Contrast-Unity for Partially-Supervised Temporal Sentence Grounding
作者: Haicheng Wang, Chen Ju, Weixiong Lin, Chaofan Ma, Shuai Xiao, Ya Zhang, Yanfeng Wang
分类: cs.CV
发布日期: 2025-02-18
备注: Accepted by ICASSP 2025.The first two authors share the same contribution. arXiv admin note: text overlap with arXiv:2302.09850
💡 一句话要点
提出Contrast-Unity框架,解决部分监督时序语句定位问题,降低标注成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序语句定位 部分监督学习 对比学习 伪标签 视频理解
📋 核心要点
- 现有全监督时序语句定位方法依赖大量标注数据,成本高昂;弱监督方法性能不佳。
- 提出Contrast-Unity框架,通过对比学习和伪标签训练,充分利用部分标注信息,实现隐式-显式渐进式定位。
- 在Charades-STA和ActivityNet Captions数据集上,实验结果表明该方法在部分监督设置下表现优异。
📝 摘要(中文)
本文针对时序语句定位任务,旨在以较低的标注成本实现高性能。现有全监督方法效果好但标注昂贵,弱监督方法标注便宜但性能差。为此,本文提出一种中间状态的部分监督设置,即训练期间仅提供短片段标注。为了充分利用部分标签,设计了一个对比-统一框架,采用隐式-显式两阶段渐进式定位目标。在隐式阶段,使用四元组对比学习(事件-查询聚集、事件-背景分离、簇内紧凑性和簇间可分性)在细粒度上对齐事件-查询表示,从而获得高质量的表示,并产生可接受的伪标签。在显式阶段,使用获得的伪标签训练一个全监督模型,以显式地优化定位目标,进行定位细化和去噪。在Charades-STA和ActivityNet Captions上的大量实验和消融研究证明了部分监督的意义以及本文方法的优越性能。
🔬 方法详解
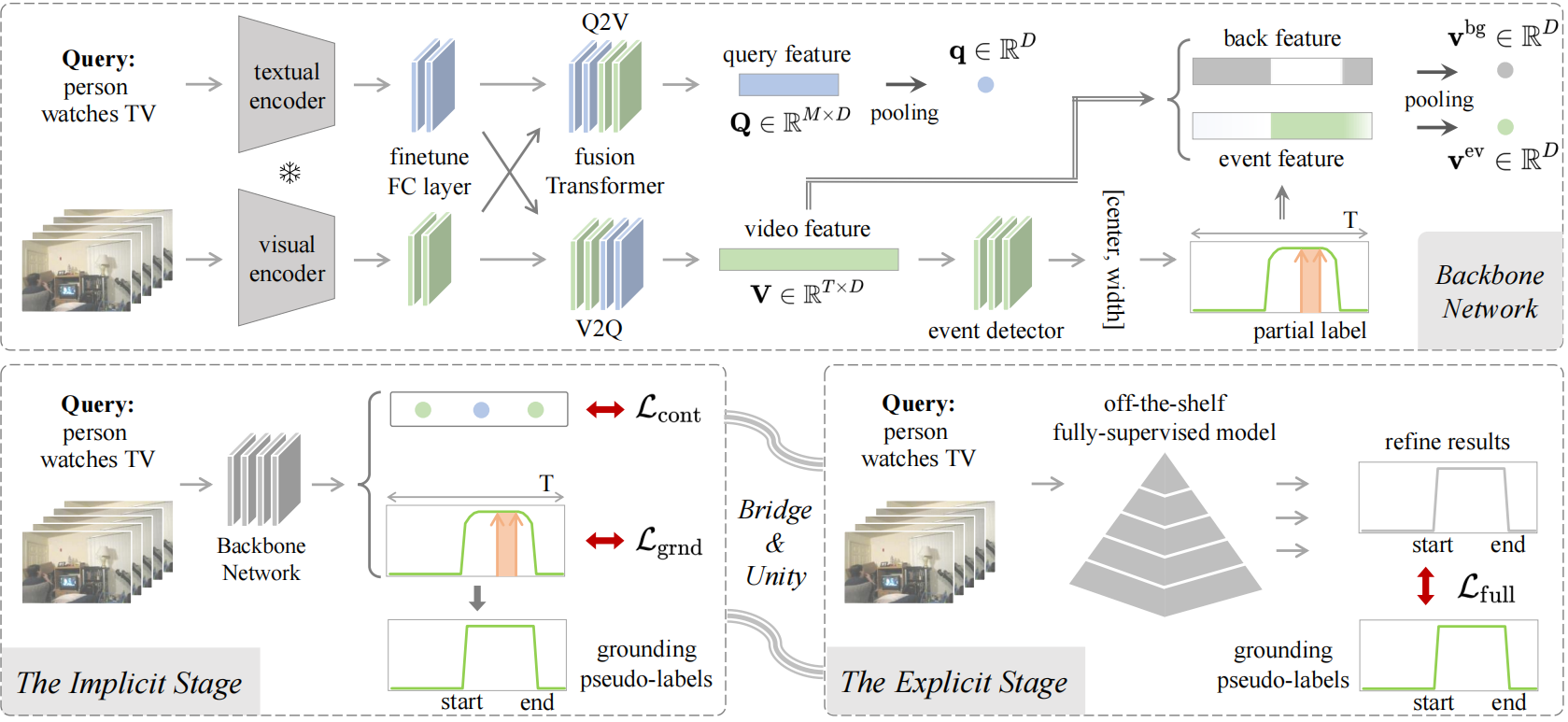
问题定义:时序语句定位旨在从给定的未分割视频中检测出自然语言查询所描述的事件时间戳。现有方法要么需要大量的全监督标注,成本高昂,要么采用弱监督,性能较差。本文旨在解决在部分监督场景下,即只标注视频中的短片段,如何高效地进行时序语句定位的问题。
核心思路:本文的核心思路是利用部分标注信息,通过对比学习提升视频片段和文本查询的表示质量,并生成伪标签,然后利用伪标签进行全监督训练,从而实现高性能的定位。这种隐式-显式两阶段的方法,可以有效地利用有限的标注信息,并逐步提升定位精度。
技术框架:Contrast-Unity框架包含两个主要阶段:隐式阶段和显式阶段。在隐式阶段,使用四元组对比学习来对齐事件-查询表示,包括事件-查询聚集、事件-背景分离、簇内紧凑性和簇间可分性。在显式阶段,使用隐式阶段生成的伪标签训练一个全监督模型,以优化定位目标,进行定位细化和去噪。
关键创新:本文的关键创新在于提出了一个对比-统一框架,该框架能够有效地利用部分监督信息,通过对比学习提升表示质量,并生成高质量的伪标签。四元组对比学习的设计,能够更全面地学习事件和查询之间的关系,从而提升表示的区分性。
关键设计:在隐式阶段,四元组对比学习损失函数的设计是关键。该损失函数包含四个部分:事件-查询聚集损失,用于拉近相关事件和查询的距离;事件-背景分离损失,用于推开事件和背景的距离;簇内紧凑性损失,用于使同一事件的表示更加紧凑;簇间可分性损失,用于使不同事件的表示更加可分。在显式阶段,使用交叉熵损失函数来优化定位目标。
