Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance
作者: Meng Wang, Fan Wu, Ruihui Li, Yunchuan Qin, Zhuo Tang, Kenli Li
分类: cs.CV
发布日期: 2025-02-20 (更新: 2025-11-10)
备注: Accepted by NeurIPS 2025
💡 一句话要点
FlowScene:利用光流引导的时序3D语义场景补全方法
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D语义场景补全 光流引导 时序建模 自动驾驶 体素表示
📋 核心要点
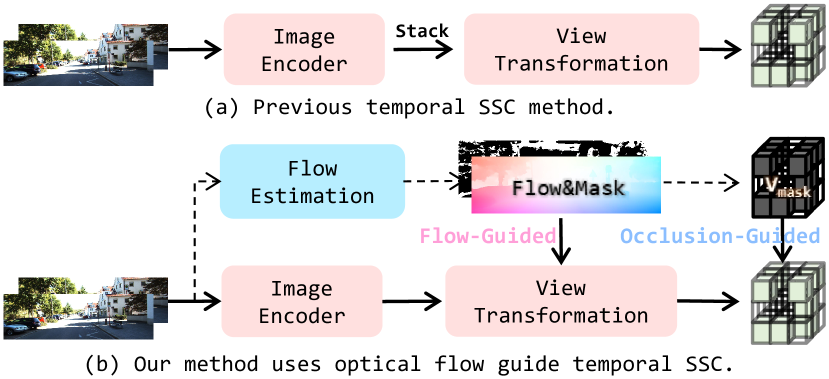
- 现有3D语义场景补全方法难以有效利用时序信息,忽略了运动动态和视角变化带来的上下文信息。
- FlowScene利用光流引导,对齐并聚合时序特征,同时考虑遮挡信息,从而提升场景补全的准确性和时间一致性。
- 实验结果表明,FlowScene在SemanticKITTI和SSCBench-KITTI-360数据集上取得了state-of-the-art的性能。
📝 摘要(中文)
3D语义场景补全(SSC)为自动驾驶感知提供全面的场景几何和语义信息,这对于实现准确和可靠的决策至关重要。然而,现有的SSC方法仅限于捕获来自当前帧的稀疏信息或简单地堆叠多帧时序特征,因此无法获取有效的场景上下文。这些方法忽略了关键的运动动态,并且难以实现时间一致性。为了解决上述挑战,我们提出了一种新的时序SSC方法FlowScene:通过光流引导学习时序3D语义场景补全。通过利用光流,FlowScene可以整合运动、不同的视角、遮挡和其他上下文线索,从而显著提高3D场景补全的准确性。具体来说,我们的框架引入了两个关键组件:(1)一个光流引导的时序聚合模块,它使用光流对齐和聚合时序特征,捕获运动感知的上下文和可变形结构;(2)一个遮挡引导的体素细化模块,它将遮挡掩码和时序聚合的特征注入到3D体素空间中,自适应地细化体素表示以进行显式的几何建模。实验结果表明,FlowScene在SemanticKITTI和SSCBench-KITTI-360基准测试中实现了最先进的性能。
🔬 方法详解
问题定义:现有的3D语义场景补全方法主要依赖于单帧信息或简单地堆叠多帧特征,无法充分利用时序信息中的运动动态、视角变化和遮挡关系。这导致场景补全的精度和时间一致性受到限制,尤其是在动态环境中表现不佳。
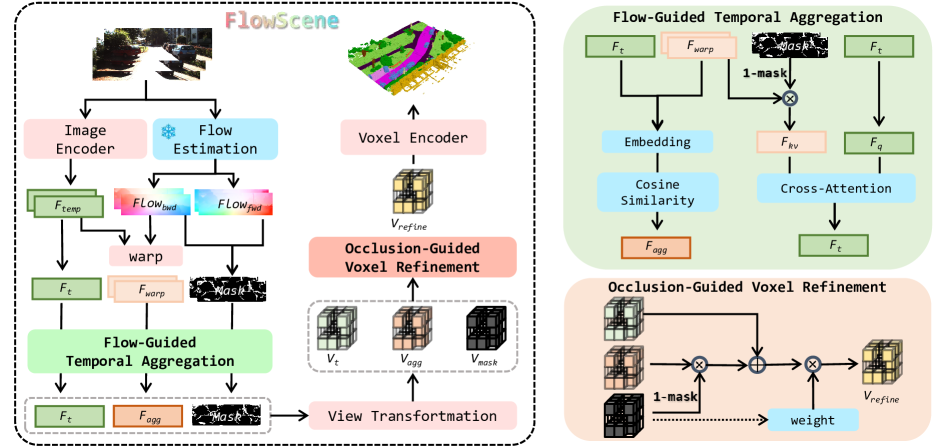
核心思路:FlowScene的核心思路是利用光流来对齐和聚合不同时刻的特征,从而有效地整合时序信息。通过光流,可以估计场景中物体的运动轨迹,并将不同视角的特征映射到统一的坐标系下。同时,考虑遮挡信息,避免将不可靠的特征用于场景补全。
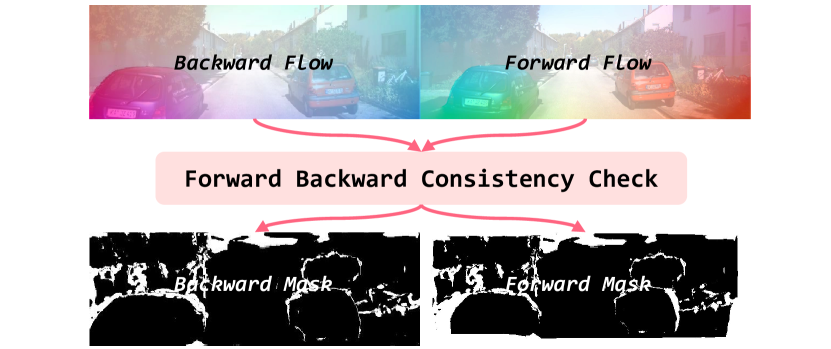
技术框架:FlowScene框架包含两个主要模块:光流引导的时序聚合模块和遮挡引导的体素细化模块。首先,光流引导的时序聚合模块利用光流信息将不同时刻的特征对齐,并进行聚合,得到运动感知的上下文特征。然后,遮挡引导的体素细化模块将遮挡掩码和时序聚合的特征注入到3D体素空间中,自适应地细化体素表示,从而实现更精确的几何建模。
关键创新:FlowScene的关键创新在于利用光流来显式地建模场景中的运动动态,并将其用于时序特征的对齐和聚合。与以往简单堆叠多帧特征的方法相比,FlowScene能够更有效地利用时序信息,提高场景补全的精度和时间一致性。此外,遮挡引导的体素细化模块能够自适应地调整体素表示,从而更好地处理遮挡区域的场景补全。
关键设计:光流引导的时序聚合模块使用一个可变形卷积网络来对齐和聚合时序特征。遮挡掩码通过一个单独的网络进行预测,并用于指导体素细化模块。损失函数包括语义分割损失和场景补全损失,用于优化网络的性能。具体网络结构和参数设置在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
