不佳,在具有挑战性的场景中,最佳准确率仅为13%(LLaMa 3.2),即使在更简单的任务中也仅为29%(GPT-4o),而人类的准确率高达70%。然而,研究发现,采用由简入繁的提示策略可以显著提高MLLM的性能,这表明提示工程在提高MLLM推理能力方面具有重要作用。
🎯 应用场景
VOILA基准的潜在应用领域包括:提升多模态大语言模型在复杂视觉场景下的推理能力,改进图像生成和编辑,以及开发更智能的视觉助手。该研究的实际价值在于推动人工智能在视觉理解和推理方面的发展,未来影响包括更智能的机器人、更强大的图像搜索引擎和更自然的视觉交互界面。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have become a powerful tool for integrating visual and textual information. Despite their exceptional performance on visual understanding benchmarks, measuring their ability to reason abstractly across multiple images remains a significant challenge. To address this, we introduce VOILA, a large-scale, open-ended, dynamic benchmark designed to evaluate MLLMs' perceptual understanding and abstract relational reasoning. VOILA employs an analogical mapping approach in the visual domain, requiring models to generate an image that completes an analogy between two given image pairs, reference and application, without relying on predefined choices. Our experiments demonstrate that the analogical reasoning tasks in VOILA present a challenge to MLLMs. Through multi-step analysis, we reveal that current MLLMs struggle to comprehend inter-image relationships and exhibit limited capabilities in high-level relational reasoning. Notably, we observe that performance improves when following a multi-step strategy of least-to-most prompting. Comprehensive evaluations on open-source models and GPT-4o show that on text-based answers, the best accuracy for challenging scenarios is 13% (LLaMa 3.2) and even for simpler tasks is only 29% (GPT-4o), while human performance is significantly higher at 70% across both difficulty levels.