Forgotten Polygons: Multimodal Large Language Models are Shape-Blind
作者: William Rudman, Michal Golovanevsky, Amir Bar, Vedant Palit, Yann LeCun, Carsten Eickhoff, Ritambhara Singh
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-02-21 (更新: 2025-08-25)
🔗 代码/项目: GITHUB
💡 一句话要点
揭示多模态大语言模型在几何形状识别上的缺陷,并提出视觉提示链式思考方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉推理 几何形状识别 链式思考 视觉提示
📋 核心要点
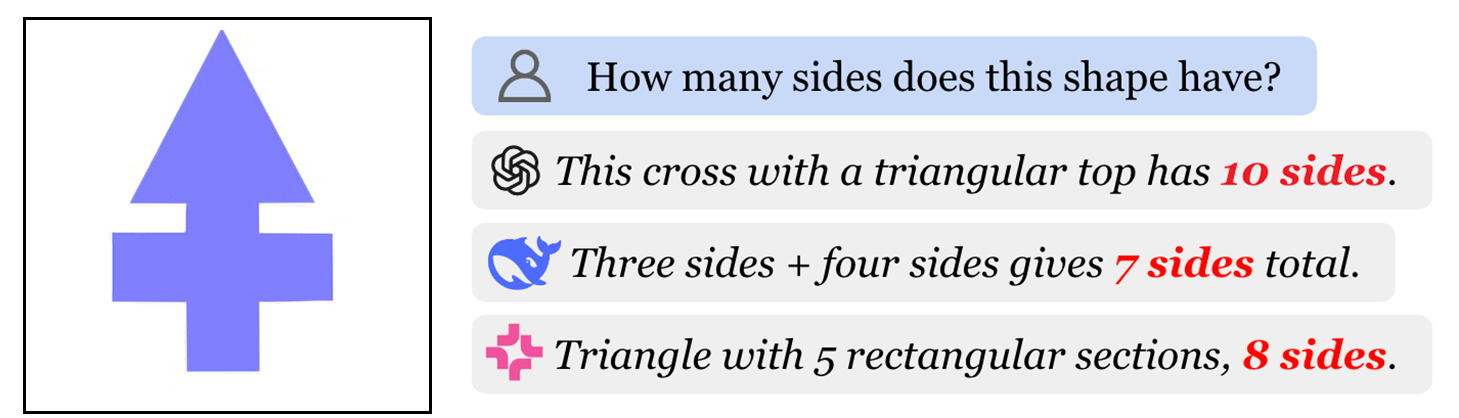
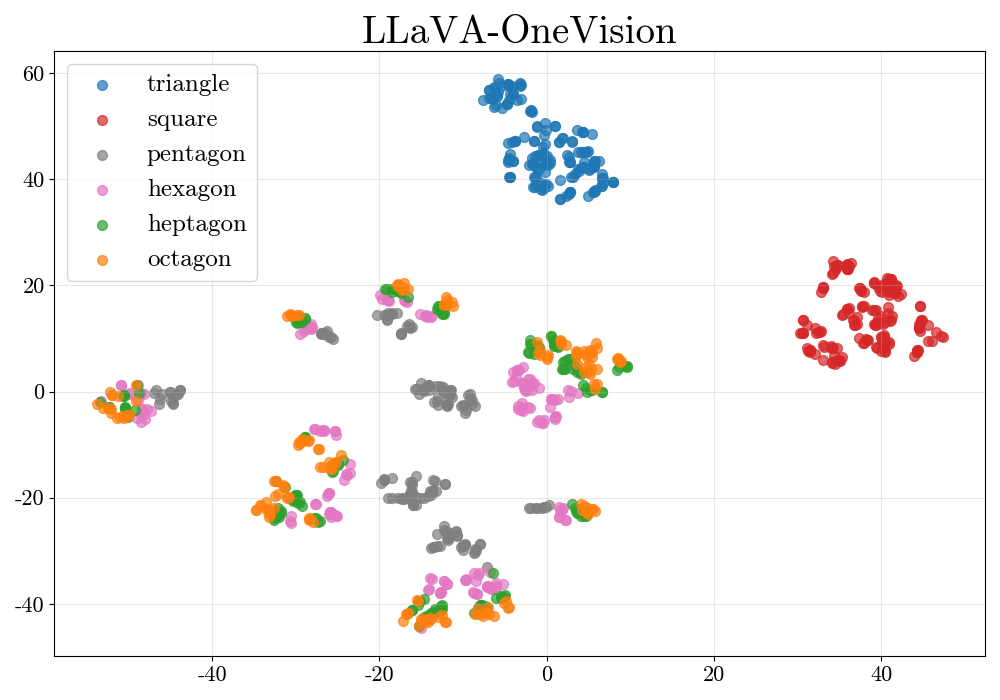
- 现有MLLM在视觉数学推理方面存在不足,尤其是在几何形状识别上,无法达到人类水平。
- 论文提出视觉提示链式思考(VC-CoT)方法,通过视觉标注引导模型进行多步推理,提升性能。
- 实验表明,VC-CoT提示显著提升了模型在不规则多边形边数计算任务上的准确率,从7%提升到93%。
📝 摘要(中文)
尽管多模态大语言模型(MLLMs)在视觉-语言任务中表现出色,但在数学问题解决方面却表现不佳,开源模型和最先进的模型在视觉-数学基准测试中均未达到人类水平。为了系统地检查 MLLMs 中的视觉-数学推理,我们(1)评估了它们对几何图元的理解,(2)测试了多步推理,以及(3)探索了一种潜在的解决方案来提高视觉推理能力。我们的研究结果揭示了形状识别方面的根本缺陷,顶级模型在识别规则多边形方面的准确率低于 50%。我们通过双过程理论分析了这些失败,并表明 MLLMs 依赖于系统 1(直观、记忆的关联),而不是系统 2(有意识的推理)。因此,MLLMs 无法计算熟悉和新颖形状的边数,表明它们既没有学习边的概念,也没有有效地处理视觉输入。最后,我们提出了视觉提示链式思考(VC-CoT)提示,通过显式引用图表中的视觉注释来增强多步数学推理,将 GPT-4o 在不规则多边形边数计算任务中的准确率从 7% 提高到 93%。我们的研究结果表明,MLLMs 中的系统 2 推理仍然是一个开放的问题,并且视觉引导提示对于成功进行视觉推理至关重要。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLMs)在视觉数学推理,特别是几何形状识别方面的不足。现有方法在处理视觉信息时,无法有效进行抽象和推理,导致在识别多边形等基本形状时表现不佳。现有模型的痛点在于缺乏对形状概念的理解,以及无法有效利用视觉信息进行推理。
核心思路:论文的核心思路是利用视觉提示链式思考(VC-CoT)来引导模型进行多步推理。通过在提示中显式地引用图表中的视觉注释,模型可以更好地理解形状的结构和属性,从而提高识别准确率。这种方法旨在激活模型的“系统2”推理能力,使其能够进行有意识的、基于规则的推理,而不是仅仅依赖于直观的、记忆的关联。
技术框架:论文的技术框架主要包括三个部分:1)评估MLLMs对几何图元的理解能力;2)测试MLLMs的多步推理能力;3)提出并验证VC-CoT提示方法。VC-CoT提示方法的核心在于在提示中加入视觉标注,例如“这个多边形有几条边?请数一下图中的边1,边2,边3...”。通过这种方式,模型可以逐步地进行推理,从而提高准确率。
关键创新:论文最重要的技术创新点在于VC-CoT提示方法。与传统的提示方法相比,VC-CoT提示方法能够更有效地引导模型进行视觉推理。通过显式地引用视觉信息,模型可以更好地理解形状的结构和属性,从而提高识别准确率。这种方法可以被看作是一种“视觉引导”的链式思考,它能够帮助模型克服在视觉推理方面的不足。
