SNN-Driven Multimodal Human Action Recognition via Sparse Spatial-Temporal Data Fusion
作者: Naichuan Zheng, Hailun Xia, Zeyu Liang, Yuchen Du
分类: cs.CV
发布日期: 2025-02-19 (更新: 2025-12-22)
💡 一句话要点
提出基于SNN的多模态人体行为识别框架,解决资源受限场景下的高功耗问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脉冲神经网络 多模态融合 人体行为识别 事件相机 骨骼数据 信息瓶颈 低功耗 图卷积网络
📋 核心要点
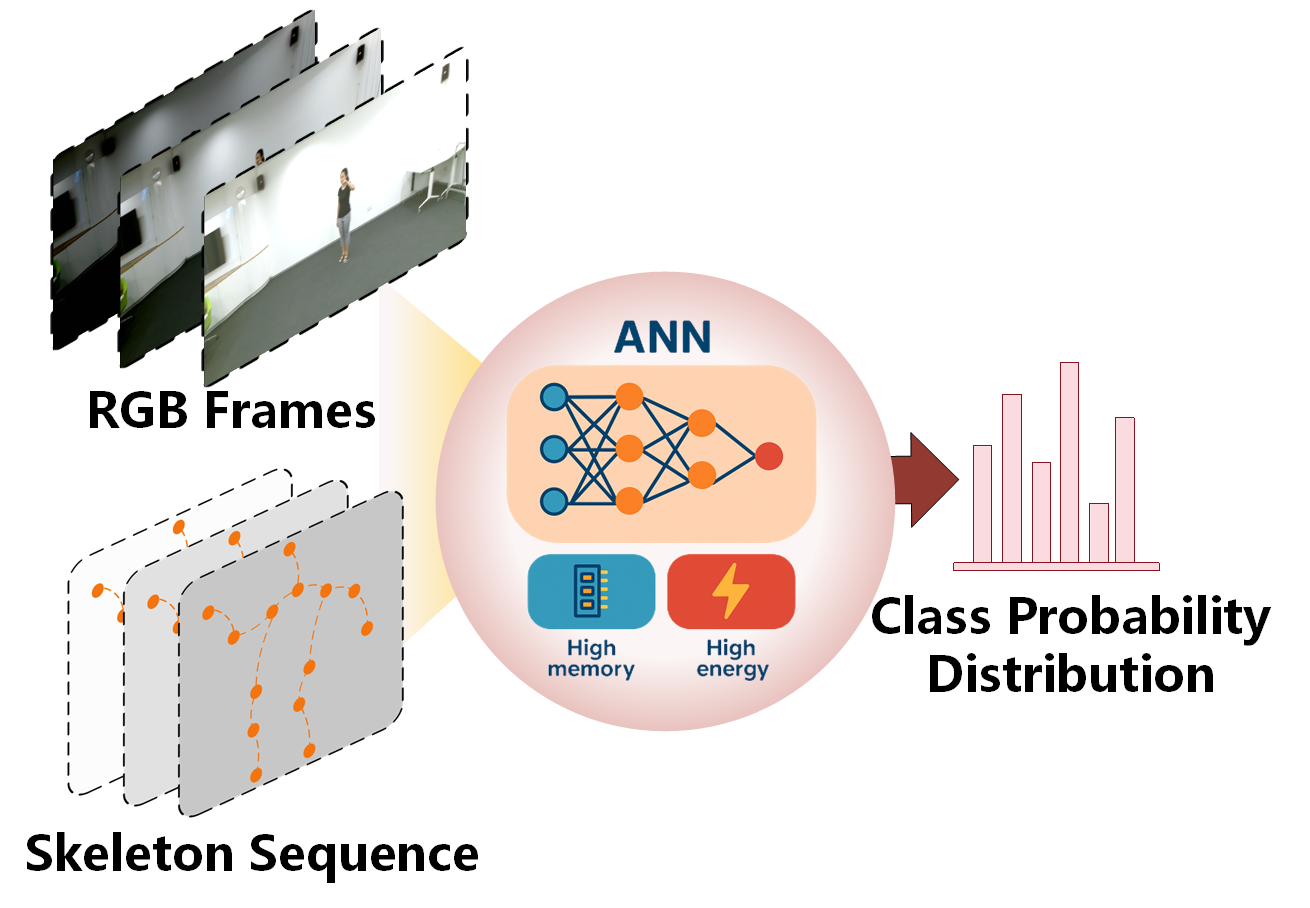
- 现有基于人工神经网络(ANN)的多模态人体行为识别方法计算复杂度高、内存消耗大、能耗高,限制了其在资源受限场景中的应用。
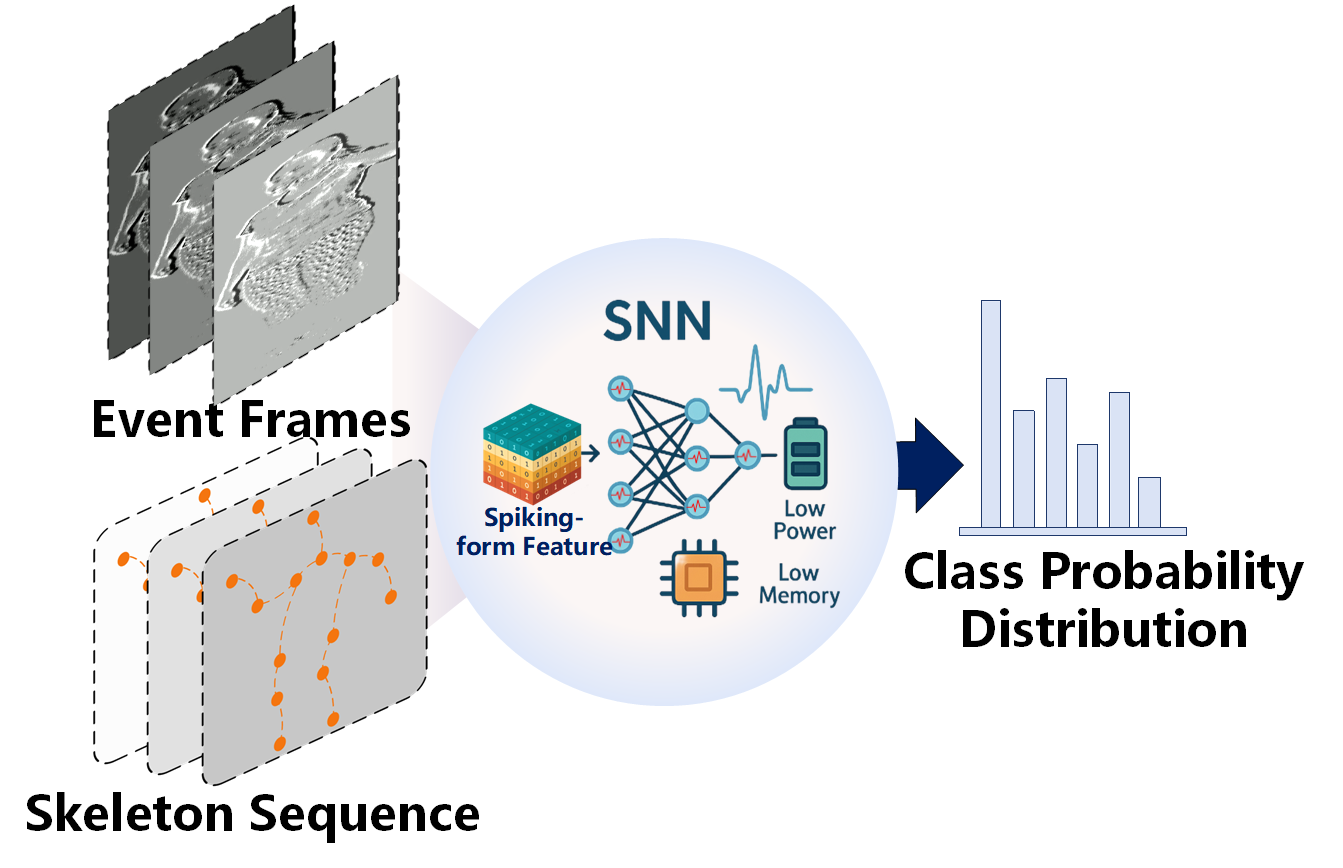
- 论文提出基于SNN的多模态框架,利用事件相机和骨骼数据,设计了新型SNN架构和SNN信息瓶颈机制,实现高效的模态融合。
- 实验结果表明,该方法在识别精度和能效方面均优于现有方法,为实际应用提供了更优选择。
📝 摘要(中文)
本文提出了一种基于脉冲神经网络(SNN)的多模态人体行为识别框架,利用事件相机和骨骼数据。该框架包含两个关键创新:一是新型多模态SNN架构,针对事件相机数据采用基于SNN的Mamba,针对骨骼数据采用脉冲图卷积网络(SGN),并结合脉冲语义提取模块以捕获深层语义表示;二是首创基于SNN的离散信息瓶颈机制用于模态融合,有效平衡了模态特定语义的保留和高效信息压缩。通过构建事件相机和骨骼数据融合的多模态数据集进行验证,实验结果表明该方法在识别精度和能效方面均表现出色,为实际应用提供了有前景的解决方案。
🔬 方法详解
问题定义:现有基于ANN的多模态人体行为识别方法,在计算复杂度、内存消耗和能量需求方面存在显著限制,尤其是在资源受限的环境中。这些限制阻碍了其广泛应用。因此,需要一种更高效、更节能的多模态行为识别方法。
核心思路:论文的核心思路是利用SNN的低功耗特性,以及事件相机和骨骼数据的互补信息,设计一个高效的多模态行为识别框架。通过SNN处理事件相机数据和骨骼数据,并使用信息瓶颈机制进行模态融合,从而在保证识别精度的同时,显著降低计算成本和能耗。