FlowScene在SemanticKITTI和SSCBench-KITTI-360数据集上取得了state-of-the-art的性能。在SemanticKITTI数据集上,FlowScene的IoU指标相比于之前的最佳方法提升了显著的百分比。实验结果表明,FlowScene能够有效地利用时序信息,提高场景补全的精度和时间一致性。
🎯 应用场景
FlowScene在自动驾驶领域具有重要的应用价值。它可以为自动驾驶系统提供更全面、准确和时间一致的场景理解,从而提高自动驾驶车辆的感知能力和决策能力。此外,该方法还可以应用于机器人导航、虚拟现实和增强现实等领域,为这些应用提供更逼真的3D场景重建和语义理解。
📄 摘要(原文)
3D Semantic Scene Completion (SSC) provides comprehensive scene geometry and semantics for autonomous driving perception, which is crucial for enabling accurate and reliable decision-making. However, existing SSC methods are limited to capturing sparse information from the current frame or naively stacking multi-frame temporal features, thereby failing to acquire effective scene context. These approaches ignore critical motion dynamics and struggle to achieve temporal consistency. To address the above challenges, we propose a novel temporal SSC method FlowScene: Learning Temporal 3D Semantic Scene Completion via Optical Flow Guidance. By leveraging optical flow, FlowScene can integrate motion, different viewpoints, occlusions, and other contextual cues, thereby significantly improving the accuracy of 3D scene completion. Specifically, our framework introduces two key components: (1) a Flow-Guided Temporal Aggregation module that aligns and aggregates temporal features using optical flow, capturing motion-aware context and deformable structures; and (2) an Occlusion-Guided Voxel Refinement module that injects occlusion masks and temporally aggregated features into 3D voxel space, adaptively refining voxel representations for explicit geometric modeling. Experimental results demonstrate that FlowScene achieves state-of-the-art performance on the SemanticKITTI and SSCBench-KITTI-360 benchmarks.