LongCaptioning: Unlocking the Power of Long Video Caption Generation in Large Multimodal Models
作者: Hongchen Wei, Zhihong Tan, Yaosi Hu, Chang Wen Chen, Zhenzhong Chen
分类: cs.CV
发布日期: 2025-02-21 (更新: 2025-03-01)
💡 一句话要点
提出LongCaption-Agent框架,解决大模型长视频描述生成中长文本标注稀缺问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频描述生成 大型多模态模型 数据增强 分层语义聚合 LongCaption-Agent 长文本生成 视频理解
📋 核心要点
- 现有大模型在长视频描述生成中,难以生成超过300词的长文本,导致信息缺失。
- 提出LongCaption-Agent框架,通过分层语义聚合,自动合成长视频的长文本描述数据。
- 构建LongCaption-10K数据集和LongCaption-Bench基准,实验证明模型能生成超过1000词高质量描述,并超越GPT4o。
📝 摘要(中文)
大型多模态模型(LMMs)在视频描述任务中表现出色,尤其是在短视频方面。然而,随着视频长度的增加,生成长而详细的描述成为一项重大挑战。本文研究了LMMs在生成长视频长描述方面的局限性。分析表明,开源LMMs难以持续生成超过300个单词的输出,导致对视觉内容的不完整或过于简洁的描述。这种限制阻碍了LMMs为长视频提供全面和详细描述的能力,最终错失重要的视觉信息。通过受控实验发现,训练期间缺乏带有长描述的配对示例是限制模型输出长度的主要因素。为了克服标注瓶颈,我们提出了LongCaption-Agent,该框架通过分层语义聚合来合成长描述数据。使用LongCaption-Agent,我们创建了一个新的长描述数据集LongCaption-10K。我们还开发了LongCaption-Bench,这是一个旨在全面评估LMMs生成的长描述质量的基准。通过将LongCaption-10K纳入训练,我们使LMMs能够为长视频生成超过1,000个单词的描述,同时保持高质量的输出。在LongCaption-Bench中,我们的模型取得了最先进的性能,甚至超过了像GPT4o这样更大的专有模型。
🔬 方法详解
问题定义:现有的大型多模态模型(LMMs)在处理长视频描述生成任务时,面临着生成长文本描述的挑战。具体来说,开源LMMs难以生成超过300个单词的描述,导致对视频内容的描述不完整,遗漏关键信息。主要痛点在于缺乏足够多的长视频及其对应长文本描述的训练数据,而人工标注长视频的长文本描述成本高昂且耗时。
核心思路:论文的核心思路是通过自动化的方式合成高质量的长视频长文本描述数据,从而解决训练数据不足的问题。通过构建一个智能体(LongCaption-Agent),该智能体能够模拟人工标注的过程,对视频内容进行分层语义聚合,生成详细且全面的描述。这样可以有效降低标注成本,并为LMMs提供充足的训练数据。
技术框架:LongCaption-Agent框架采用分层语义聚合的方法生成长文本描述。整体流程包括以下几个阶段:首先,对视频进行多层次的分析,提取不同粒度的语义信息,例如场景、事件、对象等。然后,利用这些语义信息,通过智能体的推理和生成能力,逐步构建长文本描述。最后,对生成的描述进行优化和润色,确保其流畅性和准确性。
关键创新:该论文的关键创新在于提出了LongCaption-Agent框架,该框架能够自动合成高质量的长视频长文本描述数据。与传统的标注方法相比,LongCaption-Agent能够显著降低标注成本,并提高标注效率。此外,该框架还采用了分层语义聚合的方法,能够生成更加详细和全面的描述。
关键设计:LongCaption-Agent的具体实现细节未知,摘要中只提到是hierarchical semantic aggregation(分层语义聚合)。推测可能涉及多阶段的文本生成,例如先生成关键事件的简短描述,再逐步扩展为更详细的段落。损失函数的设计可能也考虑了描述的完整性和准确性,例如使用奖励机制鼓励生成更长的描述,并使用交叉熵损失函数确保描述的语义正确性。具体网络结构未知。
🖼️ 关键图片

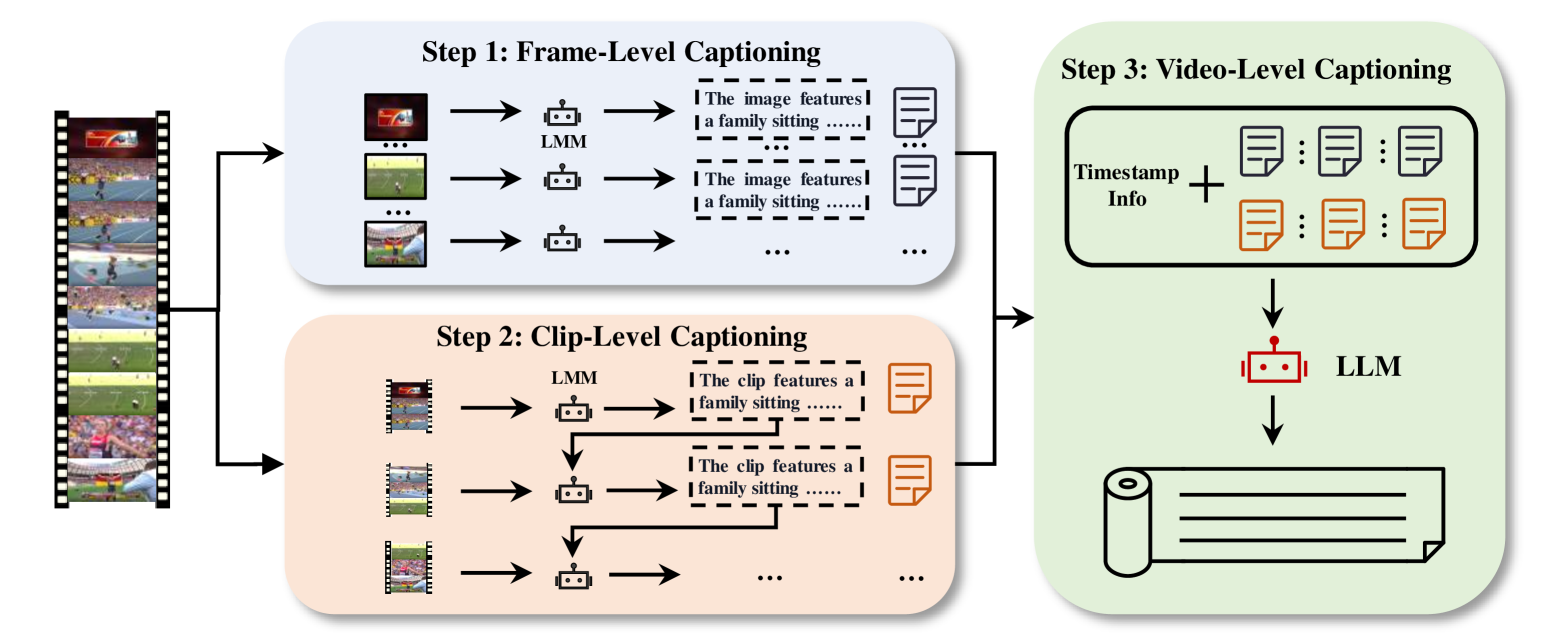

📊 实验亮点