🖼️ 关键图片
📊 实验亮点
在Charades-STA和ActivityNet Captions数据集上的实验结果表明,本文提出的Contrast-Unity框架在部分监督设置下取得了显著的性能提升。相较于现有的弱监督方法,该方法在定位精度上有明显的优势,证明了部分监督的有效性和本文方法的优越性。
🎯 应用场景
该研究成果可应用于视频内容理解、智能视频监控、人机交互等领域。例如,在智能视频监控中,可以根据用户的自然语言描述快速定位到视频中的特定事件,提高监控效率。在人机交互中,可以实现更自然、更智能的视频检索和浏览。
📄 摘要(原文)
Temporal sentence grounding aims to detect event timestamps described by the natural language query from given untrimmed videos. The existing fully-supervised setting achieves great results but requires expensive annotation costs; while the weakly-supervised setting adopts cheap labels but performs poorly. To pursue high performance with less annotation costs, this paper introduces an intermediate partially-supervised setting, i.e., only short-clip is available during training. To make full use of partial labels, we specially design one contrast-unity framework, with the two-stage goal of implicit-explicit progressive grounding. In the implicit stage, we align event-query representations at fine granularity using comprehensive quadruple contrastive learning: event-query gather, event-background separation, intra-cluster compactness and inter-cluster separability. Then, high-quality representations bring acceptable grounding pseudo-labels. In the explicit stage, to explicitly optimize grounding objectives, we train one fully-supervised model using obtained pseudo-labels for grounding refinement and denoising. Extensive experiments and thoroughly ablations on Charades-STA and ActivityNet Captions demonstrate the significance of partial supervision, as well as our superior performance.