Detecting Offensive Memes with Social Biases in Singapore Context Using Multimodal Large Language Models
作者: Cao Yuxuan, Wu Jiayang, Alistair Cheong Liang Chuen, Bryan Shan Guanrong, Theodore Lee Chong Jen, Sherman Chann Zhi Shen
分类: cs.CV, cs.CL
发布日期: 2025-02-25 (更新: 2025-03-08)
备注: Accepted at 3rd Workshop on Cross-Cultural Considerations in NLP (C3NLP), co-located with NAACL 2025. This is an extended version with some appendix moved to the main body
🔗 代码/项目: GITHUB
💡 一句话要点
利用多模态大语言模型,检测新加坡语境下带有社会偏见的攻击性表情包
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉语言模型 攻击性表情包检测 社会偏见 新加坡语境
📋 核心要点
- 现有在线内容审核系统难以有效识别和分类表情包等复杂多模态内容,尤其是在文化背景复杂的地区。
- 论文提出利用GPT-4V标注的大规模表情包数据集,微调视觉语言模型,以提升模型对特定文化语境下攻击性内容的识别能力。
- 实验结果表明,该方法在新加坡语境下的攻击性表情包检测任务中取得了显著效果,准确率达到80.62%,AUROC达到0.8192。
📝 摘要(中文)
传统的在线内容审核系统难以对现代多模态交流方式(如表情包)进行分类,表情包是一种高度细致且信息密集的媒介。在新加坡这样文化多元的社会中,这项任务尤其困难,因为需要使用低资源语言,并且需要广泛了解当地语境才能解释在线内容。我们整理了一个包含11.2万个表情包的大型数据集,由GPT-4V进行标注,用于微调视觉语言模型(VLM),以分类新加坡语境下的攻击性表情包。我们展示了微调后的VLM在我们数据集上的有效性,并提出了一个包含OCR、翻译和一个70亿参数级别的VLM的流程。我们的解决方案在保留的测试集上达到了80.62%的准确率和0.8192的AUROC,并且可以极大地帮助人工审核在线内容。数据集、代码和模型权重已在https://github.com/aliencaocao/vlm-for-memes-aisg上开源。
🔬 方法详解
问题定义:论文旨在解决在新加坡这种文化多元的社会背景下,现有在线内容审核系统难以准确识别和分类带有社会偏见的攻击性表情包的问题。现有方法难以处理低资源语言和复杂的文化语境,导致审核效率和准确性较低。
核心思路:论文的核心思路是利用大规模多模态数据和视觉语言模型(VLM)的强大能力,通过微调VLM使其能够理解和识别新加坡语境下的攻击性表情包。通过GPT-4V标注数据,弥补了人工标注成本高昂和效率低下的问题。
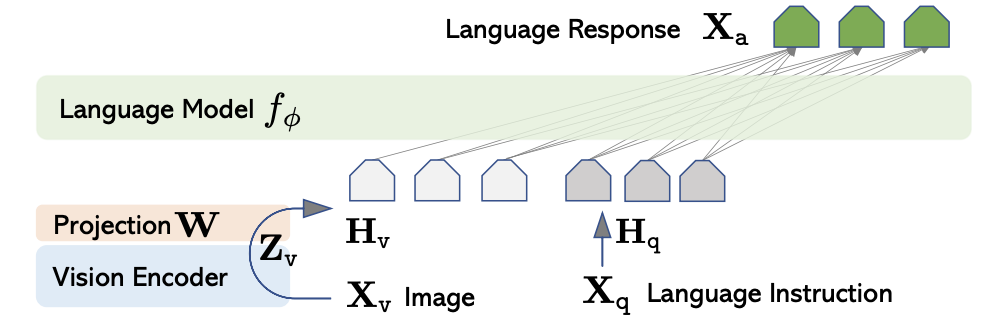
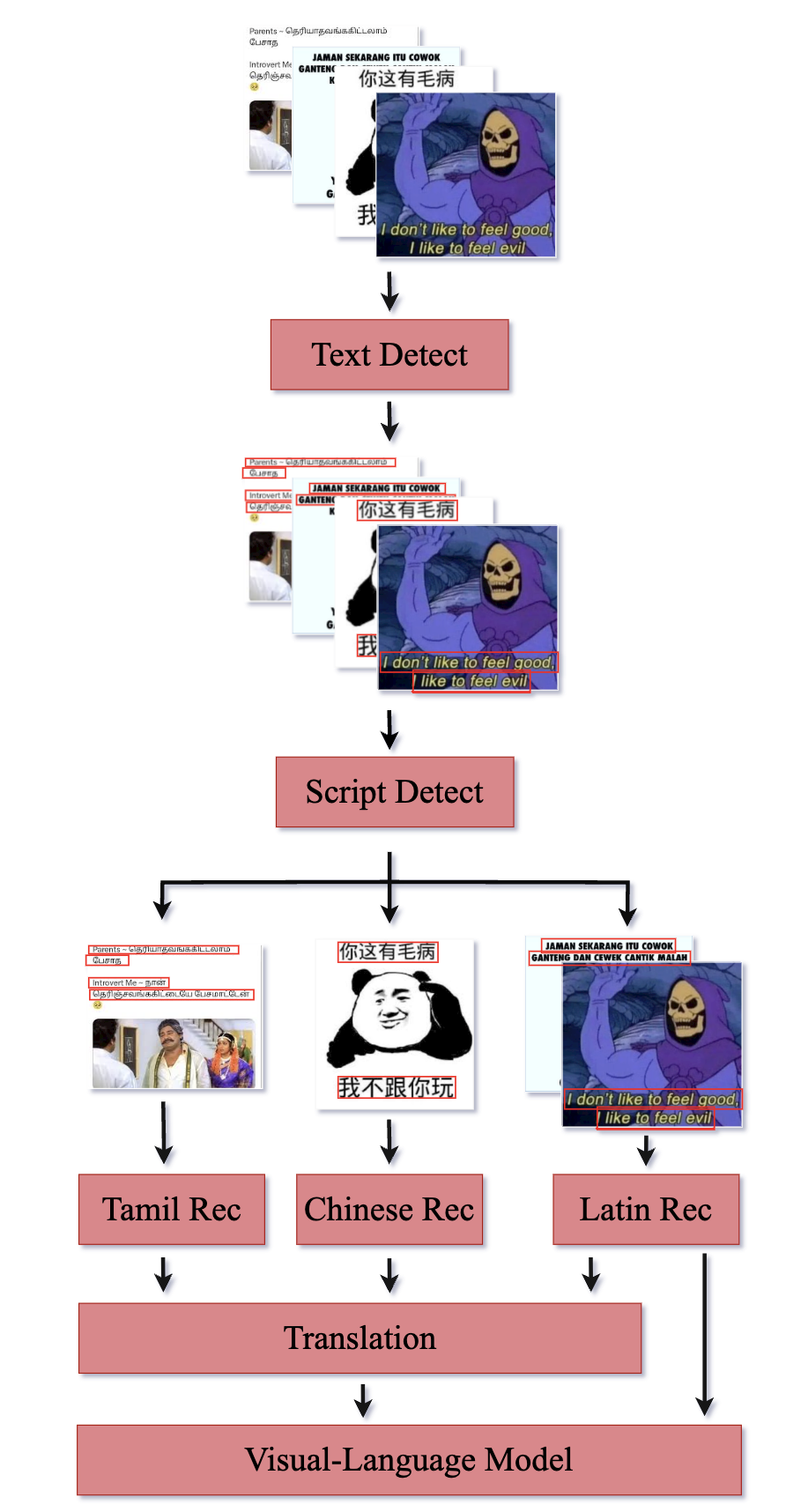
技术框架:整体流程包括以下几个主要步骤:1) 数据收集:收集了包含11.2万个表情包的大型数据集。2) 数据标注:使用GPT-4V对表情包进行标注,区分攻击性和非攻击性内容。3) 文本处理:对表情包中的文本进行OCR识别,并翻译成英文。4) 模型训练:使用标注好的数据微调一个70亿参数级别的VLM。5) 模型评估:在保留的测试集上评估模型的性能。
