Generative Video Semantic Communication via Multimodal Semantic Fusion with Large Model
作者: Hang Yin, Li Qiao, Yu Ma, Shuo Sun, Kan Li, Zhen Gao, Dusit Niyato
分类: eess.SP, cs.CV, cs.IT, eess.IV
发布日期: 2025-02-19 (更新: 2025-09-27)
备注: IEEE Transactions on Vehicular Technology
💡 一句话要点
提出基于多模态语义融合的生成式视频语义通信框架,提升低带宽下视频重建质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频语义通信 生成式AI 多模态融合 扩散模型 低带宽通信
📋 核心要点
- 传统基于香农理论的句法通信难以满足6G沉浸式通信需求,尤其在恶劣传输条件下。
- 提出一种生成式视频语义通信框架,提取并传输语义信息,利用生成式AI大模型重建视频。
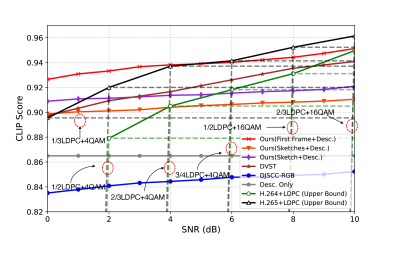
- 实验表明,该方案在极低带宽比下能有效重建视频,且“第一帧+描述”方案在低信噪比下表现出鲁棒性。
📝 摘要(中文)
本文提出了一种可扩展的生成式视频语义通信框架,旨在通过提取和传输语义信息来实现高质量的视频重建,尤其是在具有挑战性的传输条件下。在发送端,从源视频中提取描述和其他条件信号(例如,第一帧、草图等),分别作为文本和结构语义。在接收端,利用基于扩散的生成式人工智能大模型来融合多模态的语义,从而重建视频。仿真结果表明,在极低的信道带宽比(CBR)下,该方案能够有效地捕获语义信息,以重建与人类感知对齐的视频,且在不同的信噪比下均表现良好。值得注意的是,所提出的“第一帧+描述”方案在CBR = 0.0057且SNR > 0 dB时,始终达到超过0.92的CLIP分数。这证明了即使在低信噪比条件下,该方案也具有鲁棒的性能。
🔬 方法详解
问题定义:现有基于香农理论的传统通信方法在带宽受限和信道条件恶劣的情况下,难以保证视频传输的质量,无法满足6G沉浸式通信对于高质量视频体验的需求。这些方法主要关注信号的精确传输,而忽略了视频内容的高层语义信息,导致在低带宽下视频重建质量差,用户体验不佳。
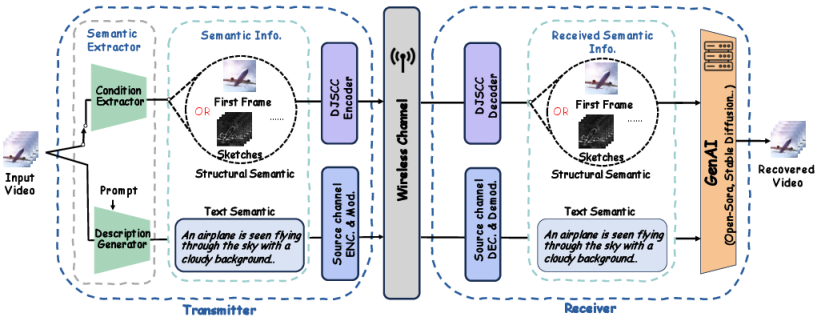
核心思路:本文的核心思路是利用生成式人工智能(GenAI)大模型,将视频内容分解为多模态的语义信息(例如文本描述和结构信息),并在接收端通过融合这些语义信息来重建视频。这种方法关注视频内容本身,而非像素级别的精确传输,从而可以在极低的带宽下实现高质量的视频重建。
技术框架:该框架主要包含发送端和接收端两个部分。在发送端,首先从源视频中提取文本描述(例如,使用图像描述模型)和结构信息(例如,第一帧或草图)。然后,对这些语义信息进行编码并通过信道传输。在接收端,利用基于扩散模型的GenAI大模型,将接收到的文本描述和结构信息进行融合,生成重建的视频。
关键创新:该论文的关键创新在于将多模态语义信息融合与生成式AI大模型相结合,用于视频语义通信。与传统的基于像素传输的视频编码方法不同,该方法关注视频内容的高层语义,从而可以在极低的带宽下实现高质量的视频重建。此外,利用多种模态的语义信息(文本描述和结构信息)可以提高视频重建的质量和鲁棒性。
关键设计:在发送端,可以使用不同的模型来提取文本描述和结构信息,例如,可以使用预训练的图像描述模型来生成视频的文本描述,并使用视频的第一帧或关键帧作为结构信息。在接收端,可以使用基于扩散模型的GenAI大模型,例如Stable Diffusion或其变体,来融合多模态的语义信息并生成重建的视频。损失函数可以包括CLIP score等,用于衡量重建视频与原始视频在语义上的相似度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在极低的信道带宽比(CBR = 0.0057)下,该方案能够有效地捕获语义信息,重建与人类感知对齐的视频。特别地,“第一帧+描述”方案在SNR > 0 dB时,CLIP score始终超过0.92,证明了其在低信噪比条件下的鲁棒性。这表明该方法在极低带宽和恶劣信道条件下,仍能保持较高的视频重建质量。
🎯 应用场景
该研究成果可应用于带宽受限的无线通信场景,如移动视频直播、远程监控、视频会议等。在这些场景下,传统的视频编码方法难以提供高质量的视频体验,而该研究提出的方法可以通过语义通信的方式,在极低的带宽下实现高质量的视频传输和重建,提升用户体验。此外,该技术还可应用于视频修复、视频生成等领域。
📄 摘要(原文)
Despite significant advancements in traditional syntactic communications based on Shannon's theory, these methods struggle to meet the requirements of 6G immersive communications, especially under challenging transmission conditions. With the development of generative artificial intelligence (GenAI), progress has been made in reconstructing videos using high-level semantic information. In this paper, we propose a scalable generative video semantic communication framework that extracts and transmits semantic information to achieve high-quality video reconstruction. Specifically, at the transmitter, description and other condition signals (e.g., first frame, sketches, etc.) are extracted from the source video, functioning as text and structural semantics, respectively. At the receiver, the diffusion-based GenAI large models are utilized to fuse the semantics of the multiple modalities for reconstructing the video. Simulation results demonstrate that, at an ultra-low channel bandwidth ratio (CBR), our scheme effectively captures semantic information to reconstruct videos aligned with human perception under different signal-to-noise ratios. Notably, the proposed ``First Frame+Desc." scheme consistently achieves CLIP score exceeding 0.92 at CBR = 0.0057 for SNR > 0 dB. This demonstrates its robust performance even under low SNR conditions.