Geolocation with Real Human Gameplay Data: A Large-Scale Dataset and Human-Like Reasoning Framework
作者: Zirui Song, Jingpu Yang, Yuan Huang, Jonathan Tonglet, Zeyu Zhang, Tao Cheng, Meng Fang, Iryna Gurevych, Xiuying Chen
分类: cs.CV
发布日期: 2025-02-19 (更新: 2026-01-06)
备注: Update new version
💡 一句话要点
提出GeoComp数据集与GeoCoT框架,提升地理定位精度与可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 地理定位 大规模数据集 链式思考 视觉推理 可解释性
📋 核心要点
- 现有地理定位方法精度低、可解释性差,且数据集规模小、质量参差不齐,难以训练出鲁棒模型。
- 论文提出GeoComp数据集和GeoCoT推理框架,GeoComp提供大规模高质量标注,GeoCoT模拟人类推理过程。
- 实验表明,GeoCoT在GeoComp数据集上显著提升了地理定位精度,并增强了模型的可解释性。
📝 摘要(中文)
地理定位,即识别图像位置的任务,需要复杂的推理,对导航、监控和文化保护至关重要。然而,当前方法通常产生粗糙、不精确且难以解释的定位结果。一个主要挑战在于现有地理定位数据集的质量和规模。这些数据集通常规模较小且自动构建,导致数据嘈杂和任务难度不一致,图像要么过于容易揭示答案,要么缺乏足够的线索进行可靠的推断。为了应对这些挑战,我们引入了一个全面的地理定位框架,包含三个关键组件:GeoComp(一个大规模数据集)、GeoCoT(一种新颖的推理方法)和GeoEval(一种评估指标),共同旨在解决关键挑战并推动地理定位研究的进步。该框架的核心是GeoComp(地理定位竞赛数据集),这是一个大规模数据集,收集自一个地理定位游戏平台,涉及740K用户,历时两年。它包含2500万条元数据条目和300万个地理标记位置,覆盖全球大部分地区,每个位置都由人类用户标注数千到数万次。该数据集为详细分析提供了不同的难度级别,并突出了当前模型中的关键差距。在此数据集的基础上,我们提出了地理链式思考(GeoCoT),这是一种新颖的多步骤推理框架,旨在增强大型视觉模型(LVM)在地理定位任务中的推理能力。GeoCoT通过整合上下文和空间线索,并通过模仿人类地理定位推理的多步骤过程来提高性能。最后,使用GeoEval指标,我们证明GeoCoT显著提高了地理定位精度高达25%,同时增强了可解释性。
🔬 方法详解
问题定义:地理定位任务旨在根据图像内容确定其拍摄地点。现有方法依赖的数据集规模小、质量低,且模型推理过程缺乏可解释性。现有方法难以捕捉图像中的细微线索,导致定位精度不高,且无法解释定位结果的依据。
核心思路:论文的核心思路是构建一个大规模、高质量的地理定位数据集,并设计一个模仿人类推理过程的框架。GeoComp数据集提供丰富的标注信息,GeoCoT框架通过多步骤推理,逐步缩小定位范围,最终确定图像位置。这种设计旨在提高定位精度和可解释性。
技术框架:整体框架包含三个主要组件:GeoComp数据集、GeoCoT推理框架和GeoEval评估指标。GeoComp数据集是GeoCoT框架的基础,提供训练和评估数据。GeoCoT框架利用GeoComp数据集进行训练,并执行地理定位任务。GeoEval评估指标用于评估GeoCoT框架的性能。GeoCoT框架包含多个推理步骤,每个步骤都利用不同的信息源(例如,图像内容、地理信息)。
关键创新:最重要的技术创新点在于GeoComp数据集的构建和GeoCoT推理框架的设计。GeoComp数据集是目前最大的地理定位数据集之一,具有高质量的标注信息。GeoCoT推理框架通过模仿人类推理过程,提高了定位精度和可解释性。与现有方法相比,GeoCoT框架能够更好地利用图像中的细微线索,并提供更清晰的推理过程。
关键设计:GeoCoT框架的关键设计包括多步骤推理过程、上下文和空间线索的整合以及损失函数的设计。多步骤推理过程允许模型逐步缩小定位范围,提高定位精度。上下文和空间线索的整合使模型能够更好地理解图像内容和地理环境。损失函数的设计旨在优化模型的推理能力。
🖼️ 关键图片
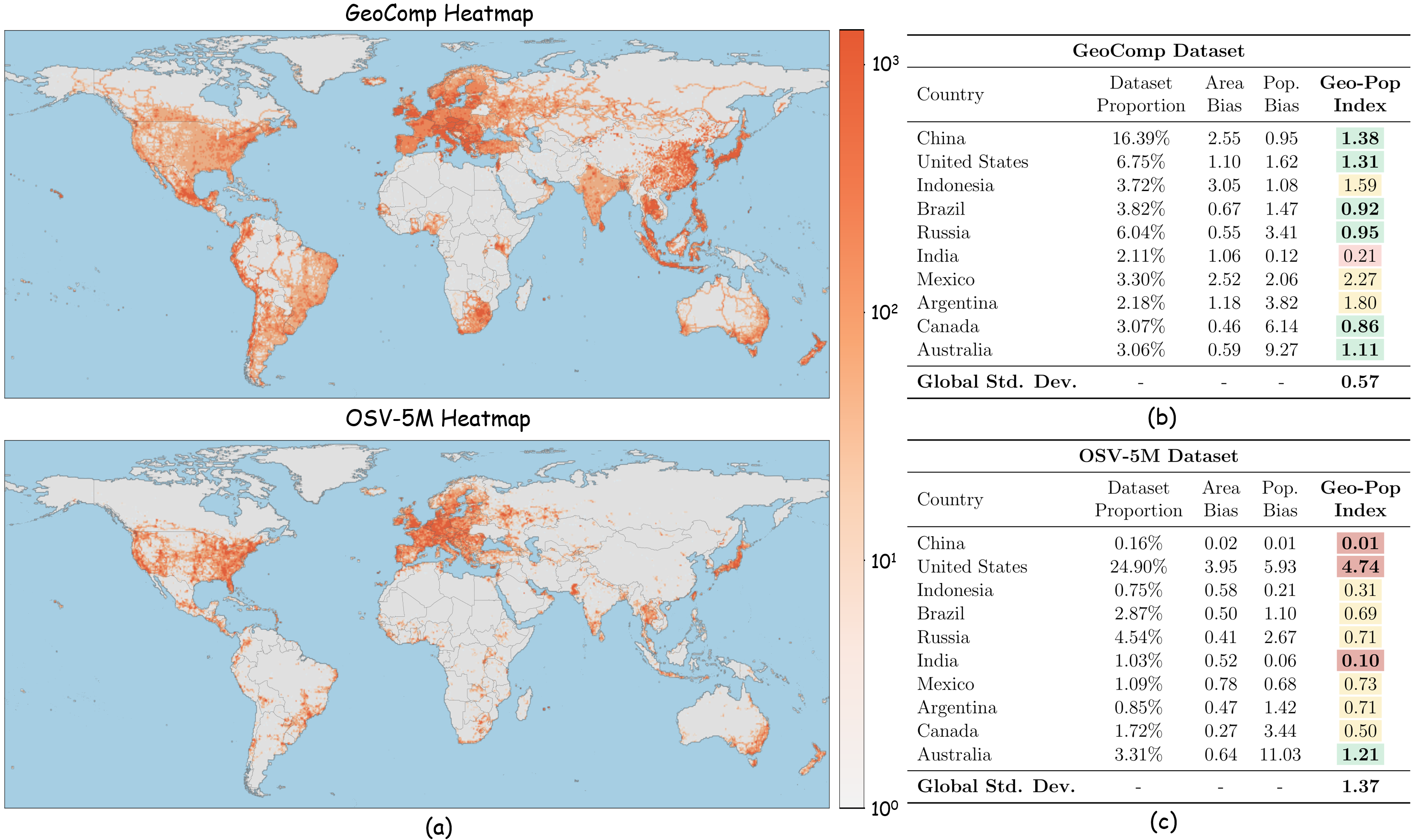


📊 实验亮点
GeoCoT框架在GeoComp数据集上取得了显著的性能提升,地理定位精度提高了高达25%。实验结果表明,GeoCoT框架能够有效地利用图像中的细微线索,并提供更清晰的推理过程。此外,GeoEval评估指标也为地理定位研究提供了一个新的评估标准。