关键创新:论文的关键创新在于:1) 利用GPT-4V进行大规模数据标注,降低了标注成本并提高了效率。2) 提出了一个包含OCR、翻译和VLM的完整流程,能够有效处理多模态数据和低资源语言。3) 针对新加坡语境下的攻击性表情包检测问题,进行了专门的模型训练和优化。
关键设计:论文的关键设计包括:1) 使用GPT-4V进行数据标注时,设计了合适的prompt,以确保标注质量。2) 选择了一个70亿参数级别的VLM作为基础模型,以保证模型的表达能力。3) 在模型训练过程中,使用了合适的损失函数和优化器,以提高模型的收敛速度和泛化能力。具体参数设置和网络结构细节未在摘要中详细说明。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在新加坡语境下的攻击性表情包检测任务中取得了显著效果,在保留的测试集上达到了80.62%的准确率和0.8192的AUROC。这表明微调后的VLM能够有效识别和分类带有社会偏见的攻击性表情包,为在线内容审核提供了有力的技术支持。与未微调的模型相比,性能提升显著,但具体提升幅度未在摘要中给出。
🎯 应用场景
该研究成果可应用于在线社交平台的内容审核,能够自动检测和过滤带有社会偏见的攻击性表情包,从而维护健康的在线社区环境。此外,该方法也可推广到其他文化背景下的内容审核任务,具有广泛的应用前景。未来,可以进一步研究如何提高模型的鲁棒性和泛化能力,以适应不断变化的在线内容。
📄 摘要(原文)
Traditional online content moderation systems struggle to classify modern multimodal means of communication, such as memes, a highly nuanced and information-dense medium. This task is especially hard in a culturally diverse society like Singapore, where low-resource languages are used and extensive knowledge on local context is needed to interpret online content. We curate a large collection of 112K memes labeled by GPT-4V for fine-tuning a VLM to classify offensive memes in Singapore context. We show the effectiveness of fine-tuned VLMs on our dataset, and propose a pipeline containing OCR, translation and a 7-billion parameter-class VLM. Our solutions reach 80.62% accuracy and 0.8192 AUROC on a held-out test set, and can greatly aid human in moderating online contents. The dataset, code, and model weights have been open-sourced at https://github.com/aliencaocao/vlm-for-memes-aisg.