关键设计:VC-CoT提示的关键设计在于如何有效地将视觉信息融入到提示中。论文通过在提示中显式地引用图表中的视觉标注来实现这一点。例如,在计算多边形边数的任务中,提示会包含“请数一下图中的边1,边2,边3...”等信息。这种设计能够帮助模型逐步地进行推理,从而提高准确率。此外,论文还探索了不同的提示策略,例如使用不同的视觉标注方式,以及调整提示的长度和复杂度。具体的参数设置和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VC-CoT提示方法能够显著提升模型在不规则多边形边数计算任务上的准确率。具体而言,GPT-4o在原始任务中的准确率仅为7%,而采用VC-CoT提示后,准确率提升至93%。这一结果表明,VC-CoT提示方法能够有效地引导模型进行视觉推理,克服其在形状识别方面的不足。
🎯 应用场景
该研究成果可应用于提升多模态大语言模型在视觉数学、几何推理、图像理解等领域的性能。例如,可以应用于辅助设计、智能教育、机器人导航等场景,提高模型在处理复杂视觉任务时的准确性和可靠性。未来,该方法有望扩展到更广泛的视觉推理任务中。
📄 摘要(原文)
Despite strong performance on vision-language tasks, Multimodal Large Language Models (MLLMs) struggle with mathematical problem-solving, with both open-source and state-of-the-art models falling short of human performance on visual-math benchmarks. To systematically examine visual-mathematical reasoning in MLLMs, we (1) evaluate their understanding of geometric primitives, (2) test multi-step reasoning, and (3) explore a potential solution to improve visual reasoning capabilities. Our findings reveal fundamental shortcomings in shape recognition, with top models achieving under 50% accuracy in identifying regular polygons. We analyze these failures through the lens of dual-process theory and show that MLLMs rely on System 1 (intuitive, memorized associations) rather than System 2 (deliberate reasoning). Consequently, MLLMs fail to count the sides of both familiar and novel shapes, suggesting they have neither learned the concept of sides nor effectively process visual inputs. Finally, we propose Visually Cued Chain-of-Thought (VC-CoT) prompting, which enhances multi-step mathematical reasoning by explicitly referencing visual annotations in diagrams, boosting GPT-4o's accuracy on an irregular polygon side-counting task from 7% to 93%. Our findings suggest that System 2 reasoning in MLLMs remains an open problem, and visually-guided prompting is essential for successfully engaging visual reasoning. Code available at: https://github.com/rsinghlab/Shape-Blind.