Multimodal Mamba: Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
作者: Bencheng Liao, Hongyuan Tao, Qian Zhang, Tianheng Cheng, Yingyue Li, Haoran Yin, Wenyu Liu, Xinggang Wang
分类: cs.CV
发布日期: 2025-02-18 (更新: 2025-03-18)
备注: Code and model are available at https://github.com/hustvl/mmMamba
🔗 代码/项目: GITHUB
💡 一句话要点
提出mmMamba,通过蒸馏将多模态大语言模型转化为线性复杂度的状态空间模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 状态空间模型 知识蒸馏 线性复杂度 视觉语言模型 模型压缩 Mamba Transformer
📋 核心要点
- 现有多模态大语言模型面临计算复杂度高、KV缓存需求大以及依赖独立视觉编码器等部署挑战。
- 通过从现有MLLM中蒸馏知识,将Transformer架构转化为线性复杂度的Mamba架构,无需RNN或视觉编码器。
- 实验表明,mmMamba在速度和内存效率上显著优于Transformer,同时保持了具有竞争力的性能。
📝 摘要(中文)
本文提出mmMamba,一个通过从现有多模态大语言模型(MLLM)中进行渐进式知识蒸馏,从而开发线性复杂度原生多模态状态空间模型的框架。该方法无需预训练的基于RNN的LLM或视觉编码器,即可将训练好的仅解码器MLLM直接转换为线性复杂度架构。论文提出了一种seed策略,从训练好的Transformer中提取Mamba,并设计了一个三阶段蒸馏方案,有效传递Transformer的知识到Mamba,同时保留多模态能力。该方法还支持灵活的混合架构,结合Transformer和Mamba层,以实现可定制的效率-性能权衡。从基于Transformer的仅解码器HoVLE蒸馏得到的mmMamba-linear,在与现有的线性和二次复杂度VLM相比,实现了具有竞争力的性能,而mmMamba-hybrid进一步显著提高了性能,接近HoVLE的能力。在103K tokens下,mmMamba-linear相比HoVLE,实现了20.6倍的速度提升和75.8%的GPU内存减少,而mmMamba-hybrid实现了13.5倍的速度提升和60.2%的内存节省。代码和模型已发布在https://github.com/hustvl/mmMamba。
🔬 方法详解
问题定义:现有Multimodal Large Language Models (MLLMs) 基于Transformer架构,计算复杂度为二次方级别,部署时需要大量的Key-Value缓存,并且通常依赖于单独的视觉编码器。这些因素限制了MLLM在资源受限环境中的应用。
核心思路:论文的核心思路是通过知识蒸馏,将已训练好的Transformer-based MLLM的知识迁移到Mamba架构上。Mamba具有线性复杂度,可以显著降低计算和内存需求。通过精心设计的蒸馏策略,保证知识迁移的同时,保留MLLM的多模态能力。
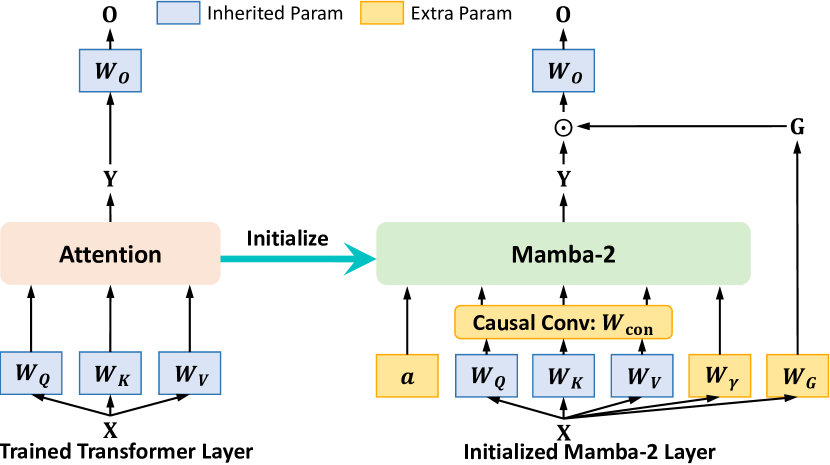
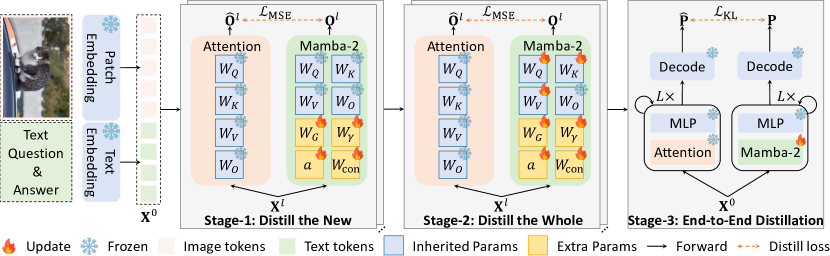
技术框架:mmMamba的整体框架包含三个主要阶段:1) Seeding Mamba from Transformer: 从训练好的Transformer中提取Mamba的初始参数。2) Multimodal Distillation: 使用三阶段蒸馏方案,将Transformer的知识迁移到Mamba,包括特征蒸馏、logits蒸馏和注意力蒸馏。3) Hybrid Architecture: 支持Transformer和Mamba层的混合架构,以实现性能和效率的平衡。
关键创新:最重要的技术创新点在于提出了一种将Transformer-based MLLM直接转换为线性复杂度Mamba架构的蒸馏方法。与现有方法相比,该方法无需预训练的RNN-based LLM或视觉编码器,可以直接利用已有的MLLM资源。此外,三阶段蒸馏方案和混合架构设计也是关键创新。
