RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
作者: Hao Gao, Shaoyu Chen, Bo Jiang, Bencheng Liao, Yiang Shi, Xiaoyang Guo, Yuechuan Pu, Haoran Yin, Xiangyu Li, Xinbang Zhang, Ying Zhang, Wenyu Liu, Qian Zhang, Xinggang Wang
分类: cs.CV, cs.RO
发布日期: 2025-02-18 (更新: 2025-10-21)
备注: Code: https://github.com/hustvl/RAD
🔗 代码/项目: GITHUB
💡 一句话要点
RAD:基于大规模3DGS强化学习的端到端自动驾驶策略训练
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 自动驾驶 强化学习 3DGS 模仿学习 闭环训练 虚拟环境 因果关系
📋 核心要点
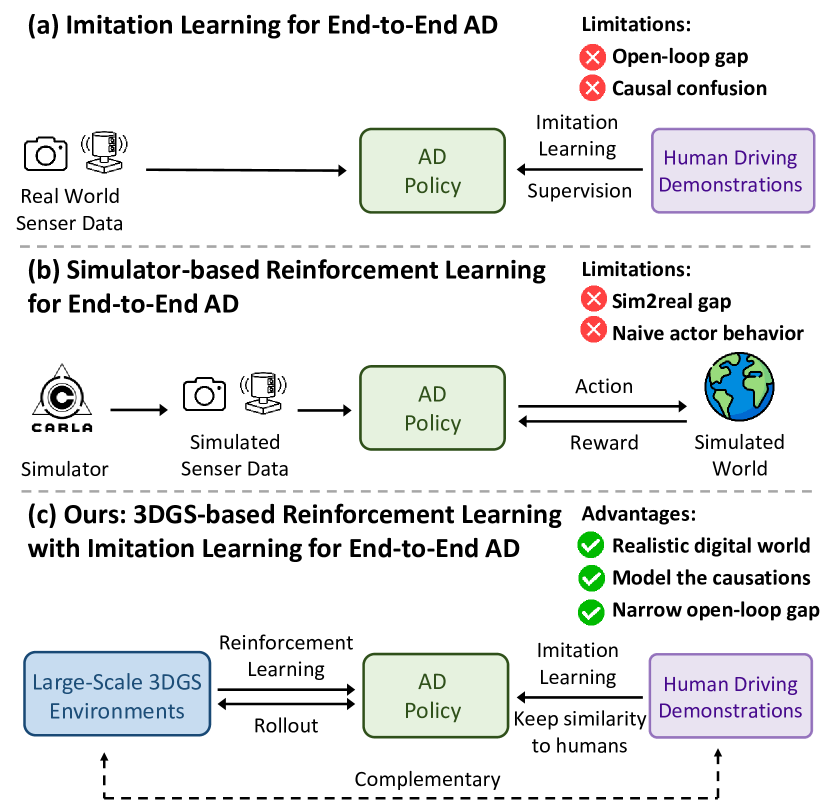
- 现有端到端自动驾驶算法主要依赖模仿学习,面临因果混淆和开环差距等挑战。
- RAD利用3DGS构建逼真环境,结合强化学习探索状态空间,并通过模仿学习正则化策略。
- 实验表明,RAD在闭环测试中显著降低碰撞率,性能优于模仿学习方法。
📝 摘要(中文)
本文提出RAD,一个基于3DGS的闭环强化学习框架,用于端到端自动驾驶。通过利用3DGS技术,构建真实物理世界的照片级数字孪生,使自动驾驶策略能够广泛探索状态空间,并通过大规模试错学习处理分布外场景。为了提高安全性,我们设计了专门的奖励,以指导策略有效地响应安全关键事件并理解真实世界的因果关系。为了更好地与人类驾驶行为对齐,我们将模仿学习作为正则化项纳入强化学习训练中。我们引入了一个由多样化的、先前未见过的3DGS环境组成的闭环评估基准。与基于模仿学习的方法相比,RAD在大多数闭环指标上实现了更强的性能,特别是碰撞率降低了3倍。补充材料中提供了丰富的闭环结果。代码可在https://github.com/hustvl/RAD 获取,以促进未来的研究。
🔬 方法详解
问题定义:现有端到端自动驾驶方法主要依赖模仿学习,但存在因果混淆问题,即模型可能学习到与驾驶决策无关的伪相关性。此外,开环测试与实际驾驶场景存在差距,模型难以应对分布外(OOD)情况。因此,需要一种能够进行闭环训练,并能有效探索和学习真实世界因果关系的自动驾驶策略。
核心思路:RAD的核心思路是利用3DGS技术构建一个逼真的虚拟环境,并在此环境中进行强化学习训练。通过强化学习,智能体可以主动探索环境,学习应对各种驾驶场景,并从错误中学习。同时,结合模仿学习作为正则化项,使智能体的行为更接近人类驾驶员,提高安全性。
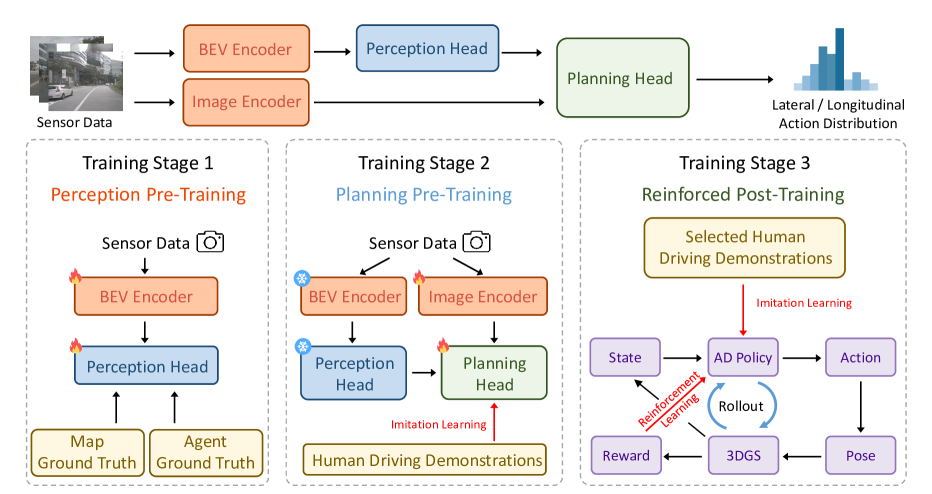
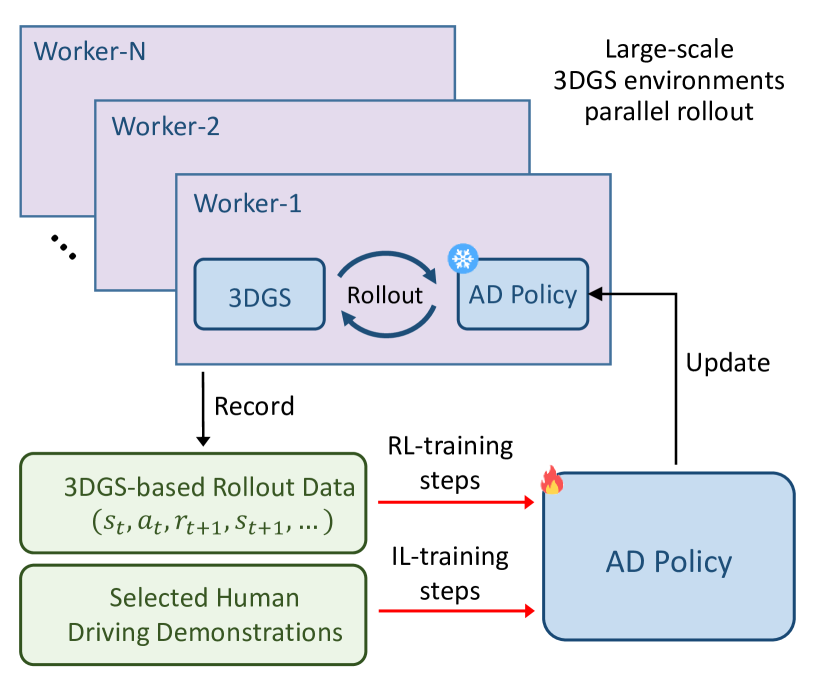
技术框架:RAD框架主要包含以下几个模块:1) 基于3DGS的虚拟环境:提供逼真的视觉输入和物理交互;2) 强化学习智能体:负责根据环境状态采取驾驶动作;3) 奖励函数:引导智能体学习安全和高效的驾驶策略,包含安全奖励和行为对齐奖励;4) 模仿学习模块:利用专家数据对智能体进行正则化,使其行为更接近人类驾驶员。
关键创新:RAD的关键创新在于将3DGS技术与强化学习相结合,构建了一个可用于大规模训练的逼真虚拟环境。这使得智能体能够在安全可控的环境中进行充分的探索,学习应对各种复杂场景。此外,RAD还设计了专门的奖励函数,以引导智能体学习安全驾驶行为,并理解真实世界的因果关系。