🎯 应用场景
该研究成果可应用于导航系统、环境监测、文化遗产保护等领域。例如,可以利用该技术开发更精确的图像地理定位服务,帮助用户快速找到图像的拍摄地点。此外,该技术还可以用于监测环境变化,例如森林砍伐、城市扩张等。在文化遗产保护方面,该技术可以用于识别和定位历史遗迹,帮助保护文化遗产。
📄 摘要(原文)
Geolocation, the task of identifying an image's location, requires complex reasoning and is crucial for navigation, monitoring, and cultural preservation. However, current methods often produce coarse, imprecise, and non-interpretable localization. A major challenge lies in the quality and scale of existing geolocation datasets. These datasets are typically small-scale and automatically constructed, leading to noisy data and inconsistent task difficulty, with images that either reveal answers too easily or lack sufficient clues for reliable inference. To address these challenges, we introduce a comprehensive geolocation framework with three key components: GeoComp, a large-scale dataset; GeoCoT, a novel reasoning method; and GeoEval, an evaluation metric, collectively designed to address critical challenges and drive advancements in geolocation research. At the core of this framework is GeoComp (Geolocation Competition Dataset), a large-scale dataset collected from a geolocation game platform involving 740K users over two years. It comprises 25 million entries of metadata and 3 million geo-tagged locations spanning much of the globe, with each location annotated thousands to tens of thousands of times by human users. The dataset offers diverse difficulty levels for detailed analysis and highlights key gaps in current models. Building on this dataset, we propose Geographical Chain-of-Thought (GeoCoT), a novel multi-step reasoning framework designed to enhance the reasoning capabilities of Large Vision Models (LVMs) in geolocation tasks. GeoCoT improves performance by integrating contextual and spatial cues through a multi-step process that mimics human geolocation reasoning. Finally, using the GeoEval metric, we demonstrate that GeoCoT significantly boosts geolocation accuracy by up to 25% while enhancing interpretability.