关键设计:论文提出了一个三阶段蒸馏方案,包括:1) Feature Distillation: 最小化Transformer和Mamba在中间层特征上的差异。2) Logits Distillation: 最小化Transformer和Mamba输出logits的差异。3) Attention Distillation: 最小化Transformer和Mamba注意力分布的差异。此外,混合架构允许灵活配置Transformer和Mamba层的比例,以适应不同的性能和效率需求。
🖼️ 关键图片
📊 实验亮点
mmMamba-linear在103K tokens下,相比于HoVLE,实现了20.6倍的速度提升和75.8%的GPU内存减少。mmMamba-hybrid进一步提升了性能,接近HoVLE的能力,同时仍然实现了13.5倍的速度提升和60.2%的内存节省。这些结果表明mmMamba在效率和性能之间取得了显著的平衡。
🎯 应用场景
mmMamba具有广泛的应用前景,包括移动设备上的多模态应用、低功耗边缘计算设备上的视觉语言任务、以及需要快速响应的实时多模态交互系统。其线性复杂度特性使其能够处理更长的序列,从而支持更复杂的视觉语言推理任务。未来,mmMamba有望成为构建高效、可扩展的多模态人工智能系统的关键技术。
📄 摘要(原文)
Recent Multimodal Large Language Models (MLLMs) have achieved remarkable performance but face deployment challenges due to their quadratic computational complexity, growing Key-Value cache requirements, and reliance on separate vision encoders. We propose mmMamba, a framework for developing linear-complexity native multimodal state space models through progressive distillation from existing MLLMs using moderate academic computational resources. Our approach enables the direct conversion of trained decoder-only MLLMs to linear-complexity architectures without requiring pre-trained RNN-based LLM or vision encoders. We propose an seeding strategy to carve Mamba from trained Transformer and a three-stage distillation recipe, which can effectively transfer the knowledge from Transformer to Mamba while preserving multimodal capabilities. Our method also supports flexible hybrid architectures that combine Transformer and Mamba layers for customizable efficiency-performance trade-offs. Distilled from the Transformer-based decoder-only HoVLE, mmMamba-linear achieves competitive performance against existing linear and quadratic-complexity VLMs, while mmMamba-hybrid further improves performance significantly, approaching HoVLE's capabilities. At 103K tokens, mmMamba-linear demonstrates 20.6$\times$ speedup and 75.8% GPU memory reduction compared to HoVLE, while mmMamba-hybrid achieves 13.5$\times$ speedup and 60.2% memory savings. Code and models are released at https://github.com/hustvl/mmMamba