IMPROVE: Iterative Model Pipeline Refinement and Optimization Leveraging LLM Experts
作者: Eric Xue, Ke Chen, Zeyi Huang, Yuyang Ji, Haohan Wang
分类: cs.CV, cs.LG
发布日期: 2025-02-25 (更新: 2025-09-16)
💡 一句话要点
IMPROVE:利用LLM专家迭代优化机器学习流水线,提升对象分类性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM代理 机器学习流水线 迭代优化 自动化机器学习 对象分类
📋 核心要点
- 现有基于LLM的机器学习流水线优化方法缺乏细粒度,难以将改进归因于特定更改,导致优化不稳定和收敛缓慢。
- 论文提出迭代优化策略,模仿人类专家,每次迭代只关注流水线中的一个组件,基于训练反馈逐步改进。
- 通过在IMPROVE框架中实现迭代优化策略,并在多个数据集上进行评估,验证了其优于现有零样本LLM方法的性能。
📝 摘要(中文)
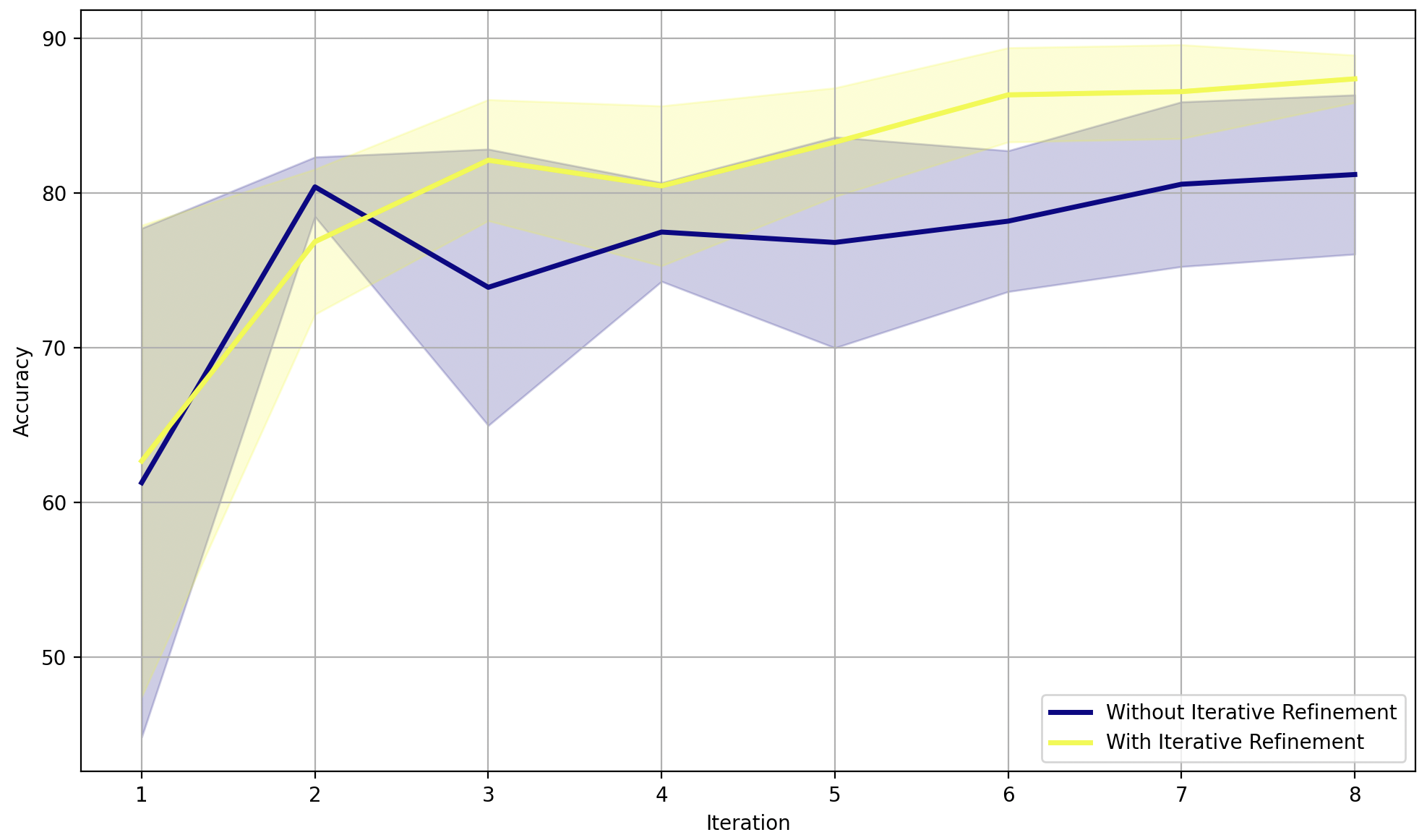
本文提出了一种新颖的基于LLM的机器学习流水线设计策略,称为迭代优化(Iterative Refinement)。与现有方法试图一步到位优化整个流水线不同,该策略受人类专家迭代优化模型的启发,每次只关注一个组件的更新。通过基于实际训练反馈系统地更新各个组件,迭代优化能够提升整体模型性能。论文还提供了迭代优化优越性的理论依据。作者在IMPROVE中实现了该策略,IMPROVE是一个用于自动化和优化对象分类流水线的端到端LLM代理框架。在不同大小和领域的数据集上进行的大量评估表明,与现有的基于LLM的零样本方法相比,迭代优化使IMPROVE能够始终如一地获得更好的性能。
🔬 方法详解
问题定义:现有基于LLM的机器学习流水线自动化方法通常尝试一步优化整个流水线,这使得难以追踪和归因于特定组件的改进。这种缺乏细粒度的优化方式导致训练过程不稳定,收敛速度慢,最终限制了整体性能。因此,需要一种更精细、更可控的优化策略。
核心思路:论文的核心思路是借鉴人类机器学习专家的迭代优化方法。专家通常不会一次性修改整个模型,而是逐步调整各个组件,并根据实验结果进行反馈和调整。论文将这种思想引入到LLM驱动的流水线优化中,通过迭代地改进单个组件来提升整体性能。
技术框架:IMPROVE框架包含以下主要模块:1) LLM代理:负责生成和修改机器学习流水线的各个组件;2) 训练模块:负责训练当前流水线,并生成反馈信息;3) 评估模块:负责评估训练结果,并将评估结果反馈给LLM代理;4) 迭代优化模块:根据评估结果,选择需要优化的组件,并指示LLM代理进行修改。整个流程是一个循环迭代的过程,直到达到预定的性能指标或迭代次数。
关键创新:最重要的技术创新点是迭代优化策略。与现有方法一次性优化整个流水线不同,迭代优化每次只关注一个组件的改进,从而能够更精确地控制优化过程,并更容易地追踪和归因于特定更改带来的影响。这种精细化的优化方式能够提高训练的稳定性和收敛速度。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节。这些细节可能取决于具体的机器学习任务和数据集。但是,迭代优化策略本身是一种通用的优化框架,可以应用于各种不同的机器学习流水线和任务。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在不同大小和领域的数据集上,IMPROVE框架通过迭代优化策略,始终能够获得优于现有基于LLM的零样本方法的性能。