技术框架:该框架主要包含以下几个模块:1) 事件相机数据处理模块:使用基于SNN的Mamba网络提取事件相机数据的时空特征。2) 骨骼数据处理模块:使用脉冲图卷积网络(SGN)提取骨骼数据的结构信息。3) 脉冲语义提取模块:用于捕获两种模态的深层语义表示。4) 基于SNN的离散信息瓶颈模块:用于融合不同模态的信息,同时进行信息压缩,减少冗余。5) 分类器:基于融合后的特征进行行为分类。
关键创新:该论文的关键创新点在于:1) 提出了一个基于SNN的多模态人体行为识别框架,充分利用了SNN的低功耗特性。2) 设计了一个基于SNN的离散信息瓶颈机制,用于高效的模态融合,平衡了信息保留和压缩。3) 提出了一个将事件相机数据和骨骼数据相结合的多模态数据集构建方法,为该领域的研究提供了新的资源。
关键设计:在网络结构方面,SNN-Mamba和SGN的具体结构需要根据数据集和任务进行调整。信息瓶颈模块的关键在于设计合适的离散化方法和损失函数,以保证信息压缩的同时,尽可能保留关键信息。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了所提出的SNN驱动的多模态人体行为识别框架的有效性。实验结果表明,该方法在识别精度和能效方面均优于现有的基于ANN的方法。具体的性能数据(例如,精度提升百分比、能耗降低百分比)和对比基线需要在论文中查找(未知)。该方法为资源受限场景下的多模态行为识别提供了一个有前景的解决方案。
🎯 应用场景
该研究成果可应用于各种资源受限的场景,例如移动机器人、可穿戴设备、智能家居等。在这些场景中,低功耗和高效率是至关重要的。例如,在移动机器人中,可以使用该方法进行实时的人体行为识别,从而实现更智能的人机交互和环境感知。在智能家居中,可以用于监测老年人的活动,及时发现异常情况。
📄 摘要(原文)
Multimodal human action recognition based on RGB and skeleton data fusion, while effective, is constrained by significant limitations such as high computational complexity, excessive memory consumption, and substantial energy demands, particularly when implemented with Artificial Neural Networks (ANN). These limitations restrict its applicability in resource-constrained scenarios. To address these challenges, we propose a novel Spiking Neural Network (SNN)-driven framework for multimodal human action recognition, utilizing event camera and skeleton data. Our framework is centered on two key innovations: (1) a novel multimodal SNN architecture that employs distinct backbone networks for each modality-an SNN-based Mamba for event camera data and a Spiking Graph Convolutional Network (SGN) for skeleton data-combined with a spiking semantic extraction module to capture deep semantic representations; and (2) a pioneering SNN-based discretized information bottleneck mechanism for modality fusion, which effectively balances the preservation of modality-specific semantics with efficient information compression. To validate our approach, we propose a novel method for constructing a multimodal dataset that integrates event camera and skeleton data, enabling comprehensive evaluation. Extensive experiments demonstrate that our method achieves superior performance in both recognition accuracy and energy efficiency, offering a promising solution for practical applications.