实验结果表明,通过使用LongCaption-Agent生成的LongCaption-10K数据集进行训练,LMMs能够生成超过1000个单词的长文本描述,并且保持了较高的输出质量。在LongCaption-Bench基准测试中,该模型取得了State-of-The-Art的性能,甚至超过了GPT4o等更大的专有模型,证明了该方法的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于视频内容理解、视频搜索、智能客服、教育视频分析等领域。例如,可以为长纪录片、在线课程等生成详细的文本描述,方便用户快速了解视频内容。此外,该技术还可以用于辅助视频编辑和内容创作,提高工作效率。未来,该技术有望进一步提升多模态模型的视频理解能力,推动人工智能在视频领域的应用。
📄 摘要(原文)
Large Multimodal Models (LMMs) have demonstrated exceptional performance in video captioning tasks, particularly for short videos. However, as the length of the video increases, generating long, detailed captions becomes a significant challenge. In this paper, we investigate the limitations of LMMs in generating long captions for long videos. Our analysis reveals that open-source LMMs struggle to consistently produce outputs exceeding 300 words, leading to incomplete or overly concise descriptions of the visual content. This limitation hinders the ability of LMMs to provide comprehensive and detailed captions for long videos, ultimately missing important visual information. Through controlled experiments, we find that the scarcity of paired examples with long-captions during training is the primary factor limiting the model's output length. However, manually annotating long-caption examples for long-form videos is time-consuming and expensive. To overcome the annotation bottleneck, we propose the LongCaption-Agent, a framework that synthesizes long caption data by hierarchical semantic aggregation. % aggregating multi-level descriptions. Using LongCaption-Agent, we curated a new long-caption dataset, LongCaption-10K. We also develop LongCaption-Bench, a benchmark designed to comprehensively evaluate the quality of long captions generated by LMMs. By incorporating LongCaption-10K into training, we enable LMMs to generate captions exceeding 1,000 words for long-form videos, while maintaining high output quality. In LongCaption-Bench, our model achieved State-of-The-Art performance, even surpassing larger proprietary models like GPT4o.