SiMHand: Mining Similar Hands for Large-Scale 3D Hand Pose Pre-training
作者: Nie Lin, Takehiko Ohkawa, Yifei Huang, Mingfang Zhang, Minjie Cai, Ming Li, Ryosuke Furuta, Yoichi Sato
分类: cs.CV
发布日期: 2025-02-21 (更新: 2025-05-05)
备注: ICLR 2025. arXiv admin note: text overlap with arXiv:2409.09714
🔗 代码/项目: GITHUB
💡 一句话要点
SiMHand:挖掘相似手部图像,用于大规模3D手部姿态预训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 3D手部姿态估计 预训练 对比学习 相似性学习 大规模数据集
📋 核心要点
- 现有3D手部姿态预训练方法未能充分利用真实场景视频中大量且多样化的手部图像资源。
- SiMHand通过对比学习,将具有相似手部姿态的图像对在特征空间中拉近,从而学习判别性特征。
- 实验表明,SiMHand在FreiHand、DexYCB和AssemblyHands等数据集上显著优于现有方法,分别提升15%、10%和4%。
📝 摘要(中文)
本文提出了一种名为SiMHand的框架,用于从具有相似手部特征的真实场景手部图像中预训练3D手部姿态估计模型。大规模图像预训练在各种任务中取得了可喜的成果,但以往的3D手部姿态预训练方法尚未充分利用真实场景视频中可访问的多样化手部图像的潜力。为了促进可扩展的预训练,我们首先从真实场景视频中准备了一个广泛的手部图像池,并设计了基于对比学习的预训练方法。具体来说,我们从最近以人为中心的视频(如100DOH和Ego4D)中收集了超过200万张手部图像。为了从这些图像中提取判别信息,我们专注于手部的相似性:具有相似手部姿势的非完全相同的样本对。然后,我们提出了一种新颖的对比学习方法,该方法将相似的手部对嵌入到特征空间中更近的位置。我们的方法不仅从相似样本中学习,而且还基于样本间距离自适应地加权对比学习损失,从而带来额外的性能提升。实验表明,我们的方法优于传统的对比学习方法,后者仅从单个图像通过数据增强产生正样本对。我们在各种数据集上实现了相对于最先进方法(PeCLR)的显着改进,在FreiHand上提高了15%,在DexYCB上提高了10%,在AssemblyHands上提高了4%。
🔬 方法详解
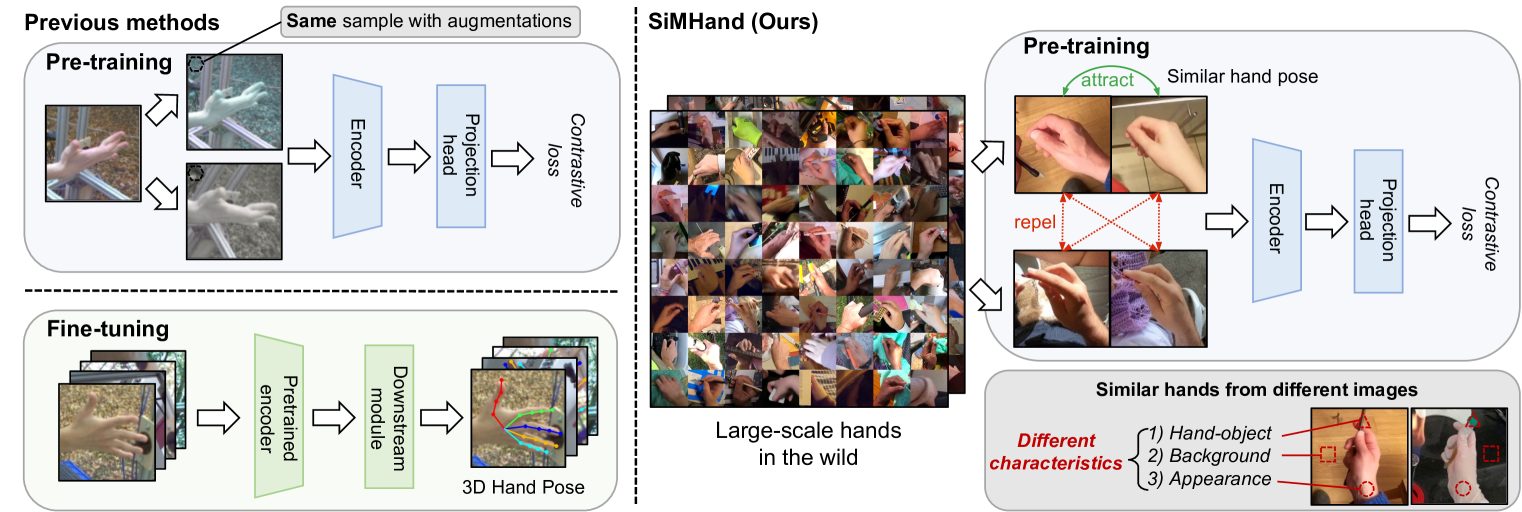
问题定义:现有3D手部姿态估计的预训练方法,未能充分利用真实场景视频中大量存在的、具有相似特征的手部图像。这些方法通常依赖于数据增强来生成正样本对,忽略了不同图像之间蕴含的相似性信息,导致模型学习效率较低。
核心思路:SiMHand的核心思路是利用对比学习,挖掘并学习具有相似手部姿态的图像对。通过将相似的手部图像在特征空间中拉近,模型能够更好地学习到手部姿态的判别性特征,从而提升3D手部姿态估计的性能。
技术框架:SiMHand的整体框架包含以下几个主要步骤:1) 从大规模真实场景视频(如100DOH和Ego4D)中收集大量手部图像。2) 针对每张手部图像,通过某种策略(例如基于关键点距离)找到与其具有相似手部姿态的其他图像,构成相似图像对。3) 使用对比学习方法,训练一个手部姿态编码器,使得相似图像对在特征空间中的距离更近。4) 将训练好的编码器作为预训练模型,用于下游的3D手部姿态估计任务。
关键创新:SiMHand的关键创新在于:1) 提出了利用相似手部图像对进行对比学习的预训练方法,充分利用了真实场景视频中的数据。2) 提出了一种自适应加权对比学习损失,根据样本间距离调整损失权重,使得模型更加关注难样本的学习。
关键设计:在对比学习损失函数的设计上,SiMHand采用了InfoNCE损失的变体,并引入了自适应权重。具体来说,对于每个样本,首先计算其与其他样本之间的距离(例如,特征向量之间的余弦相似度)。然后,根据距离的大小,对对比学习损失进行加权,使得距离较远的样本对损失的贡献更大。这种自适应加权策略能够有效地提升模型的学习效率。
🖼️ 关键图片


