L4P: Towards Unified Low-Level 4D Vision Perception
作者: Abhishek Badki, Hang Su, Bowen Wen, Orazio Gallo
分类: cs.CV
发布日期: 2025-02-18 (更新: 2025-10-02)
💡 一句话要点
提出L4P以统一解决低级4D视觉感知问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 低级视觉感知 4D视觉 通用架构 视频编码 多任务学习
📋 核心要点
- 现有低级4D视觉感知方法通常依赖于专用架构,缺乏通用性,难以同时处理多种任务。
- L4P通过结合预训练的ViT视频编码器和轻量级任务头,提出了一种通用的前馈架构,能够在统一框架下解决多种感知任务。
- 实验结果表明,L4P在多个密集和稀疏任务上表现出色,且处理速度与单任务方法相当。
📝 摘要(中文)
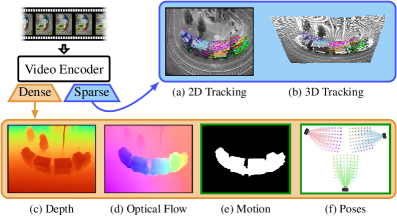
视频像素之间的时空关系对于低级4D感知任务至关重要。现有方法通常依赖于针对特定任务的专用架构,限制了其通用性。本文提出L4P,一个前馈的通用架构,能够在统一框架下解决多种低级4D感知任务。L4P利用预训练的基于ViT的视频编码器,并结合轻量级的任务头,避免了大量训练的需求。尽管其设计通用且前馈,L4P在深度估计和光流估计等密集任务,以及2D/3D跟踪等稀疏任务上,与现有专用方法竞争力强,并且能够在与单任务方法相当的时间内同时解决所有任务。
🔬 方法详解
问题定义:本文旨在解决低级4D视觉感知任务的通用性问题。现有方法通常针对特定任务设计,导致无法有效处理多种任务,且训练成本高。
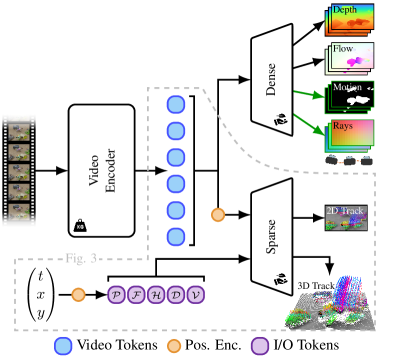
核心思路:L4P的核心思想是构建一个通用的前馈架构,利用预训练的ViT视频编码器,结合轻量级的任务头,使得模型能够在统一框架下高效解决多种低级4D感知任务。
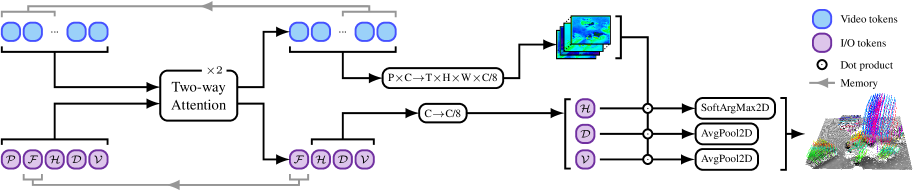
技术框架:L4P的整体架构包括一个ViT视频编码器作为特征提取模块,后接多个轻量级的任务头,分别负责不同的感知任务。该架构设计旨在减少训练时间和计算资源的消耗,同时保持高效的性能。
关键创新:L4P的主要创新在于其通用性和前馈设计,使其能够在多个任务上进行有效推理,而不需要为每个任务单独训练复杂的模型。这一设计与现有专用方法形成鲜明对比。
关键设计:L4P采用了预训练的ViT作为基础网络,任务头设计为轻量级结构,确保在保持性能的同时,减少了训练和推理的复杂度。损失函数的选择也经过精心设计,以适应多任务学习的需求。
🖼️ 关键图片
📊 实验亮点
实验结果显示,L4P在深度估计和光流估计等密集任务上,与现有专用方法相比,性能相当,同时在2D/3D跟踪等稀疏任务上也展现出优越性。L4P能够在与单任务方法相当的时间内,完成所有任务的处理,显示出其高效性。
🎯 应用场景
L4P的研究成果在多个领域具有广泛的应用潜力,包括自动驾驶、视频监控、增强现实和机器人导航等。通过提供一个统一的框架,L4P能够简化多任务学习的过程,提高系统的整体效率和响应速度,推动相关技术的发展。
📄 摘要(原文)
The spatio-temporal relationship between the pixels of a video carries critical information for low-level 4D perception tasks. A single model that reasons about it should be able to solve several such tasks well. Yet, most state-of-the-art methods rely on architectures specialized for the task at hand. We present L4P, a feedforward, general-purpose architecture that solves low-level 4D perception tasks in a unified framework. L4P leverages a pre-trained ViT-based video encoder and combines it with per-task heads that are lightweight and therefore do not require extensive training. Despite its general and feedforward formulation, our method is competitive with existing specialized methods on both dense tasks, such as depth or optical flow estimation, and sparse tasks, such as 2D/3D tracking. Moreover, it solves all tasks at once in a time comparable to that of single-task methods.