关键设计:RAD使用了一种Actor-Critic架构的强化学习算法,Actor网络负责输出驾驶动作,Critic网络负责评估当前状态的价值。奖励函数包含多个部分,包括惩罚碰撞的安全奖励、鼓励速度和效率的奖励,以及模仿学习损失,用于约束智能体的行为。3DGS环境的渲染质量和物理引擎的精度对训练效果至关重要,需要仔细调整。
🖼️ 关键图片
📊 实验亮点
RAD在闭环评估基准上取得了显著的性能提升,与基于模仿学习的方法相比,碰撞率降低了3倍。这表明RAD能够更有效地学习安全驾驶策略,并更好地应对分布外场景。此外,RAD在其他闭环指标上也取得了更好的结果,证明了其在端到端自动驾驶方面的潜力。
🎯 应用场景
RAD的研究成果可应用于自动驾驶系统的开发和测试,尤其是在安全关键场景下的策略优化。通过在虚拟环境中进行大规模训练,可以显著降低自动驾驶系统在真实道路上的事故风险。此外,该方法还可以用于自动驾驶仿真平台的构建,为自动驾驶算法的验证和评估提供更可靠的工具。
📄 摘要(原文)
Existing end-to-end autonomous driving (AD) algorithms typically follow the Imitation Learning (IL) paradigm, which faces challenges such as causal confusion and an open-loop gap. In this work, we propose RAD, a 3DGS-based closed-loop Reinforcement Learning (RL) framework for end-to-end Autonomous Driving. By leveraging 3DGS techniques, we construct a photorealistic digital replica of the real physical world, enabling the AD policy to extensively explore the state space and learn to handle out-of-distribution scenarios through large-scale trial and error. To enhance safety, we design specialized rewards to guide the policy in effectively responding to safety-critical events and understanding real-world causal relationships. To better align with human driving behavior, we incorporate IL into RL training as a regularization term. We introduce a closed-loop evaluation benchmark consisting of diverse, previously unseen 3DGS environments. Compared to IL-based methods, RAD achieves stronger performance in most closed-loop metrics, particularly exhibiting a 3x lower collision rate. Abundant closed-loop results are presented in the supplementary material. Code is available at https://github.com/hustvl/RAD for facilitating future research.