📊 实验亮点
SiMHand在多个公开数据集上取得了显著的性能提升。在FreiHand数据集上,SiMHand相比于最先进的方法PeCLR,取得了15%的性能提升;在DexYCB数据集上,提升了10%;在AssemblyHands数据集上,提升了4%。这些结果表明,SiMHand能够有效地利用大规模真实场景数据进行预训练,并显著提升3D手部姿态估计的性能。
🎯 应用场景
SiMHand的研究成果可广泛应用于人机交互、虚拟现实、增强现实、手势识别等领域。通过提升3D手部姿态估计的准确性和鲁棒性,可以改善用户在这些应用中的体验,例如更自然的手势控制、更精确的虚拟物体交互等。该研究也为其他需要利用大规模无标注数据的任务提供了新的思路。
📄 摘要(原文)
We present a framework for pre-training of 3D hand pose estimation from in-the-wild hand images sharing with similar hand characteristics, dubbed SimHand. Pre-training with large-scale images achieves promising results in various tasks, but prior methods for 3D hand pose pre-training have not fully utilized the potential of diverse hand images accessible from in-the-wild videos. To facilitate scalable pre-training, we first prepare an extensive pool of hand images from in-the-wild videos and design our pre-training method with contrastive learning. Specifically, we collect over 2.0M hand images from recent human-centric videos, such as 100DOH and Ego4D. To extract discriminative information from these images, we focus on the similarity of hands: pairs of non-identical samples with similar hand poses. We then propose a novel contrastive learning method that embeds similar hand pairs closer in the feature space. Our method not only learns from similar samples but also adaptively weights the contrastive learning loss based on inter-sample distance, leading to additional performance gains. Our experiments demonstrate that our method outperforms conventional contrastive learning approaches that produce positive pairs sorely from a single image with data augmentation. We achieve significant improvements over the state-of-the-art method (PeCLR) in various datasets, with gains of 15% on FreiHand, 10% on DexYCB, and 4% on AssemblyHands. Our code is available at https://github.com/ut-vision/SiMHand.