具体的性能提升幅度未知,但论文强调了其一致性和稳定性。这表明迭代优化策略在实际应用中具有良好的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可应用于自动化机器学习(AutoML)领域,降低机器学习模型开发的门槛,加速模型迭代和优化过程。尤其适用于需要快速部署和调整模型的场景,例如智能客服、推荐系统、图像识别等。未来,该方法有望扩展到更复杂的机器学习任务和流水线,例如自然语言处理、强化学习等。
📄 摘要(原文)
Large language model (LLM) agents have emerged as a promising solution to automate the workflow of machine learning, but most existing methods share a common limitation: they attempt to optimize entire pipelines in a single step before evaluation, making it difficult to attribute improvements to specific changes. This lack of granularity leads to unstable optimization and slower convergence, limiting their effectiveness. To address this, we introduce Iterative Refinement, a novel strategy for LLM-driven ML pipeline design inspired by how human ML experts iteratively refine models, focusing on one component at a time rather than making sweeping changes all at once. By systematically updating individual components based on real training feedback, Iterative Refinement improves overall model performance. We also provide some theoretical edvience of the superior properties of this Iterative Refinement. Further, we implement this strategy in IMPROVE, an end-to-end LLM agent framework for automating and optimizing object classification pipelines. Through extensive evaluations across datasets of varying sizes and domains, we demonstrate that Iterative Refinement enables IMPROVE to consistently achieve better performance over existing zero-shot LLM-based approaches.